When Data Serves Turkey
A head-scratching inconsistency in large amounts of chess data

|
| Slate source |
Benjamin Franklin was the first American scientist and was sometimes called “The First American.” He also admired the American turkey, counter to our connotation of “turkey” as an awkward failure.
Today I wonder what advice Ben would give on an awkward, “frankly shocking,” situation with my large-scale chess data. This post is in two parts.
A common myth holds that Franklin advocated the turkey instead of the bald eagle for the Great Seal of the United States. In 1784, two years after the Great Seal design was approved over designs that included a bird-free one from Franklin, he wrote a letter to his daughter saying he was happy that the eagle on an emblem for Revolutionary War officers looked like a turkey. Whereas the eagle “is a Bird of bad moral Character [who] does not get his Living honestly” and “a rank coward,” the turkey is “in Comparison a much more respectable Bird, […and] though a little vain & silly, a Bird of Courage.” The Tony-winning 1969 musical 1776 cemented the myth by moving Franklin’s thoughts up eight years.
More to my point is a short letter Franklin wrote in 1747 at the height of his investigations into electricity. In his article “How Practical Was Benjamin Franklin’s Science,” Ierome Cohen summarizes it as admitting “that new experimental data seemed not to accord with his principles” and quotes (with Franklin’s emphasis):
“In going on with these Experiments, how many pretty systems do we build, which we soon find ourselves oblig’d to destroy! If there is no other Use discovered of Electricity, this, however, is something considerable, that it may help to make a vain Man humble.”
My problem, however, is that the humbling from data comes before stages of constructing my system. Cohen moves on to the conclusion of a 1749 followup letter and ascribes it to Franklin’s self-deprecating humor:
“Chagrined a little that we have been hitherto able to produce nothing in this way of use to mankind; [yet in prospect:] A turkey is to be killed for our dinner by the electrical shock, and roasted by the electrical jack, before a fire kindled by the electrified bottle: when the healths of all the famous electricians in England, Holland, France, and Germany are to be drank in electrified bumpers, under the discharge of guns from the electrical battery. ”
The Data
My backbone data set comprises all available games compiled by the ChessBase company in which both players were within 10 points of the same century or half-century mark in the Elo rating system. Elo ratings, as maintained by the World Chess Federation (FIDE) since 1971, range from Magnus Carlsen’s current 2853 down to 1000 which is typical of novice tournament players. National federations including the USCF track ratings below 1000 and may have their own scales. The rating depends only on results of games and so can be applied to any sport; the FiveThirtyEight website is currently using Elo ratings to predict NFL football games. Prediction depends only on the difference in ratings, not the absolute numbers—thus FiveThirtyEight’s use of a range centered on 1500 does not mean NFL teams are inferior to chess players. The linchpin is that a difference of 200 confers about a 75% expectation for the stronger player.
The difference of 81 to Sergey Karjakin’s 2772 gave Carlsen about a 61% points expectation, which FiveThirtyEight translated into an 88% chance of winning the match. This assumed that tiebreaks after a 6-6 tie—the situation we have today—would be a coinflip.
A chief goal of my work—besides testing allegations of human players cheating with computers during games—is to measure skill by analyzing the quality of a player’s moves directly rather than only by results of games. A top-level player may play only 100 games in a given year, a tiny sample, but those games will furnish on the order of 3,000 moves—excepting early “book” opening moves and positions where the game is all-but-over—which is a good sample. The 12 match games gave me an even better ratio since several games were long and tough: 517 moves for each player. My current model assesses Karjakin’s level of play in these games at 2890 +- 125, Carlsen’s at 2835 +- 135, with a combined level of 2865 +- 90 over 1,034 moves. The two-sigma error bars ward against concluding that Karjakin has outplayed Carlsen, but they do allow that Karjakin brought his “A-game” to New York and has played tough despite being on the ropes in games 3 and 4. No prediction for today’s faster-paced tiebreak games is ventured. (As we post, Carlsen missed wins in the second of four “Rapid” paced games; they are playing the third now still all-square.)
These figures are based on my earlier training sets from the years 2006–2013 on Elo century points 2000 through 2700, in which I analyzed positions using the former-champion Rybka 3 chess program. Rybka 3 is now far excelled by today’s two champion programs, called Komodo and Stockfish. I have more than quadrupled the data by adding the half-century marks and using all years since 1971, except that the range 2000-to-2500, with by far the most published games, uses the years 2006–2015. In all it has 2,926,802 positions over 48,416 games. The milepost radius is widened from 10 to 15 Elo points for the levels 1500–1750 and 2750, to 20 for 1400–1450 and 2800, and to 25 for 1050–1350. All levels have at least 20,000 positions except 1050–1150, while 2050–2300 and 2400 have over 100,000 positions each and 2550 (which was extended over all years) has 203,425. All data was taken using the University at Buffalo Center for Computational Research (CCR).
A Great Fit and a Problem
One factor that goes into my “Intrinsic Performance Ratings” is the aggregate error from moves the computer judges were inferior. All major programs—called engines—output values in discrete units of 0.01 called centipawns. For instance, a move value of +0.48 leaves the player figuratively almost half a pawn ahead, while -0.27 means a slight disadvantage. If the former move is optimal but the player makes the latter move, the raw difference is 0.75. Different engines have their own scales—even human chess authorities differ on whether to count a Queen as 9 or 10—and the problem of finding a common scale is the heart of my turkey.
Here are my plots of average raw difference (AD) over all of my thirty-six rating mileposts with the official Komodo 10.0 and Stockfish 7 versions. Linear regression, weighted by the number of moves for each milepost, was done from AD to Elo, so that the rating of zero error shows as the 

Having 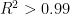
The scales between Komodo and Stockfish are also quite close. I am using Stockfish as baseline since it is open-source; to bring Komodo onto its scale here suggests multiplying its values 
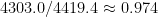
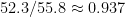
Komodo 10 and Stockfish 7 agree within their error bars on the
A Second Problem Fixes the First, Maybe
A second issue is shown by graphing the average raw error as a function of the overall position value (i.e., the value of an optimal move) judged by the program, for players at any one rating level. Here they are with Stockfish 7 for the levels 1400, 1800, 2200, and 2600 (a few low-weight high outliers near the -4.0 limit have been scrubbed):


If taken at face value, this would say e.g. that 2600-level players, strong grandmasters, play twice as badly (0.12 error) when they are 0.75 ahead as when the game is even (0.06). Tamal Biswas and I found evidence against a claim that this effect is rational. Hence it is a second problem.
What has most immediately distinguished mine from others’ work since 2008 is that I correct for this effect by scaling the raw errors. My scaling function applies locally to each move, using only its value 


The plot for Elo 2050 is almost perfect, while the flattening remains good especially on the positive side throughout the range 1600–2500 which has almost all the data. I call the modified error metric ASD for average scaled difference, which is in units of “PEPs” for “pawns in equal positions” since the correction metric has value 
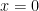

The fits are even better and with the previous “noise” at lower Elo levels optically much reduced. The
Most to the point, however, is that choosing to do scaling made a hugely significant difference in the intercept. The scaling is well-motivated, but the AD-to-Elo fit was already great without it. I could have stopped and said my evidence—from very large data—pegs perfection at 3200. This prompts us to ask:
How often does it happen that data-driven results have such degree of hidden arbitrariness?
I am sure Ben Franklin would have had some wise words about this. But we haven’t even gotten to the real issue yet.
Open Problems
What lessons for “Big Data” are developing here? To be continued after the match playoff ends…
[made figure labels more consistent with text, updated data size figures, added acknowledgment]
Trackbacks
- Magnus and the Turkey Grinder | Gödel's Lost Letter and P=NP
- Leprechauns are Multiplying | Gödel's Lost Letter and P=NP
- Truth From Zero? | Gödel's Lost Letter and P=NP
- Sliding-Scale Problems | Gödel's Lost Letter and P=NP
- London Calling | Gödel's Lost Letter and P=NP
- A Strange Horizon | Gödel's Lost Letter and P=NP
- A Strange Horizon | Gödel's Lost Letter and P=NP
- Should These Quantities Be Linear? | Gödel's Lost Letter and P=NP
- Daniel Kahneman, 1934–2024 | Gödel's Lost Letter and P=NP


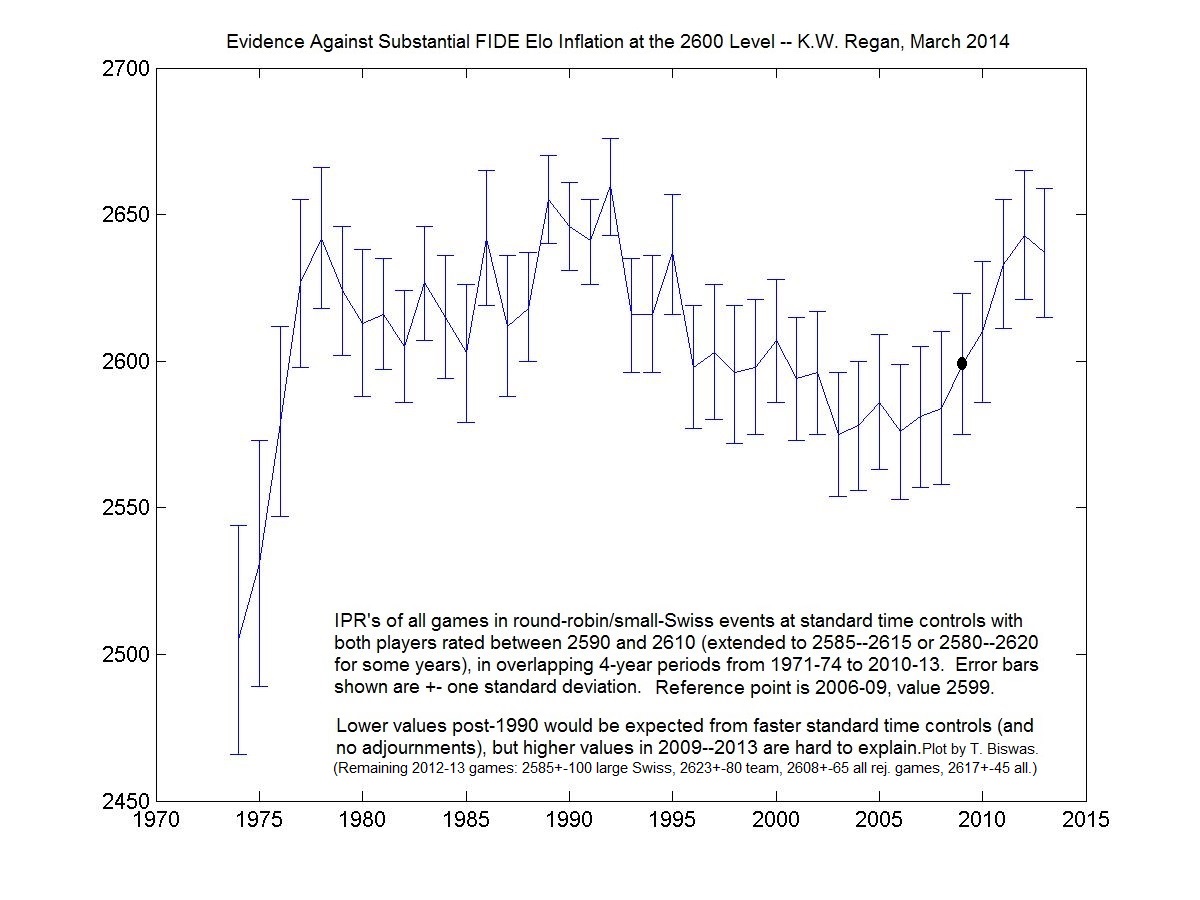{kind=link}
Earlier this week, the open-source chess-engine Stockfish won the 2016 Top Chess Engine Championship (TCEC), by a score of 54.5–45.5 over the runner-up chess-engine Houdini 5.
A striking aspect of the year’s TCEC tournament (to me and many), is that in the final championship round, black won zero games out of 100 played. Yikes!
With Stockfish and Houdini both playing at Elo 3300 (roughly), with what level of confidence (if any) can we conclude that chess is not a win for black? After all, as Feynman remarked, “much more is known than can be proved”.
More broadly, what reasons remain to play chess if (with strong play, and assessing the situation empirically) black never wins? Surely there are good reasons, but nowadays these reasons are (seemingly) no longer the traditional or simple ones.
Thanks very much, by the way, for all the wonderful Gödel’s Lost Letter chess columns. More please! 🙂
Thanks, John! You will hopefully get your wish later today—assuming I’ve finally avoided all Python traps like using the empty string “” as a “False” value in an argument sequence such as –includeZero “” –norm “” This works fine from the command line but gets stripped out in batch mode, causing “–norm” to be the argument given—which got converted to a True value, while the second “” simply disappeared so there was no command-line bomb either 🙁 Before I even mentioned this, a colleague responded to my lament of Python woes by calling it “the language where True can be set to False.”
White often comes out with a +0.30 advantage from the opening, and my spot-views of the TCEC games sometimes saw twice that after the pre-set opening moves ended. Extrapolating the points-expectation curves in the coming post will give a sense of how hard the initial -0.30 deficit is to overcome when one is at Elo 3200+.
Lol … let’s severely abuse the notion of an “Average Difference” (AD), then under the ridiculously oversimplifying assumptions that:
• White’s starting advantage is ~0.5, and
• Chess games are 100-ply random walks in AD-space, and
• Less than one game in a hundred is won by black.
Then it follows from elementary statistical considerations (if all my erf-arguments are in order) that Stockfish and Houdini 5 — in their most recent software versions, at classical time controls, running on 44-core servers, with access to 7-piece tablebases — are demonstrating AD ≲ 0.0215, which per the AD-versus-ELO charts of the OP, implies ELO ≳ 3200.
Needless to say, this TCEC-derived ELO estimate of 3200+ accords reasonably well with independent ELO estimates for Stockfish and Houdini. Hence taken all-in-all, the Ken Regan AD formalism hangs together very nicely indeed! 🙂
Thanks—that is a very interesting calculation to make!
Are you familiar with Brainfish/Cerebellum? It’s a backsolved opening database based on some 16 CPU-years of Stockfish analysis
http://www.zipproth.de
White has 0.124 out of the opening (a French defense!). The work is somewhat validated by the fact that, when used as an opening book, it beats all other engines
http://spcc.beepworld.de/
youve given this a lot of thought but thought maybe would add a different angle on the psychology pov. it appears youre showing that competitors make less dominating moves when they are ahead or behind & was curious about that & wondering also if it is related to known psychology biases. havent looked at your data, but kind of doubt that “being ahead” vs “being behind” in a game is all that randomly distributed in games. its probably the case that one or the other player is “usually” ahead of the other for most of the game. and then would that alone describe this trend? could it just be that the weaker player is usually behind in each move? think that needs to be part of the analysis here. maybe there is some other “more” fundamental effect at play here. anyway nice analysis/ slicing and dicing of the data. its neat to see big data applied to chess, and further maybe seeing reflections of general human psychology elements in the game.
Maybe I’m misunderstanding something, but the y-intercept here looks like the FIDE Elo of the engine, not the Elo of perfect chess (?)
Thanks—that is a good point to raise. Most precisely stated, IMHO, the y-intercept is the estimate of perfect play as judged by the engine considering how its outputs are modified. Note that the raw outputs project 3200 and the scaled ones project 3400. The engine itself is being run only to depth 20-or-so which in my estimation gives a rating strength only around 3000; when I run to similar depths in the usual single-PV playing mode it takes only about 10 seconds per move.
I should say also that using stronger engines and higher depths has generally moved the intercept lower.
I would sing a different tune if I were using the move-match% as the metric, namely how often the human plays the program’s first line. In multi-line mode this peaks about 58% for humans, while one of the “annoying facts of life” for my cheating tests is that the engines only agree with each other in the 70’s (on human-played positions—on positions from their own games it can dip under 70%!). The 100% matching intercept thus falls somewhere over Elo 4000. My IPR combines these elements but correlates about 5x as strongly with ASD, which is why my IPR regressions have had intercepts between 3475 and 3575 (again, trending lower).
Very interesting post. I could well be misunderstanding your procedure, but one possible explanation for the change in estimated intercept which doesn’t seem ruled out by the description in the post, might be classical measurement error. If the scaling reduces noise, then the usual attenuation of the b coefficient due to classical measurement error will be reduced. In this case, that would lead to a larger intercept in absolute value after the scaling.
Very interesting post!
I think you should go a step further in interpreting your initial fit and the improved version of it. It may be that what your modification does, is moving the engine evaluation closer to being a proxy for winning probability in the human context. I.e. humans choose moves that may not be the best, because these moves maximise winning probability in the context of their own abilities, which means that engines underestimate this human ability. By reducing the underestimation the y-intercept moves up, which I interpret as “stronger players are actually better at maximising winning probability than pure engine evaluations give them credit for”.
Here comes the important part: Normalising only reduces the underestimate, it doesn’t eliminate the core reason for it. It basically just weights the data less, where the underestimate is most severe. People still choose weaker moves if these are more likely to actually lead to a win. This means that if you reduce the underestimate even more, the y-intercept will likely rise further. You could test this hypothesis by calculating a new fit for values that come only from balanced positions, the idea being that this is where the underestimate is least pronounced.
So overall what I’m saying is that the y-intercept may change with how good your proxy for “real playing strength” aka “winning prob maximising ability” is. Your fit however will get better with the elimination of noise, which is completely separate from the quality of “playing strength proxy” as long as that is a linear addition.
The V-shaped AD-graphs could be explained by how much better engines are at tactics than humans. Very good and very bad positions are more tactical in nature than “quiet” ones. Hence humans will make more errors, measured by AB-engines.
That could be part of it. The point, however, is the linearity clear down to zero, not just an effect in positions where one side is well ahead. (Why the slope and endpoints are different for + and – might be explained by the earlier post https://rjlipton.wordpress.com/2016/01/21/a-chess-firewall-at-zero/. )
Engines gravitate to a draw in the -1,+1 range while inevitably spiraling to mate outside of -3,3, in the evaluation of Stockfish. The raw eval differences would thus be more-than-parabula shaped for these engines. The linearity seems peculiar to humans, indeed.
Thus an engine game, judged by this same engine, would have large eval surprises at the edges (though almost exclusively in one direction) but small ones in the middle (mostly in the other direction).
As to the linked article, since engines can make better-than-expected moves (humans do make them, though very seldom), the asymmetry should disappear, if I understood it correctly. The slope far away from zero is still steeper below zero in the above graphs, pointing to a role for “tilt”.
If you could delete the previous comment, I would be grateful.
Actually you make a good point: whereas the raw engine error is indistinguishable from “flat” in positions where the engine has the advantage, it does indeed arch up when it is behind. I do think this is an effect where once an engine is -1.00 behind, say, it means it has missed something major and subsequent moves (where it does not agree with the engine doing the analysis) will show higher gaps. I have myself used the phrase “on tilt” to describe this impression.
As @clumma pointed out, the y-intercept of your rating-AD curve will just show the rating of the engine being used to find AD, not perfection. I calculated a lower bound for perfection of ~5200 ELO here whcih you can read about here:
https://unclejerry9466728.wordpress.com/2018/12/20/172/
jr https://www.rutmanip.com