Logical Complexity of Proofs
If you cannot find proofs, talk about them.

|
Robert Reckhow with his advsior Stephen Cook famously started the formal study of the complexity of proofs with their 1979 paper. They were interested in the length of the shortest proofs of propositional statements. Georg Kreisel and others may have looked at proof length earlier, but one of the key insights of Reckhow and Cook is that low level propositional logic is important.
Today I thought we might look at the complexity of proofs.
Cook and Reckhow were motivated by issues like: How hard is it to prove that a graph has no clique of a certain size? Or how hard to prove that some program halts on all inputs of length 
They were not directly interested in actual proofs. The kind you can find in the arXiv or in a math journal, or at a conference—online or not. The kind that are in their paper.

We are talking today about these types of proofs. Not proofs that graphs have cliques. But proofs that a no planar graph can have a 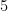

Proofs
Proofs are what we strive to find ever day. They the coin that measures progress in a mathematical field like complexity theory. We do sometimes work out examples, sometimes do computations to confirm conjectures on small examples, sometimes consider analogies to other proofs. But mostly we want to understand proofs. We want to create new ones and understand others proofs.
Years ago when studying the graph isomorphism problem, I did some extensive computations for the random case. That is for the case of isomorphism for a random dense graphs against a worst case other graph. The computations helped me improve my result. It did not yield a proof, of course, but helped me realize that a certain lemma could be improved from a bound 

Proofs Complexity
There are several measures of complexity for proofs. One is the length. Long proofs are difficult to find, difficult to write up, difficult to read, and difficult to check. Another less obvious measure is the logical structure of a proof. What does this mean?
Our idea is that a proof can be modeled by a formula from propositional logic. The 

 This is a direct proof.
This is a direct proof.
 This is a proof by contradiction.
This is a proof by contradiction.
 This is proof that uses a statement that may be true or false.
This is proof that uses a statement that may be true or false.
The last is a slight cheat, we use 
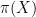



The prime number theorem says that

an error term.

|
It was noted that 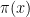

be always true? If so this would be an interesting inequality. In 1914 John Littlewood famously proved that this was not true:
Theorem 1 If the Riemann Hypothesis is true:
is infinitely often positive and negative. If the Riemann Hypothesis is false:
is infinitely often positive and negative.

Thus he proved that

is infinitely often positive and negative whether the the Riemann is true or not.
Proofs in Trouble
A sign of a proof in danger is, in my opinion, is not just the length. A better measure I think is the logical flow of proof. I know of no actual proof that uses this structure:

Do you? Even if your proof is only a few lines or even pages, if the high level flow was the above tautology I would be worried.
Another example is 
I cannot formally define this measure. Perhaps it is known, but I do think that it would be an additional measure. For actual proofs, ones we use every day, perhaps it would be valuable. I know I have looked at an attempted proof of X and noticed the logical flow in this sense was too complex. So complex that it was wrong. The author of the potential proof was me.
Open Problems
Is this measure, the logical flow of a proof, of any interest?
Trackbacks
- Animated Logical Graphs • 35 | Inquiry Into Inquiry
- Animated Logical Graphs • 36 | Inquiry Into Inquiry
- Animated Logical Graphs • 37 | Inquiry Into Inquiry
- Logical Complexity of Proofs | Delightful & Distinctive COLRS
- Animated Logical Graphs • 38 | Inquiry Into Inquiry
- 20,000 Comments and More | Gödel's Lost Letter and P=NP
- Animated Logical Graphs • 39 | Inquiry Into Inquiry
- Animated Logical Graphs • 40 | Inquiry Into Inquiry
- Animated Logical Graphs • 41 | Inquiry Into Inquiry
- Animated Logical Graphs • 42 | Inquiry Into Inquiry


The smoothest way I know to do propositional calculus is by using minimal negation operators as primitives, parsing propositional formulas into (painted and rooted) cactus graphs, and using the appropriate extension of the axiom set from Charles S. Peirce’s logical graphs and G. Spencer Brown’s laws of form. There’s a quick link here.
Here’s a basic article on Minimal Negation Operators. It’s an idea I got from something I read in Leibniz a long time ago about “least possible changes”.
Shouldn’t the third bullet point be “(A –> P) and (not A –>P)” instead of “(A or not A) implies P”? The latter, as you seem to kind of note, is a tautology, while the first is not and is how Littlewood proved li(x)-pi(x) changes sign infinitely often.
I am not entirely sure what you mean, but proof complexity already does consider the structure of propositional proofs by viewing proofs of simpler structure as being associated with separate, weaker proof systems. For example, for the single resolution rule:
(A V x) and (B V ~x) together yield (A V B)
We have separate classes of proofs when the DAG of inferences of clauses forms a tree (tree resolution), eliminates variables in the same order on each path in the DAG (ordered, a.k.a. Davis-Putnam resolution), only eliminates each variable at most once on any path in the DAG (regular resolution).
Proof complexity also looks at parameters other than proof size. These include the rank (or depth of inferences in the proof) or proof space (e.g. how many lines of the proof need to be kept in memory at a given time in order to make its inferences). Maybe some of these are related to what you would be looking for.
Interestingly, in proof theory more generally, there are structural questions regarding use of the cut rule, which generalizes the resolution rule,
(A → C) and (C → B) together yield (A → B)
or, more generally,
A → (B’ ∨ C) and (A’ ∧ C) → B together
yield (A ∧ A’) → (B ∨ B’).
This is a powerful tool when you are trying to prove (A → B), for example, because C can seemingly come from anywhere and have little obvious prior connection to A or B. Gentzen showed that his rule is not necessary, but eliminating it can really blow up proof size. Doing this makes the proof much harder to understand in general. This is a case where the extra rule improves both readability and proof size.
In general, the methods we use in writing out math proofs tend to use much more powerful rules that also seem to make proofs simpler/shorter. For example:
– the extension rule: You can define a new Boolean variable to stand for the truth value of any propositional formula in previous variables and can reason in terms of the new variable and its equivalence with the formula.
– the substitution rule: As soon as you have proved a formula, you can derive new ones by make consistent substitutions of formulas for the variables in that formula.
It turns out that these two rules have equivalent power and, together with the kinds of simple rules like the cut rule above or Modus Ponens familiar from elementary logic texts (so-called Frege systems), can capture any concept expressible by polynomial-size circuits. The rules seem to add power and clarity, but we don’t know whether they add power (though if we started just from the resolution rule then we do know that they add power).
Finally to the business of checking one’s own proofs: I am reminded of a talk by Vladimir Voevodsky on his motivation for his work on univalent foundations/homotopy type theory. He was concerned that his algebraic geometry work sued such complex concepts and arguments that he wasn’t at all clear how a reviewer, or even he, could be certain that his proofs were correct. He argued that *all* math proofs should be written in a way that they can be checked by proof checkers such as Coq (and that ZFC was poorly designed for that purpose and needed to be replaced as the foundation).
Dear Dick,
Re: Is this measure, the logical flow of a proof, of any interest?
I wasn’t quite clear how you define the measure of flow in a proof — it seemed to have something to do with the number of implication arrows in the argument structure?
But this does bring up interesting issues of “proof style” …
Propositional calculus as a language and boolean functions as an object domain form an instructive microcosm for many issues of logic writ large. The relation between proof theory and model theory is one of those issues, despite, or maybe in virtue of, PC’s status as a special case.
Folks who pursue the CSP–GSB line of developmens in graphical syntax for propositional calculus are especially likely to notice the following dimensions of proof style:
1. Formal Duality. This goes back to Peirce’s discovery of the “amphecks” and the duality between Not Both (nand) and Both Not (nnor). The same duality is present in Peirce’s graphical systems for propositional calculus. It is analogous to the duality in projective geometry and it means we are always proving two theorems for the price of one. That’s a reduction in complexity … it raises the question of how many such group-theoretic reductions we can find.
Have to break here …
Dear Dick,
Another dimension of proof style has to do with how much information is kept or lost as the argument develops. For the moment let’s focus on classical deductive reasoning at the propositional level. Then we can distinguish between equational inferences, which keep all the information represented by the input propositions, and implicational inferences, which permit information to be lost as the proof proceeds.
Information-Preserving vs. Information-Reducing Inferences
Implicit in Peirce’s systems of logical graphs is the ability to use equational inferences. Spencer Brown drew this out and turned it to great advantage in his revival of Peirce’s graphical forms. As it affects “logical flow” this allows for bi-directional or reversible flows, you might even say a “logical equilibrium” between two states of information.
It is probably obvious when we stop to think about it, but seldom remarked, that all the more familiar inference rules, like modus ponens and resolution or transitivity, entail in general a loss of information as we traverse their arrows or turnstiles.
For example, the usual form of modus ponens takes us from knowing and
and  to knowing
to knowing  but in fact we know more, we actually know
but in fact we know more, we actually know  With that in mind we can formulate two variants of modus ponens, one reducing and one preserving the actual state of information, as shown in the following figure.
With that in mind we can formulate two variants of modus ponens, one reducing and one preserving the actual state of information, as shown in the following figure.
https://inquiryintoinquiry.files.wordpress.com/2020/08/modus-ponens-variants.png
There’s more discussion of this topic at the following location.
Propositional Equation Reasoning Systems • Computation and Inference as Semiosis
hi, are you familiar with the work of Alessandra Carbone (https://www.sciencedirect.com/science/article/pii/S016800729600019X), Sam Buss and others on “logical flow graphs” and their complexity? it seems to do what you’re asking for. I think there’s also an AMS monograph.
Instead of saying “I will assume the theorem to prove it”, one can say “I will first assume a property holds, then justify this assumption”. Something like this; P -> Q, Q -> R, R -> P.
There’s three examples of propositional proofs in logical graphs using equational inference rules at the following location —
Propositional Equation Reasoning Systems • Exemplary Proofs
Dear Prof Lipton,
I do not know much about Propositional Calculus or formal proving methods. But a basic question is how would you prove the correctness of some intricate construction involved in proving a result?
Of course, some simple-minded answers would be along the line to have a structural “decomposition” and prove the smaller results. But that is where any formalism is challenged.
While the author himself can refine the results by 100s of of iterations, for the reader it will remain a difficult task, to be put-off to go through the fairly long proof. Each step of supposedly not very long proof could require some “faith” so as not to be bogged down by minor errors.
And then, the assumption that length of the proof has to be short enough, may not be applicable to ,long standing open problems.
Mea Culpa, in my native language, “minha culpa”, is much more than “my fault”. It neans something like “I am guilt”. It is very strong it was softned in English.
Dear Mathematicians, it is not our fault! Blame Physics!
Further thoughts on proof styles …
A third aspect of proof style arising in this connection is the degree of insight demanded and demonstrated in the performance of a proof. Generally speaking, the same endpoint can be reached in many different ways from given starting points, by paths ranging from those exhibiting appreciable insight to those exercising little more than persistence in sticking to a set routine.
A modicum of insight suffices to suggest the quality of “insight” resists pinning down in a succinct definition but we do tend to recognize it when we see it, so let me inch forward by highlighting its salient features in a graded series of examples.
Blog series continues here —
Animated Logical Graphs • 39
One way to see the difference between insight proofs and routine proofs is to pick a single example of a theorem in propositional calculus and prove it two ways, one more insightful and one more routine.
The praeclarum theorema, or splendid theorem, is a theorem of propositional calculus noted and named by G.W. Leibniz, who stated and proved it in the following manner.
If a is b and d is c, then ad will be bc.
This is a fine theorem, which is proved in this way:
a is b, therefore ad is bd (by what precedes),
d is c, therefore bd is bc (again by what precedes),
ad is bd, and bd is bc, therefore ad is bc. Q.E.D.
— Leibniz • Logical Papers, p. 41.
Expressed in contemporary logical notation, the theorem may be written as follows.
Using teletype parentheses for the logical negation
for the logical negation  of a proposition
of a proposition  and simple concatenation
and simple concatenation  for the logical conjunction of propositions
for the logical conjunction of propositions 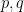 permits the theorem to be written in the following in-line and lispish ways.
permits the theorem to be written in the following in-line and lispish ways.
To be continued …
Our next transformation of the theorem’s expression exploits a standard correspondence in combinatorics and computer science between parenthesized symbol strings and trees with symbols attached to the nodes.
https://inquiryintoinquiry.files.wordpress.com/2020/09/praeclarum-theorema-parse-graph-2.0.png
On the scene of the general correspondence between formulas and graphs the action may be summed up as follows. The tree, called a parse tree or parse graph, is constructed in the process of checking whether the text string is syntactically well-formed, in other words, whether it satisfies the prescriptions of the associated formal grammar and is therefore a member in good standing of the prescribed formal language. If the text string checks out, grammatically speaking, we call it a traversal string of the corresponding parse graph, because it can be reconstructed from the graph by a process like that illustrated above called traversing the graph.
To be continued …
I think we took much time trying a landmark paper and we only stretch an old and, sometimes, obscure result.
We need the archivist knowledge in order to see what we got and what do we need.
Time to talk more and clean up the madness of the search for a new, pretty nice, result?
Hi Angela,
Sorry, I did not understand.
Was your comment meant as a reply to mine or a comment on the original blog post?
Regards,
Jon
I guess I misplaced my post! The idea is that I fell need for more chats and less eager to show new results.
Best!
angela
I think I see what you mean. At any rate, my own abilities are more suited to tilling the soil and digging basements than leaping tall buildings in a single bound. So I see a lot of work to do developing the grounds of future understanding.
Continuing our comparison of proof styles, insightful and routine, using the example of Leibniz’s Praeclarum Theorema —
https://inquiryintoinquiry.files.wordpress.com/2020/09/praeclarum-theorema-parse-graph-2.0.png
Now that our propositional formula is cast in the form of a graph its evaluation proceeds as a sequence of graphical transformations where each graph in turn belongs to the same formal equivalence class as its predecessor and thus of the first. The sequence terminates in a canonical graph making it manifest whether the initial formula is identically true by virtue of its form or not.
To be continued …