Sliding-Scale Problems
Issues AlphaZero doesn’t need to deal with

|
| ETS source |
Frederic Lord wrote a consequential doctoral dissertation at Princeton in 1951. He was already the director of statistical analysis for the Educational Testing Service, which was formed in Princeton in 1947. All the scoring of our SATs, GREs, and numerous other standardized tests have been influenced both by his application of classical test theory and his development in the dissertation of Item Response Theory (IRT).
Today we discuss IRT and issues of scaling that arise in my chess model. The main point is that the problems are ingrained and beautiful observed regularities burnish them rather than fix them.
This post is long, but has other takeaways including how ability in chess identifies with scaling up the perception of value, yet how value may be a detour for training chess programs, and how the presence of logistic curves everywhere doesn’t mean your main quantities of interest will follow them.
Some Item Response Theory
The basic component of IRT is a curve 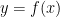



|
| source |
Each curve has two main parameters: the placement 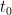

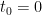
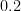


Our discussion starts with the scale of the 

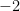

This plus the translation invariance of the curves facilitate putting offerings of different tests (or editions of a test) on a common scoring scale. That’s why you’re not scored on the actual % of SAT or GRE questions you got right. We will, however, find other places in the mechanics of models where absolute values are desired.
The Chess Test
We just posted about exactly this kind of S-shaped curve, where, however, 


|
| source |
Incidentally, this figure from our previous post shows that it does not make too much difference whether the S-curve is logistic as above (red) or derived from the normal distribution (green); there is a well-known conversion of about 
The online playing site Chess.com maintains ratings for over 4.7 million players, ten times as many as the World Chess Federation, and it shows a mostly-normal distribution of ratings:

There are issues of skew: the right-hand tail is longer, higher-rated players play more games, and they are less likely to exit the population. The whole 4.7 million are skewed relative to humanity on the whole but one can also say this of SAT- and GRE-taking students. On the whole, the population assumptions of IRT apply.
The presence of an opponent differs from test-taking. There are “solitaire” versions of chess, and more broadly, compilations of chess-puzzle tests such as these by Chess.com. To be sure, the administration of those tests is not standardized. However, the whole “Intrinsic Ratings” idea of my chess model is that we can factor out the opponent by direct analysis of the quality of move choices made by “player
The Ability-Value Digression
A second appearance of the S-shaped curve makes chess appear even more to conform to IRT. Amir Ban has argued that it is vital to chess programs. But we will see how the conformity is an illusion and how AlphaZero has exposed it as a digression. The curve has the same

The 



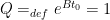




Cross-referencing the two curve diagrams and the observation that a superiority of 150 Elo points gives about 70% expectation leads to a meaningful conclusion:
For players in the region of 2000, having 150 points more ability is just like having an extra Pawn in your pocket.
This looks like a perfect correspondence between ability and advantage. But wait—there’s a catch: That’s only valid for players at the Elo 2000 level. The slope 

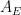

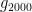

The change in slope when drawn games are removed from the sample—indicative of games like Go and Shogi in which draws are rare—is even more pronounced:

Whereas the 70% prediction from a 150-point rating difference is valid everywhere on the scale, the value of a Pawn slides. Give an extra pawn to a tyro and it matters little. Give it to Magnus Carlsen, and even if you’re his challenger Fabiano Caruana, you may as well start thinking about the next game. The shifting slope
Why, then, say the value axis is a digression? Chess programmers put colossal effort into designing their evaluation functions and tuning them in thousands of trial games. Yet the real goal is not to find moves 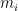

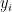
Monte Carlo tree search (MCTS) as employed by AlphaZero bypasses 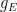
The Sliding Scale Issue
My chess model is purposed not to design a champion computer chess program but to measure flesh-and-blood humans (as hopefully staying apart from champion computer chess programs). So I must grapple with dependence across all ratings
A key observation I made early on is that the average magnitude of differences 
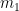
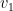
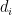


The correction is, however, artificial, computationally cumbersome, and hard to explain. A more natural scaling seems evident from the last section’s curves: take the difference in expectations rather than raw values. Namely, use
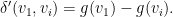
A glance at the logistic curves shows the desired effect of damping differences when 
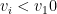
-
The rating of the chess program (at the time or depth employed), say
? This gives a fixed number but uses “inhuman” values to correct human perception.
-
The player’s own rating
. Using
but this is time-consuming on large data and might be unstable on small data.
-
A one-size-fits-all value in the middle, say
? This too is arbitrary, and while it is in the middle of the World Chess Federation’s human rating range 1000-to-2840 (Carlsen), the population mean is well below it.
I originally had a fourth reason for rejecting this approach: at the time, all these options gave inferior results to my 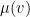
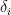
More Sliding
A simpler instance is that I want to measure the amount of challenge a player 
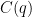


Since my model already generates probabilities 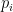

namely the expected (scaled) loss of value in the position 


-
Taking
-
Taking
and
measures for players
of different ratings. Values
depend markedly on
-
Fixing
In work with Tamal Biswas covered here and here, we attempted to define a non-sliding
Doubting the Curves
A related issue comes from my desire to test my model’s projected probabilities
What I can do instead is cluster positions according to similar vectors of values 
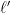
I’ve only done tests with 
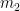
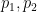

So the logistic law of IRT is out for chess. The logistic law of ratings works OK despite caveats here. The logistic law of value, despite being observed with incredible fidelity for each rating level in the above plots, has two more feet of clay. Ideally it should give me value conversion factors 
But chess programs are not constrained by the law. They can do any post-processing they want of reported move values: so long as the rank order is preserved, nothing changes in the program’s playing behavior. The “calibrations” advertised by the Houdini chess program not only trip on the sliding scale but diverge from my own data for non-blitz chess at any point
And second—where the scale slides away completely—the conversions don’t capture the different positioning of programs (and versions of the “same” program) on the landscape they share with human players. An unfortunate new cheating case last week has shown this most definitively. Thus I am resigned to having to re-jigger my equations and re-fit my model on re-run training data (a quarter million CPU core-hours per set, many thanks due to UB CCR) for each major new program release. And I wonder less at the need for continual re-centering of SAT scales.
Open Problems
Can you suggest a general solution to my sliding-scale problems?
I have skirted the issues of SAT and GRE re-scaling per se. The report on re-centering linked just above acknowledges large shifts in the population. One attraction of using chess is that the rating system gives a fixed benchmark and—per my joint-work evidence—has remained remarkably stable for the population at world level. Can the non-sliding standards in chess be leveraged to transfer deductions about distributions to general testing?
A further problem is that we treat both grade points and chess ratings as linear. Raising a C+ to a B- has the same effect on one’s GPA as raising an A- to an A. A 10-player chess tournament needing to raise its average rating by 3 points to reach the next category can get it equally from the bottom player raising 2210 to 2240 as the top player raising 2610 to 2640. Yet the latter lifts seem harder to achieve. Perhaps more aspects of the scale need plumbing before discussing how it slides.
[changed first word of last main section to “Doubting”]
Trackbacks
- London Calling | Gödel's Lost Letter and P=NP
- Far From a Turkey Shoot | Gödel's Lost Letter and P=NP
- Predicting Chess and Horses | Gödel's Lost Letter and P=NP
- Predicating Predictivity | Gödel's Lost Letter and P=NP
- How to Teach Math? | Gödel's Lost Letter and P=NP
- Stop Cheating—Again | Gödel's Lost Letter and P=NP
- Daniel Kahneman, 1934–2024 | Gödel's Lost Letter and P=NP


There’s a youtube of IM Eric Rosen taking one of those rating estimation quizzes. Its prediction of his rating is very accurate.
Hmm my link seems to have gotten lost. Try this format:
youtu.be/BFydH0LBbJk
The test is Elometer.net.