Advances on Group Isomorphism
Finally progress on this annoying problem

David Rosenbaum is right now the world expert on one of my favorite problems, group isomorphism. He is a third-year PhD student at the University of Washington in Seattle under Paul Beame, and has been visiting MIT this year to work with his other advisor, our familiar friend Aram Harrow. He presented a paper on this at SODA 2013, and recently posted a successor paper to the ArXiv. He grew up in the Portland area where he won prizes in scholastic chess tournaments.
Today I want to talk about his work, which not only advances our understanding of this problem, but also makes progress on other ones.
Group isomorphism is a great problem for many reasons. It is a special case of the graph isomorphism problem, which is another annoying problem. Very annoying. Of course a good idea when confronted with a immovable problem is to work on a special case. Add extra conditions. Perhaps the special case adds enough extra structure, giving you additional leverage, so the problem can be “moved.”
Group isomorphism is not a great problem because people are lining up to solve it. Nor are people lining up to solve graph isomorphism problem either, but that is another story. The new algorithms that David has found are all galactic as we coined the term here. Indeed they are way out there in space usage too. But galactic or not they are based on beautiful ideas that will have impact in other areas, in my opinion. This is why they are so important. Every advance in our understanding of how to create clever algorithms—for any problem—advances our general understanding of computation. And that is good.
Notes From Underground
You can skip this, since it is about how we work here at GLL. Our “staff” has various rules and procedures for the creation of a new piece. We have a complex process… Of course not. But I did consider writing about David’s work quite a while ago.
Something made me delay and delay and delay. Other pieces were written, others were put out, and a discussion of group isomorphism stayed on the stack. Other things have slowed us including “floodgates” on Ken’s side. Somehow I knew that David was onto something great. Initially he made progress on special groups, then on a larger class of groups, and finally on all finite groups. Even better he discovered a new algorithmic principle that may be of importance to other areas of computing. It is exciting and may be useful in both theory and in practice.
An aside: perhaps I should still wait some more. Could his next result be even stronger? Oh well, we will push forward and if he makes more progress we will discuss that another day. Just to prove my point here is a quote from my earlier draft that we never “approved” for release:
I wonder if he can extend to prove
for
for all groups. The reason is that 2-groups always seemed to be the roadblock to me for this improvement.
Now we can note that he can indeed. Let’s talk about group isomorphism and more.
Group Isomorphism
The group isomorphism problem is about multiplication tables. A finite group is described by giving the complete product table. If the group consists of the elements
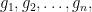
then the table is 
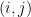



Long ago Bob Tarjan and Zeke Zalcstein and I made a simple observation: Group isomorphism could be done in time

This relies on the easy-to-prove fact that every group has at most 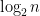
What is nice about this observation is it is a much better time bound than any known for graph isomorphism. But it also depends on group theory in a very weak way. It only uses Joseph Lagrange’s theorem: the order of a subgroup always divides the order of the group.
New Results
David made progress on group isomorphism by combining powerful insights from group theory with several from computing. Let’s first state some of his newest results, and then discuss at high level how he proves them.
Theorem 1 Group isomorphism can be solved in time
for solvable groups.

Solvable groups are special, but I always thought that they would be a hard class to handle. For starters their structure is immensely complex. Yet solvable groups do have many neat closure properties that have proved to be useful.
Note that the “extreme” opposite of solvable groups are simple groups. Thanks to the classification of simple groups, the isomorphism problem for them is trivially in polynomial time. The algorithm is based on the cool fact that every simple group has a generator set of at most size two. It is interesting to have a trivial algorithm whose correctness proof is immense, since the correctness depends on the classification theorem. Perhaps this is the worst ratio of algorithm size to correctness proof? Anyway it is a building block for the final result.
Theorem 2 Group isomorphism can be solved in time
for general groups.

Of course the “general groups” here are finite—group isomorphism as discussed here is always about finite groups. The improvement is the constant 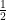

A New Game
As usual the best way to understand what David did is to look at his paper. However there is a new principle that he isolated that I would like to discuss here. This is the principle that I believe can be used elsewhere, and is a fundamental advance.
Consider the following game between Alice and Bob—who else? They each have access to a finite tree 






The issue in the game is whether Alice and Bob can follow a pre-determined strategy that identifies structural features in the tree. For instance, suppose they agree that after strating from the root they never choose a node with an odd number of children. Then the sets
David, not acting as a player in this game, has discovered a wide range of trees where there is an economical winning strategy for Alice and Bob. This strategy involves counting, and yields a much smaller value of 
One cautionary aspect of this game, however, is that even though it is defined on a tree, it lacks the space-saving properties of depth-first search. The entire sets involved seem to need to be maintained in memory at once. David in fact shows that his game strategy forms a spectrum with a common time-space tradeoff, with his best time at one end and the simple generator-enumeration algorithm at the other end.
Open Problems
The main open problem is to show—really show—that group isomorphism is in polynomial time. Or failing that, show that it can be done in time 
Another interesting open question is what can we say about his new principle? Can we use his search ideas on other problems? This seems like an accessible research line.
Trackbacks
- UW CSE News » “Finally, progress on this annoying problem”
- Isomorphism Is Where It’s At | Gödel's Lost Letter and P=NP
- Three From CCC | Gödel's Lost Letter and P=NP
- A Big Result On Graph Isomorphism | Gödel's Lost Letter and P=NP
- Babai breakthru: graph isomorphism in quasipolynomial time | Turing Machine
- [Solved]: Group isomorphism to graph ismorphism – Ignou Group
- Group Theory Is Tough | Gödel's Lost Letter and P=NP
- [Solved]: Group isomorphism to graph ismorphism
- New, Old, Ancient Results | Gödel's Lost Letter and P=NP
- New, Old, Ancient Results | Gödel's Lost Letter and P=NP
- An Annoying Problem | Gödel's Lost Letter and P=NP


Prof. Lipton, I am curious as to why you are so interested in algorithms for group iso with run-time n^{\alpha \log n + o(\log n)} for some constant \alpha < 1, as in this post and a previous post of yours: http://rjlipton.wordpress.com/2011/10/08/an-annoying-open-problem/? It seems that for problems we think are exponential time, improving the base of the exponential (or equivalently, the constant in the exponent) is often of interest. But for problems that we think might really be in P, is it so interesting to get an improvement of the constant in the exponent? Do you have some other reason for being interested in this kind of improvement for group iso in particular?
I should clarify that I don't mean to diminish the significance of Rosenbaum's result at all, but am asking a general question about group iso. (On the contrary, Rosenbaum's technique is quite interesting and seems like it may have further applications elsewhere.) Rather I am asking if there is some reason **specific to group iso** to be interested in general in such improvements in the constant in the exponent.
To put it another way: getting a square-root speed-up will never turn a super-polynomial-time algorithm into a polynomial-time one. One might argue that if we someday get a poly-time algorithm, say time n^6, then a square-root speed-up turns it into n^3, which is much more practical. And indeed, an improvement from n^6 to n^3 is something people are often interested in. However, this technique seems so general that it seems entirely plausible that it might not be compatible with whatever deep poly-time algorithm is eventually (if ever) found for group iso. You yourself even say that anything n^{o(\log n)} (little-oh) seems beyond these methods, leading me to wonder more generally about your interest in this constant-in-the-exponent. Thanks.
Dear Whoever:
I think my interest is that I thought about it for decades. The initial n^log n is simple and improvements are hard to come by. The problem is one that I have thought about for too long. Seems like there should be a better algorithm, but I am stuck…
Best
Dick
Thanks very much for the great post on my work!
Dear David:
Thank you for the great work. I am big fan of your work.
Best
Dick
Where does he use special properties of Solvable groups in his fundamental advance?
The essential property is Hall’s characterization of solvable groups in terms of Sylow bases. A group is solvable iff it has a Sylow basis. That is, for each prime p_i dividing the order of the group, there exists a Sylow p_i-subgroup P_i such that P_i P_j = P_j P_i for all i and j.
Note that http://arxiv.org/abs/1304.3935 does not explicitly exploit the structure of solvable groups. However, it relies heavily on Lemma 5.1. This lemma follows from results in http://arxiv.org/abs/1205.0642 that depend on the characterization of solvable groups in terms of Sylow bases.
Thankyou David.
I would think linear algebra techniques from Group cohomology should play an important role in Group isomorphism complexity. Has anyone used Group cohomology for this problem?
The closest is this paper: http://arxiv.org/abs/1305.1327 However, it is for extension equivalence rather than group isomorphism.
Hi there, i have a question for you guys,, the other day a found this paper thats try to demostrate a polinomial time algorithm for the 2 SAT problem, my question is.. does this is proof p = np? if so why he didnt appers as a solver of the millenium problem… http://arxiv.org/ftp/arxiv/papers/1110/1110.1658.pdf
2SAT is in P, indeed it reduces to and from directed graph connectivity so it is NL-complete. Counting the number of solutions to a 2CNF formula, however, is NP-hard, indeed #P-complete.
The linked paper indeed addresses 3SAT, so it would prove NP=P if it worked. The algorithm is trying to take the intersection of the sets of unsatisfying assignments for each clause. It has the line:
“Let @Unsolvable = (2 ^ (2 ^ Variables.Count)) – 1”
which takes a double exponential, and at the end does “If @Result = @Unsolvable”… So complexity is not accounted correctly.
Welcome to (other) new commenters, and reminder: once the first comment is modded-in, later comments are immediate unless they trip a filter, except that your Nth comment where N is congruent to 0 mod K is flagged, where K seems to be variable… 🙂
thanks for the reply, it was my mistake.. its 3 not 2 sat problem… any way… is this algorythm has been proven? its since 2 years since was posted. any update?
I refuted the algorithm in my reply to you.
As I understand the algorithm, Alice and Bob each have a tree. Alice branches fully to a depth d, and then from each node at depth d picks a random path to a leaf. Bob picks a random path to a node at depth d, then branches fully to all leaves. If the two trees are secretly isomorphic, then Alice and Bob must have a path in common. If we have chosen d correctly, then Alice and Bob’s set of leaves are of size ~= square root of the total number of leaves. For the case of groups, it is easy to hash each leaf into an identifying string (given the generating set specified by the leaf, take the lexicographically earliest word that corresponds to each element of the group, order the elements in that order and write down the multiplication table). You can then do the standard list-matching to check if Alice and Bob have identified a leaf in common.
It seems to me that we can do the balancing in (forgive me) a more balanced way — alternate turns to branch fully or pick a random child node. So for an odd distance from the root (the identity element), Alice branches fully by looping over all elements that are not in her current subgroup of G while Bob picks a random element not in his current subgroup of H. For an even distance, Alice and Bob’s roles are reversed.
Why would we want to do this? Because this allows us to compute partial multiplication tables partway down, and restrict our attention to pairs that match at that stage. If we are lucky (that is, if random distinct subgroups of G with a given number of generators are generally not isomorphic to each other), then we will wind up dramatically reducing the size of the lists we need to deal with.
The big sticking point is whether or not this is the case for p-groups, where we might expect a certain degree of isomorphism of distinct subgroups. However, with even a relatively small exponent, the number of p-groups blows up dramatically.
Later — worked this out a bit. Assume we have a p-group of order n = p^m. Via Higman/Sims, the number of non-isomorphic p-groups of order p^{2k} is e^{16k^3 / 27 + epsilon} asymptotically. So at depth 2k < m in the tree, Alice and Bob's lists of nodes are each of size ~n^k, and probabilistically we expect p^{2mk – 16/27 k^3} false collisions in addition to our true collision. So if we "checkpoint" at depths which are multiples of ~sqrt{m}, we expect to only retain the true collision at checkpoint, and our lists never grow to be larger than exp{O(sqrt{log n})}.
This seems to me to be a big improvement, if it can be made rigorous.
Do I have a hole in my logic?
Very interesting. I thought that this was a standard search strategy, but perhaps it has only been applied to “edit distance” problems before, that is, problems determining whether one structure s_1 can be converted into another s_2 in at most k steps and where isomorphism can be trivially checked. In such problems, the two search trees are naturally defined as the trees of structures that can be reached with \floor{k/2} and \ceil{k/2} steps from s_1 and s_2, respectively. s_1 can be converted to s_2 with k or fewer steps iff some structure is found in both search trees.
For example, I applied this strategy to reduce the time required to check whether a permutation can be sorted with k or fewer transpositions from O((3k)^{3k}) to O(k logk * (3k)^{1.5k}). Here, s_2 = 1, 2, …, n ; s_1 is some permutation of s_2; and each step transposes a contiguous block of elements. By searching outward from both the input permutation and the target identity permutation you explore 2 search trees with half of the combinatorial explosion. However, this was only my Honour’s thesis and did not seem of practical use so I never tried to publish it.
So, this technique can definitely be applied to other problems. The two obvious requirements of the technique are identifying both ends to search from and a method of identifying an overlap in the search trees. It is very impressive to see this applied to a problem such as group isomorphism where constructing the search trees is nontrivial.
That’s certainly an interesting idea. I suspect that it probably works well in the average case. It would be interesting if that could be proven rigorously that it works well for most groups.
However, there seem to be counterexamples on which your algorithm runs much slower than the above analysis would suggest. Consider a 2-nilpotent 2-group G with center isomorphic to (Z_2)^((1 / 2) log n). Your algorithm requires at least n^(Omega(log n)) time for these groups as one can see by counting the number of subspaces of dimension (1 / 4) log n of the center. 2-nilpotent groups such as these are believed to contain the main difficulty of group isomorphism so they can’t be handled by some other existing algorithm. I think it should also be possible to construct stronger counterexamples that give lower bounds of n^((1 / 2 – epsilon) log n) if more care is taken. Of course, a vector space would work but I didn’t consider that since the isomorphism problem is trivial. A semidirect product of a small non-Abelian 2-group of order n^epsilon with (Z_2)^((1 – epsilon) log n) seems to do the trick though.
You’ve lost me a bit (it’s been a while since I did any real group theory). Why is the runtime dependent on the number of subspaces of dimension (1/4) log n of the center? Do we have to assume that the probability of two random subgroups of size 2^{1/2 log n} being isomorphic is enhanced by that factor?
Also, keep in mind that where ever you have Alice or Bob picking a “random” child node, you could change that (at a cost of O(n^2)? per node) to picking “the most distinct” child node. That is, given an ordered set of generators , one can look at all extensions , look at the resulting multiplication tables, and pick the table that shows up the fewest times. It would be interesting to see if you could do this across all nodes in your list at level k; given a list of ordered sets of generators {}, pick g_{k+1} for each ordered set so that the mutliplication tables are as distinct as possible across the full list.
…ordered set of generators \langle g_1, … g_k \rangle …
…all extensions \langle g_1, … g_{k+1} \rangle …
…list of ordered sets of generators {\langle g_1, … g_k \rangle } …
There aren’t really any explicit instances of group isomorphism which are believed to correspond to the hard cases of group isomorphism as far as I am aware, so I can’t give you an explicit example such that 1) your algorithm fails and 2) seems hard in general. My previous comment gives some fairly general subclasses of groups which seem like they should contain instances that satisfy (1) and (2).
Isomorphism problems often have the property that there are heuristic algorithms that work very well on almost all instances but fail on certain pathological instances. For example, the WL-algorithm for graph isomorphism that was conjectured to solve graph isomorphism in polynomial time for a long time; however, counterexamples were eventually found. These counterexamples are not truly hard however as one can solve the isomorphism problem on them using specialized techniques.
Your modification of choosing the most distinct node makes it harder to construct counterexamples. (It seems that this modification can also be implemented with polynomial factor overhead.) However, note that your algorithm still fails on vector spaces so somehow you have to argue that when we transition from a vector space to a group that is “close” to a vector space in some sense, the performance of the algorithm makes a huge jump. This seems unlikely to me though of course it’s possible that it could be true. If you could prove that no such groups exist, that would certainly be very interesting.
Anyway, rigorous analysis of the algorithm seems difficult since it would seem to require us to understand the structure of the lattice of subgroups of G. Just understanding the structure of G is already a very hard problem since even doing just the simple groups was already extremely difficult.
There aren’t really any explicit instances of group isomorphism which are believed to correspond to the hard cases of group isomorphism as far as I am aware, so I can’t give you an explicit example such that 1) your algorithm fails and 2) seems hard in general. My previous comment gives some subclasses of groups which seem like they should contain instances that satisfy (1) and also (2) to an extent. I’m actually not sure about the second counterexample giving a lower bound of n^((1 / 2 – epsilon) log n) anymore though I think there should still be at least an n^(Omega(log n)) for both.
Isomorphism problems often have the property that there are heuristic algorithms that work very well on almost all instances but fail on certain pathological instances. For example, the WL-algorithm for graph isomorphism that was conjectured to solve graph isomorphism in polynomial time for a long time; however, counterexamples were eventually found. These counterexamples are not truly hard however, as one can solve the isomorphism problem on them using specialized techniques.
Your modification of choosing the most distinct node makes it harder to construct counterexamples. (It seems that this modification can also be implemented with polynomial factor overhead.) However, note that your algorithm still fails on vector spaces so somehow you have to argue that when we transition from a vector space to a group that is “close” to a vector space in some sense, the performance of the algorithm makes a large jump. This seems unlikely to me though of course it’s possible that it could be true. If you could prove that no such groups exist, that would certainly be very interesting.
Let me see if I can work out your second example a little.
You have a non-Abelian 2-group H of order n^epsilon, with a matrix representation phi over (Z_2)^{(1-epsilon) log n}. The multiplication is
(h_1, v_1) * (h_2, v_2) = (h_1 h_2, v_1 + phi(h_1) v_2).
Picking a random element (h,v), with h of order m, we find that it generates {(e,0), (h,v), (h^2, (phi + I) v), …} and is of order m or 2m (because (phi^{2m-1} + … + phi + 1) = 0 since phi^{m+k} = phi^k and everything is in characteristic 2).
In general, if we have a set of k generators (h_1,v_1), … (h_k, v_k), and {h_1,… h_k} generates a subgroup H’ of H of order M, then the corresponding subgroup of G looks like a subset of H’ x (Z_2)^{Mk} (the components in the vector space are spanned by phi(h)v_i, for h in H’ and i = 1…k).
I can see how one would think it might be difficult to distinguish the subgroup generated by {(h_1,v_1), … (h_k,v_k)} from the subgroup generated by {(h_1, w_1),… (h_k, w_k)}, but doesn’t that depend on your representation? I’m not totally convinced yet.
My favourite example of ratio of proof of correctness to algorithm complexity is this: Given a transitive finite permutation group of degree greater than 1, does it have a fixed-point-free element of prime-power order? According to a paper of Fein, Kantor and Schacher, there is a constant-time algorithm (the answer is yes), and their proof indeed leads to a polynomial-time algorithm to find one; but the proof (for either algorithm) uses the classification of finite simple groups (and quite a lot more besides). The Fein-Kantor-Schacher paper is 30 years old; this shows how little we really know!
This is a good improvement. However, it is still log linear meaning that we like to see in the future—O(n^{C log n/loglog n})
I gave an O(n log n) algorithm for Abelian group isomorphism in published in 1984. In the same paper, I gave a constructive proof of the fundamental theorem of finite Abelian groups. B. Fu and I improved this result in 2006.
Li Chen (DC)