How To Add Numbers
It’s harder than you think

William Kahan is a numerical analyst and an expert on all things about floating point numbers. He won the 1989 Turing award for his pioneering work on how to implement floating point computations correctly. He has also been a tireless advocate for the care needed to avoid insidious numerical bugs, and his strong feelings come out in a 1997 interview for Dr. Dobbs’ Journal.
Today I want to talk about one of his results on how to sum a series of numbers.
It sounds trivial, but is really a difficult problem when inexact arithmetic is used. Since computers almost always use a fixed finite precision, the problem arises all the time, every day. Another view of adding up numbers is studied by Alexei Borodin, Persi Diaconis, and Jason Fulman in their paper on On adding a list of numbers: it is in the Bulletin of the AMS. They study the carries required—perhaps we will discuss this another time.
I must say that I have the pleasure of knowing Kahan, and have discussed him before here. He is the most articulate person I have ever met, the most knowledgable person about numerical computation, and an extremely interesting person.
Storing Numbers
Of course computers can only store finite representations of numbers. This does not mean that computers cannot manipulate 



for some large 
The difficulty with fixed point representation is that division is a major problem. What is 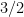

where 



It is interesting, to me, that very early computers used hardware to implement floating point type systems. The Z3 of Konrad Zuse used them, and also implemented the square root operation in hardware. This machine was electromechanical:

The Sum Problem
A fundamental problem is that there can be rounding—see this item als from Dr. Dobbs’ for this example:

but

Of course this shows that addition with rounding is not associative. It also shows that while the two answers are different 
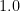
Thus, the main question is can we do better? The answer is yes.
Solutions
Let’s make the problem into a clean formal problem: Given a list 


is as small as possible? The above example shows that the trivial algorithm of adding up the numbers in order

is definitely not the optimal way.
This suggests that we use some kind of cleverness in either reordering the numbers or in keeping track of additional information. Of course, since this is such a basic problem, we want our algorithm to operate in time close to linear time—we want the number of basic operations to stay close to 
The state of the art is that there are algorithms that compute good answers to the sum problem. Some trade running time for accuracy. One of the simplest uses sorting to rearrange the numbers. Kahan himself developed an algorithm that achieves error growth that is bounded independent of 
One recursively divides the set of numbers into two halves, sums each half, and then adds the two sums. This has the advantage of requiring the same number of arithmetic operations as the naive summation (unlike Kahan’s algorithm, which requires four times the arithmetic and has a latency of four times a simple summation) and can be calculated in parallel. The base case of the recursion could in principle be the sum of only one (or zero) numbers, but to amortize the overhead of recursion one would normally use a larger base case. The equivalent of pairwise summation is used in many fast Fourier transform (FFT) algorithms, and is responsible for the logarithmic growth of roundoff errors in those FFTs. In practice, with roundoff errors of random signs, the root mean square errors of pairwise summation actually grow as

Can One Be Perfect?
James Demmel and Yozo Hida proved several interesting further results in a cool paper in 2002. One is that under reasonable assumptions they get the summation exactly when the answer is zero. This is a quite interesting property for those of us in theory.
It suggests a definition: Let 

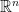
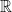



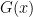

This is a strong property of an algorithm: if the answer is possible, then the algorithm does indeed get it. The algorithm by Demmel and Hida achieves this for the special case of summation for the special value 
One idea I had is to run the fixed-point parts of the calculations modulo 
Open Problems
What is the cost of making an algorithm perfect? What happens for more general type arithmetic computations? Are there similar methods that reduce the error, yet keep the computation cost about the same?
[fixed exponents in equation]


Can you cover functional encryption sometime? Is there a future for it?
There’s a bug in your section called “The Sum Problem.” You meant to write 1.0*10^10 or 1.0*2^10, not 1.0^10.
Right, the Dobbs article has it as “1.0e10”.
Yes—thanks.
Arbitrary-precision command-line confection:
It’s great to live in a century in which arbitrary-precision numerical experiments are astoundingly fast and amazingly cheap. Thank you, William Kahan!
This is certainly a very hard question! To some extent, it even constitutes a clever rewording of the P vs. NP problem…
Reblogged this on Pink Iguana and commented:
rjl on compensated summation
Look,
“$ONE-IN-THREE \ 3SAT$ is the problem of deciding whether a given boolean formula $\phi$ in $3CNF$ has a truth assignment such that each clause in $\phi$ has exactly one true literal. This problem is $NP-complete$. We define a similar language: $ZERO-ONE-IN-THREE \ 3SAT$ is the problem of deciding whether a given boolean formula $\phi$ in $3CNF$ has a truth assignment such that each clause in $\phi$ has at most one true literal. Indeed, $ONE-IN-THREE \ 3SAT \subseteq ZERO-ONE-IN-THREE \ 3SAT$. In this work, we prove $ZERO-ONE-IN-THREE \ 3SAT \in P$.”
in,
http://hal.archives-ouvertes.fr/hal-01070568
is very interesting, isn’t!!!!