The New Chess World Champion
Available for $59.96, or—for free?

|
|
chessprogramming wiki source |
Larry Kaufman is a Grandmaster of chess, and has teamed in the development of two champion computer chess programs, Rybka and Komodo. I have known him from chess tournaments since the 1970s. He earned the title of International Master (IM) from the World Chess Federation in 1980, a year before I did. He earned his GM title in 2008 by dint of winning the World Senior Chess Championship, equal with GM Mihai Suba.
Today we salute Komodo for winning the 7th Thoresen Chess Engines Competition (TCEC), which some regard as the de-facto world computer chess championship.
Kaufman first worked on the Rybka chess program with its originator, Vasik Rajlich. In 2008 his manner of tuning the evaluation function by field testing helped create a big leap in strength from version 2.3.1 to version 3 of Rybka. Hence Rybka 3 became the clear choice of master engine for my statistical model.
After two years of silicon hiatus, Kaufman teamed with Komodo’s originator, the late Don Dailey (joined later by Mark Lefler), and they brought out their first commercial version in 2011, by which time it had at least pulled even with Rybka. Since then computer chess has seen a triumvirate joined by the commercial engine Houdini by Robert Houdart, and the free open-source engine Stockfish by Tord Romstad, Marco Costalba, and Joona Kiiski. The current CCRL rating list shows their most recent public versions atop the list:

The last column is CCRL’s confidence in superiority over the next engine on the list. This was borne out by all four engines surviving to the TCEC 7 semifinal stage and finishing in that order. Previously Houdini ruled TCEC through mid-2013, then Komodo won TCEC 5 over Stockfish a year ago, and Stockfish got revenge in TCEC 6 last May. The current final between the latest versions was a squeaker, with Komodo ahead by one point until getting two late wins to finish 33.5–30.5.
Human Depth of Games
Kaufman and I have had closely similar chess ratings for four decades. However, in the last game we played he gave me odds of rook and bishop and beat me handily. Then he told me that the world champion could probably beat him giving the same odds.
This was not Western chess, where I would be pretty confident of beating anyone given just an extra bishop. It was Japanese chess, called Shogi. Shogi has no piece with the power of a queen, and the armies have just one rook and bishop each, so the odds I received were maximal. The main difference from Western chess is that captured pieces become their taker’s property and can be “paratrooped” back into the game. This prevents the odds receiver from winning by attrition through exchanges as prevails in chess, and throws upon the leader a burden of attack.
It also makes Shogi deeper than chess in a way that can be defined mathematically. Say two players are a class unit apart if the stronger expects to score 75% against the weaker in a match. In chess, this corresponds to a difference of almost exactly 200 points in the standard Elo rating system. László Mérő, in his 1990 book Ways of Thinking, called the number of class units from a typical beginning adult player to the human world champion the depth of a game.
Tic-tac-toe may have a depth of 1: if you assume a beginner knows to block an immediate threat of three-in-a-row but plays randomly otherwise, then you can score over 75% by taking a corner when you go first and grifting a few games when you go second. Another school-recess game, dots-and-boxes, is evidently deeper. We don’t know its depth for sure because it doesn’t have a rating system and championship format like chess does.
Chess ratings in the US go all the way down to the formal floor of 100 among scholastic players, but I concur with the estimate of Elo 600 for a young-adult beginner by a discussion of Mérő’s book which I saw in the 1990s but did not preserve. This gave chess a depth of 11 class units up to 2800, which was world champion Garry Kasparov’s rating in 1990. If I recall correctly, checkers (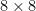
Game Depth and Moore’s Law
One weakness in the notion of depth is dependence on how contests are aggregated. For tennis, should we apply 75% expectation to games, pairs of games, sets, or matches—and how many games in a set or sets in a match? Another is that any game can be ‘reduced’ to depth 1 by flipping a coin; if heads the game is played as-usual; if tails a second coin flip defines the outcome. Then nobody ever has more than 75% expectation. I regard both as beside the point for most board games, but both become nontrivial for games like backgammon that involve chance and are played with match stakes.
Although it is coming on 18 years since Deep Blue beat Kasparov, humans are still barely fending off computers at shogi, while we retain some breathing room at Go. Since depth 14 translates to Elo 3400 on the chess scale, while Komodo 8 is scraping 3300 on several chess rating lists, This feels about right.
Ten years ago, each doubling of speed was thought to add 50 Elo points to strength. Now the estimate is closer to 30. Under the double-in-2-years version of Moore’s Law, using an average of 50 Elo gained per doubling since Kasparov was beaten, one gets 450 Elo over 18 years, which again checks out.
To be sure, the gains in computer chess have come from better algorithms not just speed, and include nonlinear jumps, so Go should not count on a cushion of (25 – 14)*9 = 99 years. That Moore’s Law has recently gone more toward processor core density than raw CPU speed, while chess programs gain only about 60–65% from each doubling of cores, contributes more offsetting factors. Nevertheless, Mérő’s notion of depth in games gives a new angle on computational progress.
Patterns and Singularity
Can we design games to be more human-friendly and computer-resistant? Both Shogi and Go are overtly more complex than chess by certain measures of numbers of possible positions and typical lengths of games. There are versions of chess and Shogi with bigger boards, which Kaufman once compared in an informative forum post. However, I agree with various people’s opinions that raw complexity taxes carbon and silicon equally while these factors do the most to sway between them:
- The horizon of tactical sequences;
- The weight of tactics in furthering longer-term strategy;
- The number of reasonable moves in typical positions, which quantifies the effective branching factor of the search tree.
Chess scores poorly for brains by all three: Tactics are often short firecracker strings that can dazzle human players but are now trivial for computers. Common advice for beginning players is to flash-study tactics. Chess teacher Dan Heisman once said:
It’s not that chess is 99% tactics, it’s just that tactics takes up 99% of your time.
I equate the “tactical” nature of a chess position with the degree to which the best move stands apart from any other, which relates in turn to the effective branching factor. My statistical model stamps a definite percentage number: not “99%” but a hefty 53.3% in typical human games. Computers playing each other tend to reach positions whose lower 49% figure I interpret as greater freedom of strategy. The difference from 53.3% is statistically significant, but it’s still almost 50%.
The new game Arimaa achieves greatly higher branching factor by longer tactical horizons and by “moves” that consist of four separate motions. Human players are still comfortably defending a $12,000 prize with six years to run. Although I have not yet been able to produce comparable analysis of Arimaa, I suspect that its first-move “singularity” measure will be under 10%. Keeping closer to standard chess, my best effort involves doubling up the pawns, which are the game’s strategic “soul.”
More broadly, I agree with the contention of the BBC/National Geographic documentary “My Brilliant Brain” featuring Susan Polgar that human skill consists most in pattern matching from previously seen positions, as Dick and I discussed in this post. Not even Komodo or Stockfish includes a pattern classifier. Does there exist a succinct machine-learning style distinguisher that always steers to advantageous positions? (Added 12/30: Neural networks trained on human professional games of Go recently leaped toward this.) If so, then more than the fall of Garry or the current desperate defenses of Mt. Shogi and Mt. Go, we may speak of the “Singularity” invading our brains.
Skill and Rating Horizons
Related to diminishing returns from higher speed is the high incidence of draws in top-level chess, well over 50%. This compares to a rate under 2% for Shogi, as also noted by Kaufman, while Go tournaments include rules that make draws impossible.
Computers are not immune: Only 11 of 64 games in the TCEC final were decisive, and all of them were won by White. Some games became rooftop swordfights in which human players would surely topple over the parapet, but the windows of the engines’ own analyses 15 or more moves ahead on the official site often showed tether wires locking both into a safely drawn outcome. In game 59, Komodo played for twenty moves a full rook down but felt no urgency to push its compensating pawns further and in truth was never close to losing. Only 28 of 72 games in the penultimate stage were decisive, only 6 won by Black.
If a human 2800 player can achieve just one draw out of 50 games against an engine, then by the mathematics of the rating system, the engine’s rating cannot go over 3600. To reach 4000 against humans, a program would have to concede a draw but once in 500 games.
This logic applies with even greater force to programs playing each other. Perhaps Komodo and Stockfish are already strong enough to hold a draw at least once in 5 games against any player. Then the ceiling for any player—without needing to define a ‘perfect’ player—is under 3700.
A Little Game Theory
Even for games with negligible human draw rate, once can still infer an effective rating horizon by considering players that randomize their move choices. If there is no succinct perfect deterministic strategy for chess, this means any such strategy 
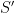

My statistical chess model is set up to provide exactly this kind of rating estimation. It defines an ensemble over skill parameters 




The mapping from
Regardless, 3300 is plenty high, almost 450 points better than any brain alive, and you can have it at your fingertips. On your laptop or smartphone you would get maybe only 100–250 points lower. It will cost under $60 for the champion Komodo, and even less for Stockfish. There is more pause for thought here, but that is for another time.
Open Problems
Can Misses or Misters resist the transistors?
Is there a sensible notion of “depth” in an academic field, measuring distance to the frontier in terms of productivity-doubling units?
We also wish everyone some joyous (and transistor-free) holiday time.
[added Mark Lefler and mention of new NN advances in Go, some spot-changes.]
Trackbacks
- The New (Computer) Chess World Champion * The New World
- The New Chess World Champion | vyagers
- Schacksnack | Komodo 8 är världens bästa schackprogram
- A new (computer) chess champion is crowned, and the continued demise of human Grandmasters - World News Online
- A new (computer) chess champion is crowned, and the continued demise of human Grandmasters - Magng
- A new (computer) chess champion is crowned, and the continued demise of human Grandmasters | NUTesla | The Informant
- A new (computer) chess champion is crowned, and the continued demise of human Grandmasters - EasyAntZA
- A new (computer) chess champion is crowned, and the continued demise of human Grandmasters - My Blog
- A new (computer) chess champion is crowned, and the continued demise of human Grandmasters | Nigeria Breaking News By Naira Reporters
- A new (computer) chess champion is crowned, and the continued demise of human Grandmasters
- A new (computer) chess champion is crowned, and the continued demise of human Grandmasters | News5 Live
- A new (computer) chess champion is crowned, and the continued demise of … – ExtremeTech | Quick & Fast Sports News
- A new (computer) chess champion is crowned, and the continued demise of human Grandmasters | Revealed Tech - Latest Technology News Portal
- A new (computer) chess champion is crowned, and the continued demise of human Grandmasters | Prativad World News
- The New Chess World Champion « Another Word For It
- A new (computer) chess champion is crowned, and the continued demise of human Grandmasters | Gear Guide Gurus
- Wednesday assorted links
- Wednesday assorted links | Homines Economici
- New Year Links | Meta Rabbit
- Las blancas ganan | Ajedrez
- The Slow Race to Solve Chess - Trendingnewsz.com
- Shakkiohjelmat | Helsingin Shakkiklubi – Helsingfors Schackklubb
- The Source of news» Blog Archive » A new (computer) chess champion is crowned, and the continued demise of human Grandmasters
- Komodo’s victory at TCEC hits major headlines | Chessdom
- Thanks for Additivity | Gödel's Lost Letter and P=NP
- The Source of news» Blog Archive » A new (computer) chess champion is crowned, and the continued demise of human
- Stonefight at the Goke Corral | Gödel's Lost Letter and P=NP
- When Data Serves Turkey | Gödel's Lost Letter and P=NP
- Truth From Zero? | Gödel's Lost Letter and P=NP
- Sliding-Scale Problems | Gödel's Lost Letter and P=NP
- Predicating Predictivity | Gödel's Lost Letter and P=NP


Reblogged this on Pink Iguana.
Do you believe that the formula for how draws are factored into ratings will continue to hold up at that high of a level? Specifically, do you think that an engine which beat current ones 80% of the time and draws the rest would be impossible to win against even with perfect play?
I am very happy that you’ve mentioned the coin flipping example and other problems with games like backgammon, I’ve thought of it myself many times, but never saw it. I really think that in a game like backgammon, to win 51% of the time already shows superiority. Is there maybe a way to define a different required percentage for each game? I mean something like looking at the deviation or some more complicated function of the outcomes among several players. Also, do you happen to know the depth of Texas hold’em?
Hey Ken, have you heard about the recent work on deep convolutional neural networks that is currently making waves in the computer Go community? Last week a Google/Toronto group posted a paper that uses a 12-layer CNN that can defeat GnuGo 97% of the time and defeat the Monte Carlo based Fuego (100,000 rollouts) 12% of the time. The amazing thing is that this network is only a move predictor trained on a database of human professional games and without any explicit lookahead.
http://arxiv.org/abs/1412.6564
On the scaling with Moore’s Law issue. Does the chess code vectorize at all? Or it has lots of branches?
I want to clarify your comments about Komodo. I was the original partner with Don Dailey in developing a computer chess program. Our partnership started in 1986. We were both living in Lynchburg, Virginia at the time. I met him at the Lynchburg Chess Club. The name of our program was Rex. We competed together in the 1986 World Computer Championship in Cologne, Germany. We did not have a good result but it was a start. Soon thereafter I realized I would not be able to continue the partnership because of family problems and a child custody case. I called Larry Kaufman whom I have known since at least 1960 and asked him to take my place as the “chess guy” in the partnership. Fortunately Larry agreed. As far as I know Larry Kaufman worked continuously with Don Dailey from late 1986 until Don died late last year. I do not know how much difference there is between our original program Rex and the current program Komodo but I suspect that it is basically the same program but much more advanced. So, it is not correct to say that Larry Kaufman just joined with Don Dailey in 2010. They had been together for 24 years before that. The tragedy is that Don Dailey died just three days before his program won the world computer chess Championship — Sam Sloan
Interesting anecdotes from a friend who cares about chess and the people who play it. Thanks for sharing this history, Sam. I would like to add a couple points, if I may:
* Larry did not work continuously with Don Dailey. For a couple of years, at least, he worked with Rajlich on Rybka.
* The Rex chess engine was written in assembly language with dramatically limited capabilities, whereas Komodo was written in C/C++. The differences are dramatic. Having written code in both languages, it’s like the difference between flying a kite and flying an airplane. I’m sure Don’s early collaboration with you was a useful and fun part of his journey, but it’s unlikely that he would have thought of Komodo as “Rex plus lots of enhancements.”
Wishing you the best in 2015….
I was a programmer and had written a program to play shogi, Japanese chess. I made a few suggestions as to Don Dailey’s program but all the real programming was by him. I put in the chess moves recommending the Latvian Gambit and the Anglar Gambit because none of the rival programs were prepared to face those openings. All of the games Don won at the beginning were with the Latvian Gambit. What I deserve credit for was convincing him to compete in the 1986 World Computer Championship in Cologne Germany and getting my friend David Levy to allow his program to compete for the world championship even though Don’s program was new and had not competed in any other the qualifying events. Finally, when I realized I would not have time for further involvement I called Larry Kaufman and got him to take my place. Don had several other programs but he told me that all of them were basically the same, just a different language. The Rex program was in Turbo C. Next was Socratese. What I do not know is whether Komodo was essentially an improved or advanced version of the same programs or whether he went to a different algorythm. If I knew how Komodo works I would know the answer to this question.
Since I took over the programming work on Komodo, and as an early chess programmer (I authored the chess program NOW) I can assure you it is a hugely different program. Advances in computer chess over the last 10 years make the internals of the programs unrecognizable from earlier programs. Selectivity and evaluation are hugely different now. The evolution being around 10 times more complex than in the past, and the programs much, much more selective. Don restarted from scratch on several chess programs. Of course, past work influences future designs, but it is doubtful there is a single line of identical code.
Thank you. That does answer my question. Don’s Rex program was full breadth search. In other words he took every legal move up to a certain level. As the hardware became more advanced his program could search deeper. We definitely were not using any selective search. So it seems that the Komodo program is vastly different.
Don’s Rex program was full breadth search. In other words he took every legal move up to a certain level. Beyond that level he followed all checks and captures to the end. At the end of the tree he counted material unless it was checkmate. The obvious problem with this was if there was a quiet period with no checks or captures the computer would miss it. Most of the good programs back then worked like this. I imputed all the openings such as the Latvian Gambit. I tried to think of tricky openings that the opposing computers would not be able to solve.
Interesting post, Ken. Your description of the advances in chess playing algorithms reminded me of the advances in modern SAT solvers. In the SAT case, there is common agreement, now empirically verified, about the main algorithmic contributors to performance improvement (clause learning, branching heuristics, lazy data structures, restarts, etc.). See for example Figure 3 in the article Anatomy and Empirical Evaluation of Modern SAT Solvers. Is there a similar understanding of what the corresponding notions in chess algorithms are? I wonder if those ideas would generalize to other search problems or to solving two-player games of perfect information.
Hi Ken, thank you for your interesting post.
I wanted to comment on a single sentence in your post, where you ask “should we apply 75% expectation to games, pairs of games, sets, or matches … ?”. My understanding was that the standard approach is to allow a fixed amount of *time* when comparing different games. As we wish to compare depths with chess, I’ve heard that the standard amount of time is that of a tournament chess game. This greatly clarifies the case of backgammon: it’s not a single game that counts. In fact, a single game is very random in backgammon, but it’s also fairly fast.
Based on my own analysis bridging high school players and professionals, it seemed to me that by this measure, tennis has a comparable amount of depth with go!
Boris—a great point about time, and it may help answer domotorp’s query above yours. Vijay, interesting—we’ve written about SAT and TSP solvers on this blog, e.g. here. Sam, your comments should be directed to the “chessprogramming” wiki which I sourced; they speak no relation between Rex/Rexchess and Doch/Komodo. E.L., in abstract senses chess is hard to parallelize; in practice programs get only 60-65% of benefit of additional cores; we’ve written about that here
Kryptimga, ah!—I had seen this Dec. 16 roundup on the “Marginal Revolution” blog but forgot while writing the post—it was “in the back of my mind though” and I’ve added a mention to the relevant paragraph. Here is a balanced review of their paper. Bram, yes: 80% expectation over Komodo is about 3550, and I think that such a program (maybe randomized a bit by varying its hash-table size) would draw more often than lose against any strategy.
A few things were left on the cutting-room floor, including analysis of the Deep Blue – Kasparov matches by Komodo 8 and my own IPR results for computers, which might go into a separate post. There has been much recent interest in those matches. Another thing I left out is that Stockfish routinely searched deeper than Komodo, but Komodo examined 20–30% more positions. I look forward to analyses by more-knowledgeable people of how this “depth vs. breadth” contrast played out in the games. I’ve considered adding Gull 3.0 to the “troika” to make a “quadriga”, but it has a stalling bug in the approach to certain wrong-color-bishop endgames. Set Gull 3 x64 to 1 thread and 512MB hash and start it on the position with FEN code “7k/4K1p1/8/5PP1/4Bn2/8/8/8 b – – 5 68” to see delays at depth 14 and 16, which it emerges from after about 30 seconds and 2 minutes respectively. Then (with the same engine settings) use the Arena 3.0 chess GUI to script analysis to fixed depth 17 from White’s move 9 of the game Hamdouchi-Bricard from the 2010 French Championship in Belfort (available here or here), and you will get an actual crash at move 43.
Where are we since Kasparov vs Deep Blue?
Well this essay answers that question at least (we are still holding our own against the Machine, but barely), but the rest is pretty much gobbledygook.
Is he writing for our edification, or was this just a note to his peers?
We see his lack of writing ability in something we can understand, his final line…
“Can Misses or Misters resist the transistors? And is there a sensible notion of “depth” in an academic field, measuring distance to the frontier in terms of productivity doubling units? We also wish everyone some joyous (and transistor-free) holiday time.”
Give me a break! [some words redacted–KWR]
He shows us the tip of an iceberg built upon his deep theoretical knowledge of Game Theory and games, but shines no illumination upon the nine-tenths obscured beneath the surface of the murky waters, that we might relate to the tip of the iceberg shown.
I once read a book by a famous physicist explaining Superstring Theory and the Thirteen Dimensional Universe. It was his proposition that any knowledge can be communicated to the wider world outside of his specific knowledge domain. Indeed, I was able to follow every word up to the very end. I was awed that I was able to understand the concepts presented, even if I was unable to retain that knowledge or re-transmit it.
Yet in this essay presented here, despite that fact that I participated in chess tournaments and received an official rating, and went on to develop neural networks and simple game engines, I found myself adrift without references, unable to navigate the treacherous waters of his words. I don’t see that as a failing within myself, rather, I put the blame entirely on the author. He should take a bit of time and learn to Write.
I pre-dated my comment above by 3-minutes to move it next to those I’d been replying to. I trust you’re OK thru the first 2 sections. The one on Moore’s Law is hedged because there’s an apparent contradiction: Progress has seemingly followed the slower (2-year doubling) rather than faster (18-month) form of Moore’s Law. I didn’t even include my own estimation of Deep Blue’s strength (or at least accuracy) in the 2850–2900 range. Yet everyone agrees that software advances have been key, including Kaufman’s. A simpler statement in the “Patterns” section would be that just making a game more complex doesn’t “computer-proof” it for humans—perhaps the opposite.
The whole rating-horizon/diminishing-returns topic is hard to pin down. One issue I allowed for but didn’t address is that not just the single rating number but “style factors” come into play, even for programs against other particular programs. (I’m adding one factor about Komodo v Stockfish to the third paragraph in my comment above.) Regarding my own work, it involves establishing a relationship between the cumulative error made by human players over long series of moves and their Elo ratings. I get what looks like a nice linear fit for players in the 2000–2700 range, but is it really linear, and should one extrapolate it? Imposing linear fits and extrapolating without guidelines are two notorious pitfalls. When you set error x=0 the line crosses at Elo y=3570. But some separate guidelines suggest this is low by maybe 500 points.
Finally, about the game-theory section, suppose you play scissors-paper-stone and use the next digit of pi in base 3 to make your choice, say 0=scissors, 1=paper, 2=stone. Even if your opponent doesn’t know your secret, some opponent out there is lurking who can beat you every time. To avoid this, you should really privately roll a die. The same consideration applies to chess programs P whose flaws might be few, but which if twigged on might allow another program Q to take advantage, perhaps even by Q making moves that are bad in an omniscient sense.
Melvin, the chess program I developed, is capable of looking far ahead.
In fact, it has looked three tournaments ahead and proclaimed itself the champion.
Bravissimo, Melvin.
Ken, the Clark & Storkey paper your links mention actually came out a little more than a week before the Google/Toronto paper that I linked. The Google/Toronto paper trained a much larger network and produced much better results.
Still, it shows that many people are thinking along the same lines about this.
0) Excellent post, Ken. Fun stuff.
1) It seems that there could be some sort of pseudo “law” that can describe the percentage of draws as a function of the absolute level of “depth” being demonstrated by the players. Low level chess has relatively few draws; blitz chess among GMs, which is chess at about the 2200-2400 level has fewer draws than at the 2700 level; shogi, which has a depth greater than chess, has only 2% draws, which means that shogi GMs might be far from playing at the highest absolute levels; tic-tac-toe almost always ends in a draw, etc. The closer the players get to the absolute highest level of play, the more draws seem to occur. I’m not a go player. Would this happen in go, too, if the rules were “changed?” In chess, a stalemate could be ruled a loss, but a threefold rep or K v. K endings would always need to be a draw. (Or not … rules could be made to prohibit 3-fold rep, and K v. K could be a loss for the player to make, say, the last capture.)
2) The theoretical depth of a game seems correlated to the skill variance demonstrated by humans, but is this necessarily so? Computers may find that different games have different levels of depth beyond what humans can achieve. For example, chess may have a top rating of 3400 or 4000 (or more, we don’t know yet), which means that computers can play three to six or more rating classes better than humans. (Perhaps the best engines will even one day win, say, 99.9999% of the time. Unlikely but possible.) But can we assume that computers can play three to six rating classes better than humans at ALL games? No. (Tic-tac-toe is a trivial example.) Thus, do we say that the more theoretically complex the game, the better computers will eventually be at it relative to human strength? In other words, since go has greater depth than chess, will computers eventually play go ten rating classes above the greatest human, or do we not know the answer to this? Fun but nonessential questions.
3) Looks like one of the commentators here, a few comments back, drank his New Year’s Eve spirits a bit early.
You mentioned that randomness vitiates the game depth calculation. I believe the frequency of draws in chess has a similar fogging effect. Draws are rare in go, and in googling I found a figure of about 2% for shogi games being drawn. In high level chess of course the figure is over 50%.
This means that to win a game of chess one must play significantly better than the opponent, while in go and shogi one wins even by playing just marginally better. If we change the class unit definition to be that a player has a 75% chance of playing better than the opponent (by any margin), then clearly a class unit in chess would be significantly less than 200 ELO points.
I did a back of the envelope calculation suggesting the depth of chess is about 17 or 18.
A good point, although I regard it as “digested” by how chess skill is rated and competitions are understood. If you are 200 points lower rated in a match but play for draws and then pounce on a blunder, that’s legit.
One way to draw-proof chess which has been discussed is to restore some of the old Arabian rules: stalemate is a loss, and if the enemy is down to a bare King, you can win by occupying any of the four central squares with your King. Adding a rule to prevent threefold repetition might bring the draw rate under 20%. How much deeper that would make chess “feel” is debatable. My brain always feels fried after a game of Go (maybe I am 10-kyu) and I’ve only played the one game of Shogi mentioned in the post. [Ken logged in as Pip]
If I understand you correctly you mean that the frequency of draws in chess itself argues for a lack of depth vis-a-vis e.g. shogi. I.e. since a win is so hard to achieve one might as well relax and play for a draw, making the game less taxing.
I don’t think that’s right, and given that chess is unusual among intellectual games in having so many draws, I don’t think that was any part of the intention in defining game depth (though I have not read Ways of Thinking).
For go and shogi game depth is equivalent to a measure of the distance from beginner to champion in units of an individual player’s performance dispersion. Since the Elo rating calculation doesn’t explicitly deal with draws, the Elo scale effectively smooths out the expected point scores by inflating that dispersion, thus artifically reducing the calculated game depth.
Of course my knowledge of the Elo system may be badly out of date…
My point was just in reply to what I thought you were arguing. Your idea about “75% chance of playing better” is something my statistical model can quantify, although with huge error bars (2-sigma) for just one game, +- 500 Elo or more. My main points about what creates depth are still those in the “Patterns and Singularity” section of the post.
High ratings of chess engines is played in 3 minutes rapid chess. In correspondence chess, engines are allowed. If correspondence player uses only engine, he barely gains even master level (2100 ELO)
What if the game was two people compare elo’s for this game and if they are the same they flip a coin to decide who wins otherwise whoever has the higher elo always wins… The elo’s could go to infinity with increasing number of players but there is no skill or strategic depth at all…
Or the height game where whoever’s taller wins everytime…
Wow, this is a brilliant example!
“Not even Komodo or Stockfish includes a pattern classifier.” – well, AlphaZero patterned on AlphaGo showed the Achilles Heel of not having a pattern classifier. – Ray Lopez, a time traveler from the future.