London Calling
For chess and science: a cautionary tale about decision models

|
| Clarke Chronicler blog source |
Marmaduke Wyvill was a British chess master and Member of Parliament in the 1800s. He was runner-up in what is considered the first major international chess tournament, London 1851, but never played in a comparable tournament again. He promoted chess and helped organize and sponsor the great London 1883 chess tournament. Here is a fount of information on the name and the man, including that he once proposed marriage to Florence Nightingale, who became a pioneer of statistics.
Today we use Wyvill’s London 1883 tournament to critique statistical models. Our critique extends to ask, how extensively are models cross-checked?
London is about to take center stage again in chess. The World Championship match between the current world champion, Magnus Carlsen of Norway, and his American challenger Fabiano Caruana will begin there on November 9. This is the first time since 1972 that an American will play for the title. The organizer is WorldChess (previously Agon Ltd.) in partnership with the World Chess Federation (FIDE).
The London 1883 tournament had two innovations. It was the first to use chess clocks. The second was that in the event of a game being drawn, the players had to play another game, twice if needed. Only after three draws would the point be considered halved, and this happened only seven times in 182 meetings. Chess clocks have been used in virtually every competition since, but the second experiment has never been repeated—the closest to it will come next year. Two scientific imports were that the time to decide on a move was regulated and games without critical action were set aside.
Chess and Science
Chess has long been considered a (or “the”) “game of science.” It has been the focus of numerous scientific studies. Here we emphasize how it is a copious source of scientific data. Millions of games—every top-level game and nowadays many games at lower levels—have been preserved in databases. Except that the time taken by players to choose a move at each turn is recorded only sporadically, we have easy access to full information about each player’s choices of moves.
What we also have now is authoritative judgment on the true values of those choices via analysis by strong computer chess programs. Those programs, called “engines,” can beat even Carlsen and Caruana with regularity, so we humans have no standing to doubt their judgments. The programs’ values for moves are a robust quality metric, and correlate supremely with the Elo Rating, which provides a robust skill metric.
The move values are the only chess-specific input to my statistical choice model. I have covered it several times before, but not yet in the sense of going “back to square one” to say how it originated—where it fits among decision models.
This year I have overhauled the model’s 28,000+ lines of C++ code. More exactly I have “underhauled” it by chopping out stale features, removing assumptions, and simplifying operations. I widened the equations to accommodate multiple alternative models and fitting methods, besides the ones I’ve deployed to judge allegations of cheating on behalf of FIDE and other chess bodies. The main alternative discussed here is one I did already program and reject nine years ago, but having recently tried multiple other possibilities reinforces the points about models that I am making here. So let’s first see one general form of decision model and how the chess application fits the framework.
The Multinomial Logit Model
The general goal is to project the probabilities 







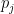



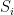

The models we consider all incorporate into 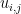

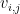
The multinomial logit model, and log-linear models in general, represent the logarithms of the probabilities as linear functions of the other elements. Using the utility function this means setting

where we have suppressed 


for all 


Fitting 

These last three equations were known already in 1883 via the physicists Josiah Gibbs and Ludwig Boltzmann, with
The Chess Case
In chess tournaments we have multiple players, but only one is involved in deciding each move. So we focus on one player but can treat multiple players as a group. Instead what we represent with the 
Each possible move 
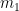
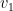

-
(a) Equate
with the move’s value
.
-
(b) Equate it with the win expectation
corresponding to
-
(c) Use the loss in value
compared to an optimal move.
-
(d) Use the loss in expectation
instead.
Option (d) automatically scales down differences in positions where one side is significantly ahead. The same small slip that would halve one’s chances in a balanced position might only reduce 90% to 85% in a strong position or be nearly irrelevant in a losing one. I remove the most extremely unbalanced positions from samples anyway. For (c) I use a “non-sliding” scale function 

My primary model parameter, called 

Criteria for fitting log-linear models are also a general issue. For linear regressions, least-squares fitting is distinguished by its being equivalent to maximum-likelihood estimation (MLE) under Gaussian error, but 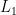
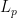

-
The frequency of playing (i.e., “matching”) the move
-
The frequency of playing
-
The total “loss of Pawns,” whether scaled as
-
The total loss of expectation
between the optimal move and the played move
.
The reason for the first three in particular is that they create my three main tests for possible cheating, so I want to fit them on my training data (which now encompasses every rating level from Elo 1025 to Elo 2800 in steps of 25) to be unbiased estimators. Besides those and MLE—which here means maximizing the projected likelihood of the moves that were observed to be played (or alternately the likelihood of the observed
Ideally, we’d like all the fitting criteria to produce similar fits—that is, close sets of fitted values for
One Log Bad
I analyzed the 168 official played games of London 1883 (one competitor left just after the halfway point), and separately, the 76 rejected draws, using Stockfish 7 to high depth on single threads furnished by UB’s Center for Computational Research (CCR). The former give 10,289 analyzed game turns after applying the extreme-value cutoff and a few others. Using the simple unscaled version (c) of utility and fitting 
Test Name ProjVal Actual Proj% Actual% z-score
MoveMatch 4871.02 4871.00 47.34% 47.34% z = -0.00
EqValueMatch 5228.95 5201.00 50.82% 50.55% z = -0.73
ExpectationLoss 259.20 297.34 0.0252 0.0289 z = -10.58
This is actual output from my code, except that to avoid crowding I have elided some columns including the standard deviations on which the 
Test Name ProjVal Actual Proj% Actual% z-score
AvgDifference 1493.46 2780.07 0.145 0.270 z = -60.9638
The projection is only half what it should be. The
For more cross-checks, there are the projected versus actual frequency of playing the 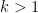
Rk ProjVal Actual Proj% Actual% z-score
1 4871.02 4871.00 47.34% 47.34% z = -0.00
2 1416.72 1729.00 13.80% 16.85% z = +9.44
3 761.84 951.00 7.47% 9.32% z = +7.33
4 523.25 593.00 5.19% 5.88% z = +3.20
5 401.63 410.00 4.03% 4.11% z = +0.43
6 325.30 295.00 3.29% 2.99% z = -1.73
7 272.12 247.00 2.77% 2.51% z = -1.57
8 232.05 197.00 2.37% 2.01% z = -2.36
9 200.88 169.00 2.06% 1.73% z = -2.30
10 175.95 104.00 1.81% 1.07% z = -5.54
The first row was the one fitted. Then the projections are off by three percentage points for 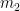


There are yet more cross-checks of even greater importance. They are the frequency with which players make errors of a given range of magnitude: a small slip, a mistake, a serious misstep, a blunder. Those results are too gruesome to show here. Fitting by MLE helps in some places but throws off the
The huge gaps in these and especially in the “AvgDifference” test (AD for short) rule out any patch to the log-linear model with one 


Log-Linear With Revised Utility: Still Bad
This is to define the utility function using a new parameter

Without scaling this is just 




This makes clear that the quantity being powered is dimensionless. The motivation for 

Thus I regard 

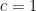
Since
Test Name ProjVal Actual Proj% Actual% z-score
MoveMatch 4870.99 4871.00 47.34% 47.34% z = +0.00
AvgDifference 2780.10 2780.07 0.2702 0.2702 z = +0.00
EqValueMatch 5261.35 5201.00 51.14% 50.55% z = -1.44
ExpectationLoss 413.42 297.35 0.0402 0.0289 z = +15.89
The equal-optimal projection remains OK. The expectation loss, however, flips from an under-projection to a vast over-projection. The cross-checks from the move ranks give further bad news:
Rk ProjVal Actual Proj% Actual% z-score
1 4870.99 4871.00 47.34% 47.34% z = +0.00
2 1123.22 1729.00 10.94% 16.85% z = +19.88
3 633.30 951.00 6.21% 9.32% z = +13.27
4 459.83 593.00 4.56% 5.88% z = +6.44
5 370.58 410.00 3.72% 4.11% z = +2.11
6 311.98 295.00 3.16% 2.99% z = -0.99
7 270.56 247.00 2.75% 2.51% z = -1.46
8 239.36 197.00 2.44% 2.01% z = -2.79
9 214.30 169.00 2.19% 1.73% z = -3.15
10 193.93 104.00 1.99% 1.07% z = -6.57
The discrepancy in the second-best move has doubled to six percentage points while the third-best move is off by more than three.
Maximum-likelihood fitting makes the gaps even worse. No re-jiggering of fitting methods nor the formula for 
Two Logs Good
As we have noted, taking the difference of logs, and inverting so that signs stay positive like so:

does not change the model. The likelihoods 

With the utility 
Test Name ProjVal Actual Proj% Actual% z-score
MoveMatch 4871.02 4871.00 47.34% 47.34% z = -0.00
AvgScaledDiff 1142.61 1142.59 0.111 0.111 z = +0.00
EqValueMatch 5251.90 5201.00 51.04% 50.55% z = -1.10
ExpectationLoss 333.20 334.46 0.0324 0.0325 z = -0.19
Rk ProjVal Sigma Actual Proj% Actual% z-score
1 4871.02 47.02 4871.00 47.34% 47.34% z = -0.00
2 1786.89 37.32 1729.00 17.41% 16.85% z = -1.55
3 929.87 28.60 951.00 9.11% 9.32% z = +0.74
4 589.93 23.29 593.00 5.85% 5.88% z = +0.13
5 419.35 19.84 410.00 4.21% 4.11% z = -0.47
6 315.24 17.32 295.00 3.19% 2.99% z = -1.17
7 246.68 15.39 247.00 2.51% 2.51% z = +0.02
8 198.71 13.85 197.00 2.03% 2.01% z = -0.12
9 161.54 12.52 169.00 1.65% 1.73% z = +0.60
10 134.18 11.43 104.00 1.38% 1.07% z = -2.64
11 111.41 10.43 97.00 1.15% 1.00% z = -1.38
12 93.90 9.59 99.00 0.97% 1.02% z = +0.53
13 77.94 8.75 76.00 0.81% 0.79% z = -0.22
14 65.40 8.02 78.00 0.68% 0.82% z = +1.57
15 55.13 7.37 62.00 0.58% 0.65% z = +0.93
Selec. Test ProjVal Actual Proj% Actual% z-score
Delta01-10 656.08 645.00 6.38% 6.27% z = -0.56
Delta11-30 800.75 824.00 7.78% 8.01% z = +1.02
Delta31-70 596.51 607.00 5.80% 5.90% z = +0.50
Delt71-150 295.70 290.00 2.87% 2.82% z = -0.38
Error>=050 709.46 675.00 6.90% 6.56% z = -1.55
Error>=100 331.88 300.00 3.23% 2.92% z = -2.02
Error>=200 141.56 114.00 1.38% 1.11% z = -2.62
Error>=400 68.76 35.00 0.67% 0.34% z = -4.61
Only the first two lines have been fitted. The other lines follow like obedient ducks—and this persists through all tournaments that I have run.
There are some wobbles that also persist: The second-best move is somewhat over-projected and the third-best move slightly under—but the remaining indices are off by small amounts whose signs seem random. So are the interval tests at the end, except that large errors are over-projected. The match to moves of equal-optimal worth tends to be over-projected regardless of the patch described here. Nevertheless, the overall fidelity under so much cross-validation is an amazing change from the log-linear cases.
Open Problems
The most particular issue I see grants that the original log-linear formulation could be fine for a one-shot purpose, say if the match-to-
Is there extensive literature on modeling the double logarithms of probabilities—and on representing probabilities as powers rather than multiples of the “pivot” 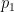

The form where 

[some name and word fixes, added CCR attribution]


See my proof of P = NP in
https://www.academia.edu/37469408/P_versus_NP
Thanks in advance…
Does this analysis date from the era of Stockfish 7, or is there another reason for choosing this version?
I chose to take the data with Stockfish 7 and use my earlier model calibration. Note the paragraph before “Open Problems” in this post.