SODA 2023
Traces of strings, plus ways of tracing accepted papers
Anindya De was at Northwestern University and is now at the University of Pennsylvania—see here.

He was advised by two of the top advisors ever there were: Luca Trevisan and Umesh Vazirani.
Traces
I recently ran across a great paper by Anindya titled Approximate Trace Reconstruction from a Single Trace. It is co-authored with Xi Chen (Columbia University), Chin Ho Lee (Harvard University), and Rocco Servedio and Sandip Sinha (Columbia University). Notice that we did not put an Oxford comma between Servedio and Sinha as they are both from Columbia. The paper appeared at SODA 2023 this January.
Here are pointers to the almost 200 papers that were in the conference. I put this together before discovering the site conference-publishing.com, which as mentioned in my STOC 2023 post generates paper lists with links for a host of conferences. So I did all the following links myself. Do scroll past the list to the bottom to read a little more about traces which Ken and I put together.
- Small Shadows of Lattice Polytopes
- Fair allocation of a multiset of indivisible items
- Hierarchies of Minion Tests for PCSPs through Tensors
- Approximate Graph Colouring and Crystals
- The Price of Stability for First Price Auction
- Spencer’s theorem in nearly input-sparsity time
- Spatial Mixing and the random-cluster dynamics on lattices
- Nonlinear codes exceeding the Gilbert-Varshamov and Tsfasman-Vladut-Zink bounds
- A Near-Linear Time Sampler for the Ising Model with External Field
- Concentration of polynomial random matrices via Efron-Stein inequalities
- Quantum Speed-ups for String Synchronizing Sets, Longest Common Substring, and kmismatch Matching
- Halving by a Thousand Cuts or Punctures
- On the number incidences when avoiding an induced biclique in geometric settings
- Subexponential mixing for partition chains on grid-like graphs
- Weisfeilera Leman and Graph Spectra
- Stronger 3SUM-Indexing Lower Bounds
- Tight Bounds for Monotone Minimal Perfect Hashing
- Almost Consistent Systems of Linear Equations
- Testing and Learning Quantum Juntas Nearly Optimally
- Testing Convex Truncation
- Player-optimal Stable Regret for Bandit Learning in Matching Markets
- Competitive Information Design for Pandoras Box
- Breaking the O(n)-Barrier in the Construction of Compressed Suffix Arrays and Suffix Trees
- Short Synchronizing Words for Random Automata
- Packing cycles in planar and bounded-genus graphs
- Improved Distributed Algorithms for the Lovasz Local Lemma and Edge Coloring
-
Optimal Fully Dynamic
-Center Clustering for Adaptive and Oblivious Adversaries
- A logic-based algorithmic meta-theorem for mim-width
- Tiny Pointers
- Streaming complexity of CSPs with randomly ordered constraints
- Computing Square Colorings on Bounded-Treewidth and Planar Graphs
- Near-Linear Time Approximations for Cut Problems via Fair Cuts
- Stronger Privacy Amplification by Shuffling for Rényi and Approximate Differential Privacy
- Minimizing Completion Times for Stochastic Jobs via Batched Free Times
- Optimal Pricing Schemes for an Impatient Buyer
- Online Prediction in Sub-linear Space
- Fast Discrepancy Minimization with Hereditary Guarantees
- Exact Flow Sparsification Requires Unbounded Size
- Curve Simplification and Clustering under Frechet Distance
- Almost Tight Bounds for Online Facility Location in the Random-Order Model
- The complete classification for quantified equality constraints
- Small subgraphs with large average degree
- Mean estimation when you have the source code; or, quantum Monte Carlo methods
- Online Min-Max Paging
- Gap-ETH-Tight Approximation Schemes for Red-Green-Blue Separation and BicoloredEuclidean Travelling Salesman Tours
- Map matching queries on realistic input graphs under the Frachet distance
- Private Query Release via the Johnson Lindenstrauss Transform
- Efficient decoding up to a constant fraction of the code length for asymptotically goodquantum codes
- Passing the Limits of Pure Local Search for weighted k-Set Packing
- Improved Bounds for Sampling Solutions of Random CNF Formulas
- Pricing Query Complexity of Revenue Maximization
- Flow-augmentation III: complexity dichotomy for Boolean CSPs parameterized by thenumber of unsatisfied constraints
- Parameter tractability of Directed Multicut with three terminal pairs parameterizedby the size of the cutset: twin-width meets flow-augmentation
- Approximate Trace Reconstruction from a Single Trace
- Dynamic Algorithms for Packing-Covering LPs via Multiplicative Weight Updates
- Sharp threshold sequence and universality for Ising perceptron models
- Maintaining Expander Decompositions via Sparse Cuts
- Near Optimal Analysis of the Cube versus Cube Test
- Approximating Knapsack and Partition via Dense Subset Sums
- Online and Bandit Algorithms for Norms with Gradient-Stable Approximations
- On complex roots of the independence polynomial
- Simplex Range Searching Revisited: How to Shave Logs in Multi-Level Data Structures
- Improved Pattern-Avoidance Bounds for Greedy BSTs via Matrix Decomposition
- Moser-Tardos Algorithm: Beyond Shearer’s Bound
- Deterministic counting Lovasz local lemma beyond linear programming
- Conflict-free hypergraph matchings
-
A Subquadratic
-approximation for the Continuous Frachet Distance
- Interdependent Public Projects
-
A Nearly Time-Optimal Distributed Approximation of Minimum Cost
- A tight quasi-polynomial bound for Global Label Min-Cut
- Polynomial formulations as a barrier for reduction-based hardness proofs
- Faster Algorithm for Turn-based Stochastic Games with Bounded Treewidth
- Instability of backoff protocols with arbitrary arrival rates
- On the orbit closure intersection problems for matrix tuples under conjugation and leftright actions
- Constant Approximating Parameterized k-SetCover is W[2]-hard
- Online Lewis Weight Sampling
- Toeplitz Low-Rank Approximation with Sublinear Query Complexity
- Kernelization for Graph Packing Problems via Rainbow Matching
- Improved Integrality Gap in Max-Min Allocation: or Topology at the North Pole
- Generalized Unrelated Machine Scheduling Problem
- Tight Complexity Bounds for Counting Generalized Dominating Sets in Bounded-Treewidth Graphs
- An Improved Approximation for Maximum Weighted k-Set Packing
- Excluding Single-Crossing Matching Minors in Bipartite Graphs
- Byzantine Agreement with Optimal Resilience via Statistical Fraud Detection
- Finding Triangles and Other Small Subgraphs in Geometric Intersection Graphs
- Simple, deterministic, fast (but weak) approximations to edit distance and Dyck edit distance
- From algorithms to connectivity and back: finding a giant component in random k-SAT
- Sparse graphs with bounded induced cycle packing number have logarithmic treewidth
- Shrunk subspaces via operator Sinkhorn iteration
- Improved Approximation Algorithms for Unrelated Machines
- Model-Checking for First-Order Logic with Disjoint Paths Predicates in Proper MinorClosed Graph Classes
- A Distanced Matching Game, Decremental APSP in Expanders, and Faster DeterministicAlgorithms for Graph Cut Problems
- Super-resolution and Robust Sparse Continuous Fourier Transform in Any Constant Dimension: Nearly Linear Time and Sample Complexity
- A Polynomial Time Algorithm for Finding a Minimum 4-Partition of a Submodular Function
- Positivity of the symmetric group characters is PH-hard
- Parallel Exact Shortest Paths in Almost Linear Work and Square Root Depth
- On the Integrality Gap of MFN Relaxation for the Capacitated Facility Location Problem
- Weak Bisimulation Finiteness of Pushdown Systems With Deterministic Transitions-ExpTime-Complete
- Beating Greedy Matching in Sublinear Time
- Integrality Gaps for Random Integer Programs via Discrepancy
- Improved Approximation for Two-Edge-Connectivity
- Zigzagging through acyclic orientations of chordal graphs and hypergraphs
- Shortest Cycles With Monotone Submodular Costs
- Traversing the FFT Computation Tree for Dimension-Independent Sparse FourierTransforms
- Fixed-Parameter Tractability of Maximum Colored Path and Beyond
- A half-integral Erdős-Pósa theorem for directed odd cycles
-
Improved Bi-point Rounding Algorithms and a Golden Barrier for
- Approximate Distance Oracles for Planar Graphs with Subpolynomial Error Dependency
- A Framework for Approximation Schemes on Disk Graphs
- Cubic Goldreich-Levin
- Closing the Gap Between Directed Hopsets and Shortcut Sets
- “Who is Next in Line?” On the Significance of Knowing the Arrival Order in Bayesian Online Settings
- Smaller Low-Depth Circuits for Kronecker Powers
- Fast algorithms for solving the Hamilton Cycle problem with high probability
- On Minimizing Tardy Processing Time, Max-Min Skewed Convolution, and TrianglarStructured ILPs
- Maximal k-Edge-Connected Subgraphs in Weighted Graphs via Local Random Contraction
- A simple and sharper proof of the hypergraph Moore bound
- A Sublinear-Time Quantum Algorithm for Approximating Partition Functions
- On Problems Related to Unbounded SubsetSum: A Unified Combinatorial Approach
- Query Complexity of the Metric Steiner Tree Problem
-
Sublinear-Time Algorithms for Max Cut, Max E2Lin
, and Unique Label Cover on Expanders
-
Near-Linear Sample Complexity for
Polynomial Regression
- On (Random-order) Online Contention Resolution Schemes for the Matching Polytope of (Bipartite) Graphs
- Optimal Algorithms for Linear Algebra in the Current Matrix Multiplication Time
- Algebraic Algorithms for Fractional Linear Matroid Parity via Non-commutative Rank
- Almost Tight Error Bounds on Differentially Private Continual Counting
- Secretary Problems: The Power of a Single Sample
- Robust Voting Rules from Algorithmic Robust Statistics
- Faster and Unified Algorithms for Diameter Reducing Shortcuts and Minimum Chain Cover
- Improved girth approximation in weighted undirected graphs
- Online Sorting and Translational Packing of Convex Polygons
- Fully Dynamic Exact Edge Connectivity in Sublinear Time
- Algorithmizing the Multiplicity Schwartz-Zippel Lemma
- A Nearly Tight Analysis of Greedy k-means++
- A polynomial-time algorithm for 1/2-well-supported Nash equilibria in bimatrix games
- Bidder subset selection problem in auction design
- Massively Parallel Computation on Embedded Planar Graphs
- Balanced Allocations: The Power of Memory with Heterogeneous Bins
- Simple Mechanisms for Agents with Non-linear Utilities
- The Power of Clairvoyance for Multi-Level Aggregation and Set Cover with Delay
- Steiner Connectivity Augmentation and Splitting-off in Poly-logarithmic Maximum Flows
- Discrepancy minimization via regularization
- Equivalence Test for Read-Once Arithmetic Formulas
- Time-Space Tradeoffs for Element Distinctness and Set Intersection via Pseudorandomness
- Local Distributed Rounding: Generalized to MIS, Matching, Set Cover, and Beyond
- Parameterized Approximation Scheme for Biclique-free Max k-Weight SAT and Max Coverage
- Improved Distributed Network Decomposition, Hitting Sets, and Spanners, via Derandomization
- Breaching the 2 LMP Approximation Barrier for Facility Location with Applications to kMedian
- Query Complexity of Inversion Minimization on Trees
- Faster Deterministic Worst-Case Fully Dynamic All-Pairs Shortest Paths via Decremental Hop-Restricted Shortest Paths
- Optimal Square Detection Over General Alphabets
- Differentially Private All-Pairs Shortest Path Distances: Improved Algorithms and Lower Bounds
- Faster Computation of 3-Edge-Connected Components in Digraphs
- Sampling Equilibria: Fast No-Regret Learning in Structured Games
- Higher degree sum-of-squares relaxations robust against oblivious outliers
- Fast Distributed Brooks Theorem
- Graph Classes With Few Minimal Separators. I. Finite Forbidden Subgraphs
- Optimal Deterministic Massively Parallel Connectivity on Forests
- Foundations of Transaction Fee Mechanism Design
- Graph Classes With Few Minimal Separators. II. A Dichotomy
- Distributed Maximal Matching and Maximal Independent Set on Hypergraphs
- Quantum tomography using state-preparation unitaries
- Almost-Linear Planted Cliques Elude the Metropolis Process
- Timeliness Through Telephones
- Efficient resilient functions
- Dynamic Matching with Better-than-2 Approximation in Polylogarithmic Update Time
- The Need for Seed (in the abstract Tile Assembly Model)
- Private Convex Optimization in General Norms
- Dynamic Algorithms for Maximum Matching Size
- Unique Games hardness of Quantum Max-Cut, and a conjectured vector-valued Borell’s inequality
- A Nearly-tight Analysis of Multipass Pairing Heaps
- A Tight Analysis of Slim Heaps and Smooth Heaps
- Lossless Online Rounding for Online Bipartite Matching (Despite its Impossibility)
- Approximation Algorithms for Steiner Tree Augmentation Problems
- Low Degree Testing over the Reals
- Streaming algorithms for the missing item finding problem
- Economical Convex Coverings and Applications
- Interactive Coding with Small Memory
- Non-Stochastic CDF Estimation Using Threshold Queries
- Elliptic Curve Fast Fourier Transform Part I : Low-degree extension in time O(n log n) over all finite fields
- Single-Pass Streaming Algorithms for Correlation Clustering
- A New Approach to Estimating Effective Resistances and Counting Spanning Trees in Expander Graphs
- Superpolynomial Lower Bounds for Decision Tree Learning and Testing
-
The
-Subspace Sketch Problem in Small Dimensions with Applications to Support Vector Machines
-
Beating
-Approximation for Weighted Stochastic Matching
- Towards Multi-Pass Streaming Lower Bounds for Optimal Approximation of Max-Cut
-
Parameterized Algorithm for the Planar Disjoint Paths Problem: Exponential in
, and Linear in
- Learning Hierarchical Cluster Structure of Graphs in Sublinear Time
- The Exact Bipartite Matching Polytope Has Exponential Extension Complexity
- 4D Range Reporting in the Pointer Machine Model in Almost-Optimal Time
The Trace Result
The trace problem begins by sending a binary string 

![{\delta \in [0,1]}](https://s0.wp.com/latex.php?latex=%7B%5Cdelta+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

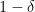


Given
strings
produced by
, reconstruct
of length
that minimizes a distance metric
. The metric of choice is to maximize the length
of the longest common subsequence (not necessarily contiguous) of
As indicated by its title “Approximate Trace Reconstruction from a Single Trace,” the paper tackles the extreme case 

-
How well does the algorithm perform—relative to theoretically optimal choices given
-
How well does the algorithm perform when
These questions are posed for small, medium, and large values of 
-
In the average-case setting, having access to a single trace is provably not very useful: no algorithm, computationally efficient or otherwise, can achieve significantly higher accuracy given one trace that is
bits long than it could with no traces.
- Having access to a single trace is already quite useful for worst-case trace reconstruction: an efficient algorithm can perform much more accurate reconstruction, given one trace that is even only a few bits long, than it could given no traces at all.
The deep point is that when
Open Problems
Comparing my list of pointer to the papers from SODA, which was a bit of trouble to create by hand, to the STOC’23 output from the conference-publishing site, leads to a curious question:
Do we scan lists of papers more by looking for subject words in their titles or looking for authors we know?
Well, I have not found SODA’23 on that website, where authors too would be given; for me, copying the authors would more than double the manual work.

