The Curious History of the Schwartz-Zippel Lemma
On the discovery that randomness helps exponentially for identity testing

Jack Schwartz was one of most famous mathematicians who worked in the theory of linear operators, his three volume series with Nelson Dunford is a classic. Yet he found the time, the creative energy, and the problem solving ability to make seminal contributions to many diverse areas of science—not just mathematics or theory—but science in general. He worked on, for example: parallel computers, the design of new programming languages, fundamental questions of computational theory, and many more wonderful problems from a wide range of areas. He is greatly missed by our community as well as all of science.
Today I want to talk about the Schwartz-Zippel Lemma. Or the Schwartz-Zippel-DeMillo-Lipton Lemma. Or the Schwartz Lemma. The whole point is to discuss the curious history of this simple, but very useful result.
First, I thought that I would give one short story that shows somethings about the character of Jack. When he was working on a problem, that problem was the most important thing in the world. He had tremendous ability to focus. He also was often ahead of his time with the problems he worked on; his important work on parallel computers was way before it was the critical problem it is today.
Once at a POPL meeting Jack Schwartz was scheduled to talk right before lunch. His talk was on his favorite topic at the time: the programming language SETL. He loved to talk about SETL, I think it was one of his favorite topics of all times—but that is just my opinion.
In those days there were no parallel sessions, and the speaker right before Jack gave a very short talk. That left almost a double period before lunch. Right after being introduced, Schwartz said with a smile,
“well I guess I have almost an hour then
”
There was a slight sigh in the room—it was clear that most people would have preferred a short break before lunch.
And he took it. But Jack’s talk was wonderful, and we soon forgot about lunch, and learned the cool ideas that had gone into his latest creation. I never used SETL, but I could see the importance of the ideas. Like his work on parallel computations it was perhaps ahead of the field. SETL was a very high level language compared with the popular ones of then, and seemed almost too big a jump.
SETL was, as you might have guessed, a set based language that had an important influence over later languages. Guido van Rossum, considered the principal author of Python, said of SETL:
Python’s predecessor, ABC, was inspired by SETL — Lambert Meertens spent a year with the SETL group at NYU before coming up with the final ABC design!
Thus, SETL is the grand parent of Python, which shows the importance of the ideas that Jack had years earlier. By the way many others worked on SETL and I do not wish to minimize their contributions—perhaps I will discuss that another day.
Let’s now turn to the history of probably one of simplest results Schwartz ever published—but perhaps in the top few of his most cited papers.
Identity Testing
The fundamental question of identity testing is: given a polynomial 


total points.
About thirty years ago, the idea arose to a number of people that perhaps a random algorithm could do much better. Indeed randomness helps exponentially here.
The intuition is really simple: Suppose that you envision 


The issue, as computer scientists, is of course that we cannot pick points from the cube; we can only pick points from a discrete set, and the cube is continuous. Said another way: we cannot pick points of infinite precision, we must pick points of finite precision. Now the intuition is still correct, but one needs to prove it. This is a classic theme that recurs throughout theory: often pure mathematical results must be “improved” to be of use to our community.
The key lemmas that were proved were all of the following form:
Lemma: Suppose that
is a non-zero polynomial of degree
over a field and
is a non-empty subset of the field. Then,
where
are random elements from
is a function.
![\displaystyle \mathsf{Pr}[P(r_{1},\dots,r_{n})=0] \le \delta(n,d,|S|)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathsf%7BPr%7D%5BP%28r_%7B1%7D%2C%5Cdots%2Cr_%7Bn%7D%29%3D0%5D+%5Cle+%5Cdelta%28n%2Cd%2C%7CS%7C%29&bg=e8e8e8&fg=000000&s=0&c=20201002)
The question is what 
- The Strong Bound is,
;
- The Weak Bound is,
.
Schwartz’s Paper
Schwartz published his work in JACM in 1980. His actual paper is quite long and covers many other aspects of identity testing. His main result is the famous test for identity, which in our terms is the Strong Bound for Identity Testing.
He was also very interested in applications: plane geometry for example. He also discussed real variable versions and other extensions. An earlier conference version is in the Proceedings of the International Symposium on Symbolic and Algebraic Computation in 1979.
Zippel’s Paper
Zippel proved a more complex bound than Schwartz in his paper. That his result is at least as strong as the Weak Bound, is immediate. Part of the difficulty is that Zippel had a different model: he used the maximum degree of each variable, rather than the total degree. Thus, it is a bit difficult to compare Zippel’s result with the other two, since he has a somewhat different model.
His paper was published at the same conference as Schwartz in 1979, where he spoke right after Jack—according to the program. Zippel was driven by the work of actual symbolic systems and he gave timings of a real implementation of his identity testing algorithm. It is nice to see that the methods really work.
DeMillo-Lipton’s Paper
We published our paper in Information Processing Letters in 1978: it was a technical report in 1977.
Our paper was driven by an application to program testing, which was something we worked on at the time. We actually proved what we are calling the Weak Bound. Our paper was strange: we did not actually state a lemma, but gave our result as a free flowing statement. The reason we did this was because our audience was software engineers, and we felt that a very formal looking paper would not be one that they would look at carefully.
The reason we got the Weak Bound is instructive. We tried to bound the probability that the polynomial would be non-zero at a random point. This yields
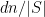
and not

It is interesting that all three papers had the same two ideas:
- A polynomial of one variable of degree
- A polynomial of
variables.
The respective proofs then follow by an induction of some type.
Like Zippel, our audience was not theorists. For us the audience was, as I just stated, software engineers—especially those working on program testing. The main point of our paper was that identities could be tested in far fewer evaluations than

We did not implement our algorithm, but did include an entire half page of data to show how efficient the random algorithm would be for various parameters.

Comparison
I am part of this so it is impossible to be unbiased, but here are some of the key points that I think are clear:
Who was first? This is unclear, if by first you mean something that is not written down in some manner. Schwartz’s Technical report is from 1978, ours is from 1977. But who knows.
Who was first published in a journal? We were the first here: 1978 in Information Processing Letters.
Who was last? Schwartz was the last to discover this great result. His publication in the JACM in 1980 ended all the discoveries. One point from the history of science that is that the credit for a result often, not always, goes to the last person who discovers it.
Who had the weak result? All the players knew that only a polynomial, not an exponential number of evaluations, were enough to check any identity.
Who had the Strong result? Schwartz clearly, I believe, is the only one who had the Strong Bound. I cannot believe that we missed the bound—it is so simple. But Zippel also missed the Strong Bound. I think part of the reason is that Rich, Zippel, and I were thinking of practical applications; thus, the the exact polynomial bound was unimportant to us.
Why Schwartz-Zippel?
The result is usually called the Schwartz-Zippel lemma. Sometimes we are cited too. Mostly not. Oh well.
I can see calling it just the Schwartz Lemma: he was the only one with the Strong Bound. But since most applications need only the weaker results, I can see why Zippel is added. I do not get why we are usually left out. I think there could be two reasons: First, Schwartz and Zippel gave their respective papers at the same conference on symbolic computation in 1979—perhaps that is why they get cited together. Perhaps.
Second, DeMillo and I never pointed out our earlier paper to Schwartz. When Schwartz’s JACM paper came out, I quickly saw there was no reference to us. But I did nothing. Perhaps the lesson today is to immediately say something. Perhaps another lesson is that of Gian-Carlo Rota:
Publish the Same Result Several Times.
Open Problems
What should this result be called? What do you think? Some researchers have told me that they usually refer to all three papers, but they point out that the general idea that identity checking is easy with random points is an “old” idea in the coding theory community. Oh well.
Perhaps, more important is the real open problem that I will discuss another day: can we derandomize identity testing for arithmetic circuits? There have been some exciting partial results and I will discuss those soon.

Finally, I would like to thank Ken Regan for his tremendous help, especially in explaining to me the differences among the three papers. As usual all, errors are mine. Ken promises to add a detailed comment on his thoughts. Again, thanks Ken.
Trackbacks
- Four Derandomization Problems « Combinatorics and more
- Keeping up with the Schwar(t)zes « The Lumber Room
- Beating A Forty Year Old Result: Hamilton Cycles « Gödel’s Lost Letter and P=NP
- Lecture #10: Polynomial Identity Testing, and Parallel Matchings « CMU Randomized Algorithms
- 9/11 And The Web « Gödel’s Lost Letter and P=NP
- Kenneth Shum's scrapbook
- Giving Some Thanks Around the Globe « Gödel’s Lost Letter and P=NP
- Beyond Las Vegas And Monte Carlo Algorithms « Gödel’s Lost Letter and P=NP
- Two proofs of the Schwartz-Zippel lemma | Anurag's Math Blog
- Alon-Furedi, Schwartz-Zippel, DeMillo-Lipton and their common generalization | Anurag's Math Blog
- Did Euclid Really Mean ‘Random’? | Gödel's Lost Letter and P=NP
- [Solved]: Is there an efficient algorithm for expression equivalence? – Ignou Group
- A Simple Fact | Gödel's Lost Letter and P=NP
- [Solved]: Is there an efficient algorithm for expression equivalence?
- Happy Un-Birthday Rich | Gödel's Lost Letter and P=NP
- Happy 1,000th Post and 75th Birthday, Dick | Gödel's Lost Letter and P=NP


Oops, an HTML glitch—a less-than sign got parsed as opening an anchor, ended by a greater-than sign in the next, so two formulas got magically spliced. Greater-than signs seem to be OK. Here’s a fix:
——————————————————————————-
I shared an office with Zippel for half a year at Cornell in the 1980s, so I hope I’ve gotten this right :-).
Zippel’s theorem, expressed as a probability, is that for any polynomial f(x_1,…,x_n) of degree at most D in any one variable, and subset S, |S| > D, of the field for which f is not identically zero on S^n,
Pr[f(x) = 0, x \in S^n] is at most 1 – (1 – D/|S|)^n.
One can compare the three bounds stated in terms of the probability of getting a witness for f being nonzero on S^n:
Schwartz: Pr(nonzero) >= 1 – d/|S|
L-deMillo: Pr(nonzero) >= 1 – nd/|S|
R. Zippel: Pr(nonzero) >= (1 – D/|S|)^n.
The extra exponent n in Zippel’s compared to Schwartz’s bound makes Zippel’s look weaker—and in complexity applications where the field size and degree are not so critical it comes out that way. However, a case given by Zippel in his paper—where the polynomial is “balanced” in the sense of having the same degree D in each variable—shows that his bound can be stronger. Consider polynomials of the form
f(x_1,…,x_n) = \prod_{i = 1}^n \prod_{j=1}^D (x_i – j)
and take S = {1,2,…,D,D+1,…,B}, so |S| = B. Now any x_i with a value in 1,…,D forces f to zero, so there are D^n zeroes. The probability of getting a nonzero is thus (1 – D/B)^n, so here Zippel’s bound is tight (as he says). Now put k = B/nD, so B = knD and D/B = 1/(kn). Stated this way, Zippel’s probability of a nonzero is
(1 – 1/kn)^n.
while Schwartz’s success probability—since the total degree is nD—is simply
1 – nD/B = 1 – 1/k.
Now pick n = 2. Then Zippel’s success probability becomes >= (1 – 1/2k)^2 = 1 – 1/k + 1/4k^2. That’s bigger than Schwartz by the term +1/4k^2. This extends to higher values of n, e.g. for n = 3 the bounds are equal for k = 1/9, but k=1/9 is impossible since k = B/3D and B > D.
The upshot is that Schwartz’s lemma is stronger only when the polynomials have “unbalanced” degrees in the different variables. Also generally, the exponent n in Zippel’s version can be offset by scaling |S| upward by a factor of n, roughly since (1-1/n)^n –> 1/e. In “tight” situations (e.g. finite field size barely big enough) this “slack” may not exist, and then it’s not easy to say in general which bound is better. It would be interesting to examine applications where one bound is more useful than the other.
I deleted the earlier one with the HTML error as Ken asked.
Oh, this is really cool. I suppose this technique would extend to testing an ideal to see whether it is the unit ideal. i.e.
I’m definitely looking forward to hearing about the derandomization results.
Nice article, I wondered what the lemma was. Are you going to discuss the finite field Kakeya problem?
In our course on Introductory Theory of Computation, we indeed come across Schwartz-Zippel Lemma.
When we are study read-once branching programs in the context of Probabilistic Algorithms, we come across this concept.
I really did not know that you were one of the discoverers (inventors?) of this result too Professor. Guess, the theorem – the one who discovers it last, is the real discoverer – is as tight as a mathematical theorem.
This is a nice story. Would Dick and DeMillo stated their result as a “separate one”, would we refer to other names. This is, I think, the problem with CS. We have so many nice ideas and results which combinatorialists have even never dreamed about. But we do not “sale” them properly. We stick on the idea that “applications” are more important. Well, we have applied – and what then? The “trace” is lost …
Actually, the Combinatorial Nullstellensatz, derived from Hilbert’s Nullstellensatz by Noga Alon, is in a similar flavor. All these extensions of the basic fact “polynomial of degree n cannot have more than n roots” to multivariate polynomials turned out to be very useful. In many other situations, not just in “designed applications”.
Noga Alon did NOT derive the Combinatorial Nullstellensatz from Hilbert’s Nullstellensatz. It has stronger assumptions, a stronger conclusion, and an easy proof.
Dana Moshkovitz just posted An Alternative Proof of The Schwartz-Zippel Lemma. This contains a 9-sentence proof of a weaker form of the Schwarz-Zippel-DeMillo-Lipton Lemma, where is the entire field. The idea is to evaluate the polynomial along the
is the entire field. The idea is to evaluate the polynomial along the  parallel lines in the field. Each of these univariate polynomials has degree at most
parallel lines in the field. Each of these univariate polynomials has degree at most  .
.
Dick,
Thanks for posting this nice summary of this work. First, I want to apologize for not mentioning Rich DeMillo and your work on this. I was unaware of it until quite late, sometime in the 1990’s I believe.
Second, there is one more step in this work that took, for me at least, a very surprising turn. Around 1987, Michael Ben Or and Prasoon Tiwari and separately, I realized that if we measured the complexity of the polynomials as the number of non-zero monomials (when expanded as sum of monomials), then with some other trickery you can actually produce deterministic polynomial time algorithms both for determining if the polynomial is identically zero, and reconstructing the polynomial from a number of evaluations in polynomial time.
I figured my algorithm out in brief flash of clarity on a train ride form Naples to Pisa, it May of 1987 after a workshop on the Isle of Capri. I don’t know who figured it out the deterministic algorithms first, but Ben Or and Tiwari got theirs into print first (in the 1988 STOC proceedings), I got it in to a journal first (“Interpolating Polynomials from their Values,” Journal of Symbolic Computing, 1989. The algorithms are different and we came at the problem from completely different directions, which makes it amazing that after languishing for a ten or more years we both came up witha solution within a few days of each other.
When you put these (and earlier results) together and look at problem that drove much of this work, computing the greatest common divisor of a pair of polynomials you have a series of algorithms, which in the worst case were: (a) exponential, then (b) random polynomial time, and then (c) deterministic polynomial time (using a different complexity measure). I’ve been out of touch with this work for a while, but I believe that despite the deterministic polynomial time algorithm, the random polynomial time algorithm that was in my thesis, or a refinement of it, has better practical performance and is preferred.
Later Erich Kaltofen and Barry Trager extended the results to rational functions, which lead to a whole sub-field of symbolic computation, “black box” computing, where algebraic expressions are not represented as symbolic expressions of variables but as black boxes that return the expression’s value when evaluated at a point.
Richard,
Thanks for this comment.
dick lipton
Thanks for this interesting post about this important lemma. According to “Finite Fields” by Lidl and Niederreiter (Theorem 6.13 and chapter notes), it seems that the special case of the result where S is the whole field was originally proven in 1922 (!) by Ore. I wonder if this was really the first instance of this result being proven 🙂
1) I think there are also some profane reasons why a result acquires some name. Schwartz Lemma is bad. There is already a Schwarz Lemma (named after Hermann Amandus Schwarz, rediscoverer of the “so-called” Cauchy-Schwarz inequality). And nobody wants to depend on such delicate distinctions as an extra letter t. (On Google, the number of hits for Cauchy-Schwartz is more than 20% of the hits for Cauchy-Schwarz.)
Schwartz-Zippel-DeMillo-Lipton Lemma is impossible. Nobody wants to use such a monstrous name. Three-term names are bearable but they already tend to become acronyms: CYK algorithm, AVL trees, AKS sorting network, LYM inequality. SMAWK algorithm. Schwartz-Zippel sounds just fine.
2) I don’t see the bounds that are mentioned in the above discussion in those papers (except Zippel’s). In the DeMillo-Lipton paper, we read (adapting the notation) the bound in the product form
Pr(nonzero) >= (1 – d/|S|)^n.
Of course, this is >= 1 – nd/|S| but this is weaker than what is written in the paper. (The proof actually goes through when d is taken as the maximum degree in ANY ONE VARIABLE, which would reproduce Zippel’s result). Schwartz has a much more refined bound, where d1,d2,…,dn is taken as the degree vector of a lex-maximal monomial, and the ranges may have different sizes. The commonly quoted form of the Schwartz-Zippel lemma: Pr(nonzero) >= 1 – d/|S|, appears nowhere in his paper. (When you look at the proof, you see that a more careful accounting would give a bound in product form, which would subsume Zippel’s bound as well.)
3) And just to set the record straight, @Stasys: Noga Alon did NOT derive the Combinatorial Nullstellensatz from Hilbert’s Nullstellensatz. It has stronger assumptions, a stronger conclusion, and an easy proof.
Dear Prof. Lipton,
The PhD thesis of Daniel Edwin Erickson from 1974, “Counting Zeros of Polynomials over Finite Fields” already contains this Lemma: http://thesis.library.caltech.edu/4061/1/Erickson_de_1974.pdf
See the first main result in the Abstract and put s = 0 there.
So, he might be the first one to ever write down this result. In fact, his result is a generalisation of the Schwartz-Zippel-DeMillo-Lipton lemma.
I just noticed Ashley’s comment above. Indeed, Ore might be the first one to write down this result.
Meanwhile, Anurag Bishnoi (who commented above on April 19, 2015) has published the joint paper On Zeros of a Polynomial in a Finite Grid: the Alon-Furedi bound together with Aditya Potukuchi, Pete L. Clark and John R. Schmitt. It formulates and proves a very appropriate common generalization of Alon-Furedi, Schwartz-Zippel and other theorems, is well organized, easy to read, and very inspiring.
” In the title of this note, we honor the tradition of omitting DeMillo and Lipton.” – from https://arxiv.org/abs/2305.10900.