Sharpening an analytic tool for regular languages

|
| IEEE source for Book, Even, Ott photos |
Ronald Book, Shimon Even, Sheila Greibach, and Gene Ott proved a fact that may escape attention nowadays. Everyone knows the equivalence of finite automata (of all major kinds) and regular expressions. But do you know that the regular expressions can be made unambiguous?
Today we explore consequences of this fact for analyzing automata via generating functions.
A regular expression  is unambiguous if:
is unambiguous if:
-
wherever
 occurs inside ,
occurs inside ,  ;
;
-
wherever
 occurs inside , every string
occurs inside , every string  can be written in exactly one way as
can be written in exactly one way as  with
with  and
and  ;
;
-
wherever
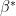 occurs inside , every
occurs inside , every  can be written in exactly one way as a concatenation of strings in
can be written in exactly one way as a concatenation of strings in  .
.
The last clause entails in particular that the empty string cannot match  when appears in . Since
when appears in . Since  is always in
is always in  , it would have multiple “parses” if matched . The only parse we want to allow is that is a concatenation of zero strings.
, it would have multiple “parses” if matched . The only parse we want to allow is that is a concatenation of zero strings.
Is there an easy way to convert any given regular expression into one that is unambiguous? In senses that can be made precise in computational complexity terms, the answer is no. But we can get an equivalent unambiguous regular expression by different means.
DFAs Give Unambiguous Regexps
If we have a deterministic finite automaton  where
where  has multiple final states, let
has multiple final states, let 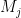 stand for the machine with the same code but only
stand for the machine with the same code but only 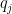 as final state. Then
as final state. Then

and moreover this union is disjoint: Because  is deterministic, every string
is deterministic, every string 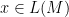 goes to exactly one of the final states .
goes to exactly one of the final states .
Hence to build an unambiguous regular expression for , it suffices to build one when there is exactly one final state. First suppose that is the start state, which we number  and the other states
and the other states  . Initialize the
. Initialize the  matrix
matrix  with
with ![{A[i,j] = c}](https://s0.wp.com/latex.php?latex=%7BA%5Bi%2Cj%5D+%3D+c%7D&bg=ffffff&fg=000000&s=0&c=20201002) if has a transition on
if has a transition on  from state
from state  to state
to state  ;
; ![{A[i,j] = \emptyset}](https://s0.wp.com/latex.php?latex=%7BA%5Bi%2Cj%5D+%3D+%5Cemptyset%7D&bg=ffffff&fg=000000&s=0&c=20201002) otherwise. The initial condition is that with
otherwise. The initial condition is that with  , every entry in the principal
, every entry in the principal 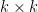 minor of is an unambiguous regular expression. Now execute the following code:
minor of is an unambiguous regular expression. Now execute the following code:
for (k = n; k > 2; k--) //bypass and eliminate state k
for (i = 1; i < k; i++) //obviate incoming arc (i,c,k)
for (j = 1; j < k; j++) //update transition from i to j
A[i,j] = A[i,j] + A[i,k] A[k,k]* A[k,j];
The loop maintains three invariants:
-
Computations on strings matching
![{A[i,j]}](https://s0.wp.com/latex.php?latex=%7BA%5Bi%2Cj%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) involve no intermediate states
involve no intermediate states  .
.
-
All strings that take from state to state without going through states match .
-
is a
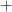 of zero or more terms having different leading characters.
of zero or more terms having different leading characters.
If ![{A[i,k]}](https://s0.wp.com/latex.php?latex=%7BA%5Bi%2Ck%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) has multiple terms, we can distribute them over
has multiple terms, we can distribute them over ![{A[k,k]^*\cdot A[k,j]}](https://s0.wp.com/latex.php?latex=%7BA%5Bk%2Ck%5D%5E%2A%5Ccdot+A%5Bk%2Cj%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) to preserve the second invariant. (For a binary alphabet this is not needed.) Now we verify that the regular expression remains unambiguous because:
to preserve the second invariant. (For a binary alphabet this is not needed.) Now we verify that the regular expression remains unambiguous because:
-
The previous involved no intermediate states
 , so
, so  and the character taking it there in are new.
and the character taking it there in are new.
-
![{A[k,k]^*}](https://s0.wp.com/latex.php?latex=%7BA%5Bk%2Ck%5D%5E%2A%7D&bg=ffffff&fg=000000&s=0&c=20201002) is unambiguous because, by the second invariant, substrings matching
is unambiguous because, by the second invariant, substrings matching ![{A[k,k]}](https://s0.wp.com/latex.php?latex=%7BA%5Bk%2Ck%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) can be uniquely parsed.
can be uniquely parsed.
-
The
![{A[i,k]\cdot A[k,k]^*\cdot A[k,j]}](https://s0.wp.com/latex.php?latex=%7BA%5Bi%2Ck%5D%5Ccdot+A%5Bk%2Ck%5D%5E%2A%5Ccdot+A%5Bk%2Cj%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) concatenation is uniquely parsable at front and back, and does not match , since and
concatenation is uniquely parsable at front and back, and does not match , since and ![{A[k,j]}](https://s0.wp.com/latex.php?latex=%7BA%5Bk%2Cj%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) are unambiguous and do not match .
are unambiguous and do not match .
On loop exit, the regular expression ![{A[1,1]^*}](https://s0.wp.com/latex.php?latex=%7BA%5B1%2C1%5D%5E%2A%7D&bg=ffffff&fg=000000&s=0&c=20201002) denotes
denotes  and is unambiguous for the same reason argued for with
and is unambiguous for the same reason argued for with 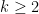 . If the final state is not the start state, we can number it
. If the final state is not the start state, we can number it  , and then the answer is
, and then the answer is ![{A[1,1]^*\cdot A[1,2] \cdot A[2,2]^*}](https://s0.wp.com/latex.php?latex=%7BA%5B1%2C1%5D%5E%2A%5Ccdot+A%5B1%2C2%5D+%5Ccdot+A%5B2%2C2%5D%5E%2A%7D&bg=ffffff&fg=000000&s=0&c=20201002) . This finishes the proof.
. This finishes the proof. 
The paper proves a stronger statement about preserving ambiguities. The above looks like a polynomial-time (indeed, cubic time) algorithm but is not—because the sizes of the parts in particular can compound with each step of .
Generating Functions
Let us fix the binary alphabet  . Given any language
. Given any language  over
over  , we define the bivariate generating function
, we define the bivariate generating function

where  the number of strings of length
the number of strings of length 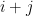 in that have exactly
in that have exactly  s and s.
s and s.
Note that if we identify 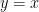 , then
, then  is the more-familiar univariate generating function, whose coefficients
is the more-familiar univariate generating function, whose coefficients 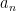 of
of 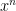 count the numbers of strings of length
count the numbers of strings of length  in . Philippe Flajolet and Bob Sedgewick wrote a whole free book titled Analytic Combinatorics in which these generating functions figure prominently. The main fact about
in . Philippe Flajolet and Bob Sedgewick wrote a whole free book titled Analytic Combinatorics in which these generating functions figure prominently. The main fact about  is a simple extension of the well-known one about
is a simple extension of the well-known one about  :
:
Theorem 1 If 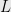 is regular, then there are two polynomials
is regular, then there are two polynomials  and
and  such that
such that

That is, the generating function of a regular language is a rational function. The converse does not hold, because there are regular and non-regular languages that have the same “census counts” 
To prove this theorem, we start by simply associating to every regular expression over the algebraic function  given by the following recursive rules, in which the right-hand quantities are numerical:
given by the following recursive rules, in which the right-hand quantities are numerical:
Clearly the function thus defined is rational. The observation that finishes the proof is:
If  is unambiguous, then
is unambiguous, then  equals
equals  where is the language of .
where is the language of .
That every regular language has an unambiguous regular expression finishes the proof: The equality clearly holds in the base cases and for the inductive case. The checks for the  and
and  cases are straightforward from the definition of unambiguity for .
cases are straightforward from the definition of unambiguity for .
Machines and Invariant Denominators
Given any -state DFA that recognizes , we can get  directly from . Form the matrix
directly from . Form the matrix  along lines of the regular expression matrix above, but this time put an
along lines of the regular expression matrix above, but this time put an  for every 0-arc and a
for every 0-arc and a  for every -arc. Make every other entry . If has more than one accepting state
for every -arc. Make every other entry . If has more than one accepting state  , make a separate matrix for each such
, make a separate matrix for each such  and sum the results. Number the start state
and sum the results. Number the start state 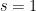 and
and  (or
(or 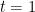 if is the start state). Then run the same triple nested loop as before, but with the body
if is the start state). Then run the same triple nested loop as before, but with the body
![\displaystyle A_M[i,j] = A_M[i,j] + \frac{A_M[i,k]\cdot A_M[k,j]}{1 - A_M[k,k]}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++A_M%5Bi%2Cj%5D+%3D+A_M%5Bi%2Cj%5D+%2B+%5Cfrac%7BA_M%5Bi%2Ck%5D%5Ccdot+A_M%5Bk%2Cj%5D%7D%7B1+-+A_M%5Bk%2Ck%5D%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
The result is the generating function for the language  of strings processed from
of strings processed from  to . Adding them up gives . The result is invariant both under the ordering of states of to eliminate and the choice of DFA recognizing —it need not be the canonical minimum one. If is strongly connected, meaning that every state
to . Adding them up gives . The result is invariant both under the ordering of states of to eliminate and the choice of DFA recognizing —it need not be the canonical minimum one. If is strongly connected, meaning that every state  can reach every other state by some string (i.e.,
can reach every other state by some string (i.e.,  ), then there is a further notable invariant:
), then there is a further notable invariant:
Theorem 2 If a DFA  is strongly connected then for all states
is strongly connected then for all states  and
and 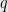 , the bivariate generating function of
, the bivariate generating function of  is given by
is given by

where  and the numerator has no common divisor with .
and the numerator has no common divisor with .
The proof only requires analyzing the two-state case. If is strongly connected, then all elimination sequences will leave a strongly connected two-state machine, meaning that both  and
and  are nonzero in the following diagram:
are nonzero in the following diagram:

The generating functions shown for  , ,
, ,  , and
, and  have the same denominator, and by
have the same denominator, and by  , do not reduce further. Because is the same whichever state of is used as “,” we can “walk” the diagram to represent any
, do not reduce further. Because is the same whichever state of is used as “,” we can “walk” the diagram to represent any  while preserving the denominator and the irreducibility.
while preserving the denominator and the irreducibility.
Thus 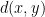 is common to the whole host of DFAs defined from by changing the start state and/or the set of final states. It is an invariant of the two-sorted graph
is common to the whole host of DFAs defined from by changing the start state and/or the set of final states. It is an invariant of the two-sorted graph  , whose edge sets of -arcs and -arcs each have out-degree .
, whose edge sets of -arcs and -arcs each have out-degree .
Singular Sets
The zeroes of the polynomial form an algebraic set and are singularities of the generating function. Adopting the looser nomenclature by which a “variety” is allowed to be algebraically reducible, we propose calling the zero set  the singular variety of . It is really an invariant of the two-sorted graph
the singular variety of . It is really an invariant of the two-sorted graph  . Here are pictures for all automata of one or two nodes. The pictures are plotted in the real plane using the Desmos Graphing Calculator.
. Here are pictures for all automata of one or two nodes. The pictures are plotted in the real plane using the Desmos Graphing Calculator.


The line  is always present, simply because substituting
is always present, simply because substituting  makes into a stochastic matrix. The other parts of hold the most interest.
makes into a stochastic matrix. The other parts of hold the most interest.
What does represent? Intuitively, it captures information about the cycle structure of . Whether it captures enough information is perhaps doubted by the last example, whose is the same as for the one-state machine. The full generating function for  is computed via
is computed via

Some three-state automata exhibit other interesting behaviors. The two in the middle should be plotted in the complex plane.

Intersecting with the line 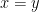 gives the singular points of , which figure highly in analytical results collected in the book by Flajolet and Sedgewick and in some more recent references. We anticipate higher returns from analysis of by bringing in more techniques from algebraic geometry.
gives the singular points of , which figure highly in analytical results collected in the book by Flajolet and Sedgewick and in some more recent references. We anticipate higher returns from analysis of by bringing in more techniques from algebraic geometry.
Open Problems
Have you seen this two-variable generating function for regular languages? What can be done with it?
[added note about why is always present]
Related
,








This line:
A[i,j] = A[i,j] + A[i,k] A[k,k]* A[k,j]; seems to have this extraneous term “A[k,k]”.
Other than that, the above code looks just another version of Floyd-Warshall Algorithm for transitive closure of a graph given by A.
Wonder if this is just a coincidence.
Not sure where or what you mean—is there a typo? I’ve always been tempted to write the body in C++ style using the “+=” operator as
A[i,j] += A[i,j].A[k,k]*.A[k,j]
but it strikes me as less clear to read. Indeed, the Floyd-Warshall algorithm has a similarly motivated triple loop.
Oh– I did not realize that these are regular expression operators– difficult to parse in this context.
The idea of using a bivariate generating function to study some “univariate phenomenon”, taking the diagonal of the generating function, is very common in combinatorics. I do not know whether it has been used in the context of regular languages though.
Indeed. I left unmentioned this nifty survey by Robin Pemantle and Mark Wilson: “Twenty Combinatorial Examples of Asymptotics Derived From Multivariate Generating Functions”. In this context, taking the diagonal does not mean making x=y but rather the coefficients of with equal powers, here focusing on the strings in L that have an equal number of 0s and 1s. This also figures in the book by Flajolet and Sedgewick—here is a paper by Wilson dedicated to Flajolet. A good gateway paper for the application of counting walks on graphs is “Algebraic diagonals and walks: Algorithms, bounds, complexity” by Bostan, Dumont, and Salvy (2017).
with equal powers, here focusing on the strings in L that have an equal number of 0s and 1s. This also figures in the book by Flajolet and Sedgewick—here is a paper by Wilson dedicated to Flajolet. A good gateway paper for the application of counting walks on graphs is “Algebraic diagonals and walks: Algorithms, bounds, complexity” by Bostan, Dumont, and Salvy (2017).