Predicating Predictivity
Plus predicaments of error modeling
 |
| Cropped from Bacon Sandwich source |
Sir David Spiegelhalter is a British statistician. He is a strong voice for the public understanding of statistics. His work extends to all walks of life, including risk, coincidences, murder, and sex.
Today we talk about extending one of his inventions.
His invention has to do with grading the performance of people and models that make predictions. A scoring rule grades how often predictions are right. But it may not tell how difficult the situations are. It is easy to look good with predictions when they start with a high chance of success. A weather forecaster predicting sunny-versus-rainy will be right more often in Las Vegas than in Boston. Quoting this FiveThirtyEight item:
If you want to have an easy life as a weather forecaster, you should get a job in Las Vegas, Phoenix or Los Angeles. Predict that it won’t rain in one of those cities, and you’ll be right about 90 percent of the time.
In a 1986 paper, for a particular scoring rule defined by Glenn Brier in 1950, Spiegelhalter worked out how to equalize the forecaster grading. He applied his Z-test not to weather as Brier was concerned with but to medical prognoses and clinical trials.
What I am doing with a small group of graduate students in Buffalo is trying to turn Spiegelhalter’s kind of Z-test around once more. If a forecaster fares poorly, we will try to flag not the model but the behavior of the subjects being modeled. In weather we would want to tell when Mother Nature, not the models, has gone off the rails. Well, we are actually looking for ways to tell when a human being has left the bounds of human predictability for reasons that are inhuman—such as cheating with a computer at chess. And maybe it can shed more light on whether our computers can possibly “cheat” with quantum mechanics.
Prediction Scores
Let’s consider situations 


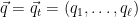

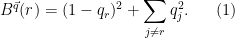
If the forecaster was certain that 
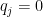
If you put probability 

Then 

We would like our forecasts always to be perfect, but reality gives us situations that are inherently nondeterministic—with unknown “true probabilities” 

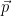
![\displaystyle \begin{array}{rcl} \mathsf{E}_{\vec{p}}[B^{\vec{q}}] &=& \sum_{i=1}^\ell p_i B^{\vec{q}}(i)\\ &=& \sum_{i=1}^\ell p_i (1 - 2q_i + Q)\\ &=& 1 + Q - 2\sum_{i=1}^\ell p_i q_i. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%5Cmathsf%7BE%7D_%7B%5Cvec%7Bp%7D%7D%5BB%5E%7B%5Cvec%7Bq%7D%7D%5D+%26%3D%26+%5Csum_%7Bi%3D1%7D%5E%5Cell+p_i+B%5E%7B%5Cvec%7Bq%7D%7D%28i%29%5C%5C+%26%3D%26+%5Csum_%7Bi%3D1%7D%5E%5Cell+p_i+%281+-+2q_i+%2B+Q%29%5C%5C+%26%3D%26+1+%2B+Q+-+2%5Csum_%7Bi%3D1%7D%5E%5Cell+p_i+q_i.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
This is uniquely minimized by setting 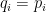


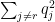

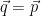
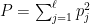

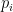


A second example, the log-likelihood prediction scoring rule, is in the original longer draft of this post.
Spiegelhalter’s Z
Spiegelhalter’s 
![\displaystyle \mathsf{Z}[B] = \frac{B - \mathsf{E}[B]}{\sqrt{\mathsf{Var}[B]}},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathsf%7BZ%7D%5BB%5D+%3D+%5Cfrac%7BB+-+%5Cmathsf%7BE%7D%5BB%5D%7D%7B%5Csqrt%7B%5Cmathsf%7BVar%7D%5BB%5D%7D%7D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
where ![{\mathsf{Var}[B]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BVar%7D%5BB%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\mathsf{E}_{\vec{p}}[B^2] - (\mathsf{E}_{\vec{p}}[B])^2}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BE%7D_%7B%5Cvec%7Bp%7D%7D%5BB%5E2%5D+-+%28%5Cmathsf%7BE%7D_%7B%5Cvec%7Bp%7D%7D%5BB%5D%29%5E2%7D&bg=ffffff&fg=000000&s=0&c=20201002)
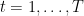

![\displaystyle \mathsf{Z}_{\vec{p}}[B^{\vec{q}}] = \frac{\sum_{t=1}^T B^{\vec{q}_t}(r_t) - \mathsf{E}_{\vec{p}_t}[B^{\vec{q}_t}]}{\sqrt{\sum_{t=1}^T \mathsf{Var}_{\vec{p}_t}[B^{\vec{q}_t}]}}. \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathsf%7BZ%7D_%7B%5Cvec%7Bp%7D%7D%5BB%5E%7B%5Cvec%7Bq%7D%7D%5D+%3D+%5Cfrac%7B%5Csum_%7Bt%3D1%7D%5ET+B%5E%7B%5Cvec%7Bq%7D_t%7D%28r_t%29+-+%5Cmathsf%7BE%7D_%7B%5Cvec%7Bp%7D_t%7D%5BB%5E%7B%5Cvec%7Bq%7D_t%7D%5D%7D%7B%5Csqrt%7B%5Csum_%7Bt%3D1%7D%5ET+%5Cmathsf%7BVar%7D_%7B%5Cvec%7Bp%7D_t%7D%5BB%5E%7B%5Cvec%7Bq%7D_t%7D%5D%7D%7D.+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
The denominator presumes that the forecast situations are independent so that the variances add. The numerator expands to be
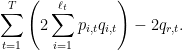
The original application is a confidence test of the “null hypothesis” that the projections 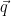

![\displaystyle \mathsf{Z}_{\vec{q}}[B^{\vec{q}}] = 2\frac{\sum_{t=1}^T \left(\sum_{i=1}^{\ell_t} q_{i,t}^2 \right) - q_{r,t}}{\sqrt{\sum_{t=1}^T \mathsf{Var}_{\vec{q}_t}[B^{\vec{q}_t}]}}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathsf%7BZ%7D_%7B%5Cvec%7Bq%7D%7D%5BB%5E%7B%5Cvec%7Bq%7D%7D%5D+%3D+2%5Cfrac%7B%5Csum_%7Bt%3D1%7D%5ET+%5Cleft%28%5Csum_%7Bi%3D1%7D%5E%7B%5Cell_t%7D+q_%7Bi%2Ct%7D%5E2+%5Cright%29+-+q_%7Br%2Ct%7D%7D%7B%5Csqrt%7B%5Csum_%7Bt%3D1%7D%5ET+%5Cmathsf%7BVar%7D_%7B%5Cvec%7Bq%7D_t%7D%5BB%5E%7B%5Cvec%7Bq%7D_t%7D%5D%7D%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
To illustrate, suppose we do ten independent trials of an event with four outcomes whose true probabilities are 

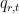

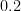
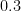
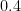

![{\mathsf{Z}_{\vec{q}}[B^{\vec{q}}] = 0}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BZ%7D_%7B%5Cvec%7Bq%7D%7D%5BB%5E%7B%5Cvec%7Bq%7D%7D%5D+%3D+0%7D&bg=ffffff&fg=000000&s=0&c=20201002)


A high
Our idea is the opposite. Suppose we know that the forecasts are true, or suppose they have biases that are known and correctable over moderately large data sets. We may then be able to fit ![{\mathsf{Z}[B]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BZ%7D%5BB%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Why This Z?
As I have detailed in numerous posts on this blog, my system for detecting cheating with computers at chess already provides several statistical
The motive involves the presence of multiple strong chess-playing programs, each with its own quirks and distribution of values for moves. They are used in two different ways:
-
As inputs telling the relative values
of moves
, which my model converts into its probability projections
.
- As output predicates telling how often the player chose the move recommended by a specific program and/or quantifying the magnitude of error for different played moves.
Having multiple engines helps point 1. My intent to blend the values
Nevertheless, my results often vary between testing engines. The engines compete against each other and may be crafted to disagree on certain kinds of moves. They agree with each other barely 75–80% in my tests. I would like to factor these differences out.
The Spiegelhalter
The Method
To harness ![{\mathsf{Z}[F]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BZ%7D%5BF%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

We postulate an original source of error terms 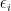


-
,
-
,
-
,
-
,
-
,
-
.
There are further forms to consider and it is not yet clear from data within my model which one most applies. We would be interested in examples where these representations have been employed and in observations about their natures.
Given the error terms, we can write each 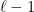
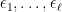




![{\mathsf{Z}_{\vec{q},\vec{\epsilon}}[F]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BZ%7D_%7B%5Cvec%7Bq%7D%2C%5Cvec%7B%5Cepsilon%7D%7D%5BF%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
-
Substitute the terms with
for each free
.
-
Compute the expectation over
for the numerator and denominator of (2), separately.
-
Holding the other previously-fitted model parameters in place, fit
, so
If the resulting 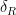
Error Quirks and Queries
To see a key wrinkle, consider the first error form. It is symmetrical: 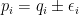

![{\mathsf{E}_{\epsilon_i \sim \mathcal{N}(0,\delta^2)}[\cdots]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BE%7D_%7B%5Cepsilon_i+%5Csim+%5Cmathcal%7BN%7D%280%2C%5Cdelta%5E2%29%7D%5B%5Ccdots%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

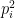

In the second form, however, we get 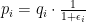


Under normal expectation, the odd-power terms drop out (so their signs don’t matter) and we get
![\displaystyle \mathsf{E}_{\epsilon_i \sim \mathcal{N}(0,\delta^2)}[q_i(1 - \epsilon_i + \epsilon_i^2 - \epsilon_i^3 + \epsilon_i^4)] = q_i(1 + \delta^2 + 3\delta^4).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathsf%7BE%7D_%7B%5Cepsilon_i+%5Csim+%5Cmathcal%7BN%7D%280%2C%5Cdelta%5E2%29%7D%5Bq_i%281+-+%5Cepsilon_i+%2B+%5Cepsilon_i%5E2+-+%5Cepsilon_i%5E3+%2B+%5Cepsilon_i%5E4%29%5D+%3D+q_i%281+%2B+%5Cdelta%5E2+%2B+3%5Cdelta%5E4%29.+&bg=ffffff&fg=000000&s=0&c=20201002)
This credits
Already, however, we have traipsed over some pitfalls of methodology. One is that the normal expectation
![\displaystyle \mathsf{E}_{\epsilon \sim \mathcal{N}(0,\delta^2)}[\frac{1}{1+\epsilon}] = +\infty,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathsf%7BE%7D_%7B%5Cepsilon+%5Csim+%5Cmathcal%7BN%7D%280%2C%5Cdelta%5E2%29%7D%5B%5Cfrac%7B1%7D%7B1%2B%5Cepsilon%7D%5D+%3D+%2B%5Cinfty%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
regardless of how small 
is an unbiased estimator of
, but
A third curiosity comes from the fourth error form. It gives 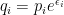

![\displaystyle \mathsf{E}_{\epsilon \sim \mathcal{N}(0,\delta^2)}[e^{b\epsilon}] = e^{0.5b^2 \delta^2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathsf%7BE%7D_%7B%5Cepsilon+%5Csim+%5Cmathcal%7BN%7D%280%2C%5Cdelta%5E2%29%7D%5Be%5E%7Bb%5Cepsilon%7D%5D+%3D+e%5E%7B0.5b%5E2+%5Cdelta%5E2%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
exactly, without approximation. Again the sign of
![\displaystyle \mathsf{E}_{\vec{\epsilon}}[p_i] = q_i e^{0.5\delta^2} > q_i.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathsf%7BE%7D_%7B%5Cvec%7B%5Cepsilon%7D%7D%5Bp_i%5D+%3D+q_i+e%5E%7B0.5%5Cdelta%5E2%7D+%3E+q_i.+&bg=ffffff&fg=000000&s=0&c=20201002)
But by the original fourth equation we get
![\displaystyle \mathsf{E}_{\vec{\epsilon}}[q_i] = p_i e^{0.5\delta^2} > p_i.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathsf%7BE%7D_%7B%5Cvec%7B%5Cepsilon%7D%7D%5Bq_i%5D+%3D+p_i+e%5E%7B0.5%5Cdelta%5E2%7D+%3E+p_i.+&bg=ffffff&fg=000000&s=0&c=20201002)
So we have ![{\mathsf{E}[q_i] > p_i}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BE%7D%5Bq_i%5D+%3E+p_i%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\mathsf{E}[p_i] > q_i}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BE%7D%5Bp_i%5D+%3E+q_i%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Open Problems
Have you seen this idea of directly testing (un)predictability in the literature? Might it improve the currently much-debated statistical tests for quantum supremacy?
Which error model seems most likely to apply? Where have the paradoxes in our last section been noted? Update 1/20: The answer appears to be error model 5 with the Brier score but zeroing the weight of the best move, after runs in the past month on data obtained via UB’s Center for Computational Research (CCR).
[some wording tweaks, added update]


{kind=link}
gib er ish