Einstein And The P≠NP Question
A post in CACM on the claimed P=NP proof

Moshe Vardi is the editor-in-chief of the CACM. He has done a great job in the last few years changing the publication and making it one of the great ones in Computer Science. He also the “Vardi” in the Immerman-Vardi Theorem.
Today I just one to thank him for the chance to write a guest post a week ago. I thought you may not have seen it and might want to read it.
The post was on the claimed proof of P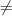
The CACM Post
Last Sunday I planned to relax and read a book when I made the mistake of checking my email—never check your email on a Sunday. Among the usual messages was one from the eminent logician Harvey Friedman. It contained an attachment from Vinay Deolalikar, a researcher at Hewlett-Packard Labs in Palo Alto. The attachment was a 100+ page paper that looked serious, was serious, and had the elegant and short title “P
“this looks like a serious effort.”
Steve is a Turing awardee, a winner for discovering the very same P
I write a blog, along with about 126 million people who do the same. Mine is on complexity theory, and so this claim was something that I felt I needed to write about. There are several other blogs on complexity theory: the best and most famous are Scott Aaronson’s blog, Lance Fortnow and Bill Gasarch’s blog, and Terence Tao’s blog . Even though I knew they would be discussing Deolalikar’s paper, I felt I could not avoid getting involved—my blog after all has “P
My Sunday was gone, and as it turned out, so was the rest of the week. I kept reading the paper, sending and getting emails, and writing posts: all in an effort to report on what the theory community was doing to understand the claimed proof. Was the famous P
Perhaps the biggest surprise was that a lot of people do care. One lesson we learned is there are hundreds of thousands of people who were interested, there were hundreds of people who were willing to write thoughtful comments, and there were a number of superstar mathematicians and theorists who were willing to work hard to get to the truth of what Vinay Deolalikar claimed.
What is P
The rest is here
Open Problems
If you read the post do you like the analogy to 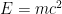


Nice overview article. I especially liked your simple explanation of how statements of impossibility are inherently more difficult to prove than positive results.
Two small notes. I think Steve Cook wrote: “This appears to be a relatively serious claim to have solved P vs NP.”, and his email was sent to their theory group in UofT (which does not seem to me to be an unusual practice inside a department, I would probably do the same thing i.e. I will forward stuff that seems interesting to people in my department.) As far as I know he didn’t send his email to Harvey Friedman (I may be wrong here, but that is what I understand from Harvey’s email to FOM about this) so this remark was not intended to to be read by you or Harvey. Harvey or you can take his comment seriously only if he sent it directly to you. The audience is important here, I may say to my students that this stuff is interesting, this does not mean that I would tell the same thing to you. Currently my personal opinion is that people should not have forwarded his remark and every person who has forwarded that remark is responsible for the hype.
Anonymous
To set some record straight. I got direct comments from Steve and others did not directly quote that said the same thing—it is serious. So I did do my checking the best I could under the situation.
dick lipton
Dick,
Sorry for the tone of my comment. I didn’t know that you have got direct comments from Steve Cook and my comment was based on what you wrote in the post (that you received it from Harvey Friedman). I personally think that this was an interesting and useful experience independent of the correctness of Deolalikar’s claim (which I was very skeptical of for various reasons similar to those mentioned by Scott on his blog). I should thank you and others who have commented here and on other blogs about this stuff. I have learned a lot about topics that I was not familiar with in a very short time because of your effort. I just felt that it is a bit unfair to put all the blame of the hype on Steve Cook. The truth is many of us are too eager to see this questioned settled and because of this we “jumped” on the smallest possible evidence that this is serious. In stead of judging the quality of the paper ourselves and express our own opinion many of us preferred to just forward his one-line comment. The version I received was what I wrote above which didn’t seem to be a strong comment: “appears to be” and “relatively serious claim”. Sure, this is a serious claim relative to those we see all the time on arXiv.
I also feel strongly that Steve Cook’s comment (on D’s claimed proof) , however innocent or casual, was mostly responsible for this hype.
On its own this paper would have never got this level of attention or publicity.
What I question most is the skewed attention. Was it fair (and worth) devoting so much of resources from some very “high powered” researchers to one paper, while so many other “claimed proofs” are simply ignored?
For my 2 cents, I think it’s a matter of “Indirect Speech Acts” not translating to e-mail or Internet. Steve Cook’s statement is clear and denotatively correct: it uses appears to be and relatively as qualifiers. In person it would be completely clear that he meant them as subtractive, meaning: this has some right appearances, but don’t jump to conclusions on the claim until we look at it. By Internet, however, they were read as augmentative, as if putting Cook’s imprimatur on it. But as part of necessary human learning on communication by Internet (there should be a course on this alongside Lit101), I think it has to be agreed that the responsibility here is on the receiver not the sender—because there was nothing inaccurate in what Steve Cook said.
Steve Cook’s remark in Harvey Friedman’s email to FOM is exactly the same as the one I wrote above. Friedman also wrote in his email that: “I received it a bit down the food chain – not directly from Steve.”
I received what I sent to Dick Lipton from a junior (recently tenured) Italian mathematician who does not work in complexity theory (does have some papers in learning theory). Very far removed from the Toronto theory operation. So when I received this, I assumed that it must have already had massive distribution. Since I knew about Dick’s highly respected and terrific blog, it was very natural for me to send it on to him. I was assuming that he had long since had a copy (i.e., for maybe a day or more), and I was expecting to hear some real buzz. Well, the deafening buzz came soon later!
About the analogy and the difficulty in proving negative predictions, I thought I would mention that we do know of some far-reaching negative predictions that have simple (and clever) proofs. Replace Q by “the uncomputability of the halting problem” in your text and everything you say on how hard it is to prove Q would seem to apply to it, with the little difference that we do know of a 5-line simple proof (that we teach all the time). Remarkably, that proof did teach us a lot about the nature of computation, which aligns with your thesis that proofs teach us stuff. Among other things it taught us that programs that sometimes hang need to be allowed, no matter we like it or not, in any general-purpose programming language.
Richard,
Congrats, you managed to not write a post on the topic on Sunday – you did it on Monday 🙂 Hope you had a peaceful Sunday at last. Thanks for all the writing on this, though. The analogy to E=MC^2 was nice in highlighting the difficulties of positive vs. negative proofs. I like Albert’s above comment about the halting problem. Do similar comparisons (as you made) apply to upper bounds vs lower bounds for problems? Also, is it necessary that negative proofs, once discovered have to be `elegant’ (in a certain way) since case analysis is possibly hopeless.
I’ve learned a lot & had a really good time the last two weeks … first with Vinay Deolalikar’s claimed proof, followed by many wonderful discussions of the ICM awards. To complete a trifecta of TCS/QIS goodness, coming up next weekend is the Barriers in Computational Complexity Workshop II (at Princeton).
Speaking as an engineer, one of the things that would greatly help me to enjoy the Barriers conference, would be a better understanding of a striking asymmetry between the complexity classes P and NP, that so far I have not seen discussed anywhere in the mathematical blogosphere.
This asymmetry is readily apparent in Stephen Cook’s Statement of the P versus NP Problem (available on-line at the Clay Institute). Namely, the word “check” and its variants occurs 10 times in the formal problem description … always with reference to the class NP … never with reference to the class P.
This asymmetry seems unnatural to engineers, because “checkability” is an attribute that we require of *all* our algorithms, regardless of their complexity class. Somehow P escapes this requirement … but NP doesn’t … how does that work, exactly?
Despite feeling that above might well be a foolish question … or have an answer that’s obvious to TCS experts … I’m going to ask it anyway … if for no other reason, than it’s relevant to the coming Barriers II Workshop.
John, I don’t understand your question. Suppose L is a language and you want to know if X is in L. If L is in NP and X is in L, then there is a short certificate C, so that given the pair (X,C), you can quickly verify that X is indeed in L. 3SAT is an example (just write down the satisfying assignment as a certificate) and 2SAT is another example (same way). If L is in P, you can efficiently verify X’s membership without needing the certificate. For example, there is a clever way to do that for 2SAT without the certificate, but no way is known for 3SAT. The P vs NP question asks, in one way to put it, whether in the 3SAT case, the certificate is indispensible (P!=NP) or if there is some as-yet-undiscovered even cleverer way to do without it (P=NP). I.e. P vs NP asks whether the ability to check membership using a certificate implies you can also check membership without the certificate.
As an example of why the certificate might not be enough for some problems, think of a complicated chess position. You say it looks about even and I say White is winning. But there is no simple series of moves I can show you that demonstrates the win. I have to go over a whole tree of sequences of possible moves and countermoves, and show that White wins in every variation. That tree is exponential in size, not a short certificate. So we would say that (generalized) chess is (probably) not in NP. It is however in PSPACE. It turns out that we are in such a dismal state of “technology” right now that we don’t even know that P!=PSPACE, much less P!=NP. As far as lower bounds proofs are concerned, we might as well be living in caves 😉
Thank you, none! And by the way, may I say that “none” is a classy name for an anonymous post. Its latin variant is “Nemo,” meaning “no one”, alternatively (as νέμω) it is Greek for “I give what is due”; this usage was introduced by Jules Verne as the cognomen of Prince Armitage Ranjit Dakkar (and Wikipedia tells the rest). Best … anonymous … blogosphere … name … ever!
For definiteness and clarity, it’s hard to do better han Steve Cook’s Clay Institute problem statement. There we find that everything you say is exactly right, and boils down to Cook’s definition (first equation at the top of page 2) that says in effect “P is the class of languages accepted by some Turing Machine that runs in polynomial time.”
The point of my post is that for logicians this is a perfectly acceptable definition, but for engineers it seems incomplete. For each concrete language in P, we engineers dearly want to inspect at least one concrete acceptance machine, accompanied by a concrete certificate that the acceptance machine runs in polynomial time.
To see how this engineering requirement might create logical problems, we reflect that Cook’s definition of P logically encompasses worlds in which the following statement is true: “P contains languages whose acceptance machines run in polynomial time, but not provably so.”
For us engineers, that’s a world whose definition of P is logically valid, but not natural … unless every acceptance machine provably runs in polynomial time, and that proof itself can be constructed in polynomial time. But this is not the world we live in AFAICT (although we engineers would be exceedingly pleased to find ourselves living in such an easily checkable world).
For reasons that I’ve posted about on Scott Aaronson’s blog, these issues of naturality and checkability will likely come to the fore at next week’s Barriers II conference, at the intersection of complexity theory and experimental physics.
More broadly, perhaps we should not be surprised that the struggle for clarity in these barriers-related issues is mighty tough: the mathematical definitions have to be natural, the proofs rigorous, the physics well-understood, and the experimental datastreams checkable … all four at the same time.
This challenge is tough … and it’s important … and that is why it’s fun. 🙂
John, I have to admit I’m somewhat confused by your comments.
Any language in P is automatically in NP. That is, anything that can be decided in polynomial time is automatically checkable in polynomial time.
The question is whether every language in NP is in P. Or, whether everything that can be checked in polynomial time is also solvable/decidable in polynomial time.
In other words: P is contained in NP. The question is whether this containment is strict, i.e. is NP contained in P? If so, then P=NP; otherwise, P!=NP.
Checkability is naturally incorporated in the class P, because everything in P is automatically in NP.
Daniel, when we engineers receive a software package that (in effect) asserts that it accepts a language in P, it is a pretty considerable challenge for us to check this claim … or in engineering-speak, it is challenging for us to validate the design and verify the implementation (V&V) of codes that claim to accept languages in P.
What happens in practice, is that engineers require that mission-critical codes be accompanied by a V&V certificate. That in practice these certificates are deplorably non-rigorous must be admitted. Engineers never construct even non-rigorous certificates ex post facto, because in practice this proves to be infeasibly hard. For this reason, mission-critical languages whose acceptance codes are unaccompanied by a V&V certificate are simply rejected out-of-hand … and even certified codes too often run forever (or return answers that are just plain not what the certificates claim).
So one way to phrase my question is, is V&V fundamentally easy? Can we accomplish it via some concrete, PTIME algorithm?
If the answer is “yes” … well heck … that’s terrific news for the software industry! If the answer is “no” … then is P—for engineering purposes—a natural complexity class?
Hopefully I haven’t gotten some key point(s) wrong in framing these questions … if so, my apologies are tendered in advance.
Whether one can see if a Turing machine runs in polynomial time is a non-issue for defining the class P. We may as well just define P to be the class of languages accepted by pairs (M,k) where M is a Turing machine and k specifies a clock, i.e with the interpretation that should M run for n^k+k steps, it immediately rejects.
Oh, I see. That was the light bulb moment I needed, thanks. 🙂
I still think P, as defined, serves a useful engineering purpose though: at least insofar as the initial design goes. No one (worth their pay) is going to try to write PTIME software beginning from the framework of pseudocode for an EXPTIME algorithm.
Sure, P itself might not directly help you so well with V&V (and I’ll admit my naivety here, but — I assume it’s impossible to verify a program is in P because you embed the Halting Problem somewhere in there), but practically speaking, it still helps filter what arrives in your hands from up the line. If nothing else, it’s a decent (loose) upper bound on the types of things you’ll actually be asked to verify, which can’t hurt.
I agree that the actual checking process is a very interesting problem, however.
Yes I was also a little bit perplexed by the idea that negative proofs are supposed to automatically be hard. The halting problem is an immediate example. Or B. Pearce’s famous statement that type systems for programming languages are syntactic methods for proving the absence of certain program behaviors. There are all kinds of P vs NP proof strategies that had reasonable hope of success, but whose details didn’t work out. There are approaches like GCT that still offer hope, if we can get a grip on their complexity.
It does seem bloody hard in general to quantify over Turing machines and prove anything useful about lower bounds. But that seems like a failing of “proof technology”, not any indication that the bounds aren’t there.
I have been wondering (I posted on Scott’s blog about this) whether it might be better to start lower: quantify over P and then prove some NP problem is not in it. I.e. I wonder whether an approach like the following is completely silly: use descriptive complexity sentences or the Cook-Bellantoni syntactic characterization of P (either of these is a complete enumeration of codes for all the languages in P) to turn P into an ordinal notation system, so each code for a P-time-decidable language corresponds to a countable ordinal α below some limit ordinal (that might be pretty large, and the mapping from codes to languages is surjective but not necessarily injective). That means concoct a suitable well-ordering on (say) parse trees of the codes. Let L be some language that you want to show is in NP minus P, like maybe L=3SAT. The hope is to prove combinatorially that for all ordinals α in the ordering, if language α isn’t L, then language α+1 also isn’t L, and ensure through the construction that the languages for the limit ordinals also aren’t L. Then presto, P!=NP by transfinite induction. This seems to get around most of Scott’s “8 signs that a P vs NP proof is wrong” (i.e. the combinatorial induction step actually uses precise details of both L and the ordinal encoding, and therefore doesn’t work for 2SAT even if L is 3SAT; it “knows about” every language in P by construction; the whole thing operates inside the actual P and not some relativized version so BGS isn’t a barrier; it sidesteps having to say anything about lower bounds on fragments of P for the same reason; I’m not sure but I think it gets around arithmetization/algebrization because the large countable ordinals can’t code naturally as polynomials over finite fields, etc. Of course there’s the little matter of actually supplying the details, which I’ll leave as an exercise 😉 I imagined in the other post that the induction step is a monstrous computer calculation like the proof of the 4-color theorem (and that it’s only for an artificial PSPACE problem, to prove P!=PSPACE rather than P!=NP), but the hope is that it would look like the typical reductions from old-time NP-completeness proofs. Maybe the natural-proofs barrier stops it? That’s the one that would seem to apply.
I think the above kind of proof is still what Scott would call a “fool’s mate” and therefore it seems obvious to me that it’s already been tried and failed (or else it’s just silly for some obvious reason that I’m too clueless to spot, which is very possible). But I wonder why I never hear about approaches like this in general. It really seems pretty direct. Aren’t the proof theorists thinking about P vs NP like everyone else? Syntactic characterizations of complexity classes just seem incredibly powerful for separations, but nobody seems to do anything with them.
B. Pierce, not Pearce. (Sorry for the quite unrelated comment.)
P!
I turned to this site about Einstein and P not equal NP It is all too clear that the post
war peiod learned all about the problem of a formula E equals mc squared which was not so easy to prove for all atoms just like that. It is an engineering science problem To close a question on Universal assumption is not to mean the engineers dont have problems Thats what I am confirming The modern logic trials are about computors and choice of methods to close down on the lower boundary further if possible. It is a fact that will always be true
irrespective of the main goal of the open dispute. Your Gods go with you friends FAREWELL
I am actually confused by Verdi’s analogy.
From what I had understood (well, it was a long time ago, and I don’t remember math steps from ages ago like Dick Lipton does), the fact that light’s speed is absolute in any reference frame ( and = c ) is one of the postulates and not a derived result.
E=mc^2 on the other hand, is derived – and the derivations are fairly elementary.
[I think Terence Tao had a really lucid post on it some time back].
The analogy seems incorrect; but I might be wrong.
John Sidles at 9:04AM: looks like this blog doesn’t allow reply nesting below a certain level, whichis probably wise 😉
Practical algorithms with unknown complexity are useful in real life. The simplex method for linear programming was a famous example. It empirically seemed polynomial and was used for lots of real problems, though no rigorous analysis of the running time existed. Then people figured out there was worst-case exponential behavior, so it was an exponential algorithm, though the worst cases didn’t seem to happen in practice. It took decades til it was proved polynomial in the average case, and the Nevanlinna prize this year was awarded for figuring out what happens at cases that are nearby to but not at the worst cases.
Cook’s definition of P logically encompasses worlds in which the following statement is true: “P contains languages whose acceptance machines run in polynomial time, but not provably so.”
For us engineers, that’s a world whose definition of P is logically valid, but not natural … unless every acceptance machine provably runs in polynomial time, and that proof itself can be constructed in polynomial time.
I don’t know why you say that. Hint: there are plenty of machines that run in constant time but not provably so (that is the halting problem). In engineering, almost everything is empirical and nothing is proven. That’s why those of us who want proofs go into math instead of engineering ;). Anyway, it’s my impression (maybe wrong) from Bellantoni’s thesis that P is recursively enumerable and that the enumeration effectively gives a polytime machine for each language in P. If that’s correct, you might have a machine M1 that runs in polynomial time but not provably so, but in that case there is another machine M2 that provably runs in polynomial time and recognizes the same language as M1. Of course you would not be able to prove that the two machines recognize the same language.
Even with provability things can still be pretty bad. Maybe there’s a language L that is provably in P, so there is an O(kn) algorithm for some n, but n is so large that there’s no effective way to write it down (i.e. there is no Turing machine that computes it). You could only describe n in terms of something like the busy beaver function, and maybe not even that way.
The html processing didn’t accept the sup tag for writing superscripts. For O(nk) above please read O(n^k).
none,
To get math use latex . The key is the word latex.
Thanks for your cordial reply, none! I’m not going to try to comment intelligently upon it—because … uh … that’s utterly beyond my capabilities—but definitely you’ve given me a head-start by pointing toward topics to think about.
Perhaps mathematicians aren’t so different from engineers, in the sense that we all are dearly fond (in Dick’s phrase) of “proofs that tell us why.” Your remark “even with provability things can still be pretty bad” is apt: engineers respect concrete construction, and conversely, a P-language that is promised to exist, but whose accepting machine requires greater-than-P resources to construct and/or to check, is perhaps not all that instructive as a “proof/algorithm that tells us why.”
Should the engineering community be concerned, therefore, that Reinhard Selten’s remark “game theory is for proving theorems, not for playing games” might apply also to the problem P≠NP? Is P≠NP not a natural problem—in some sense connected with feasible checkability—that engineers should care about?
There’s a set of folks who are passionate about answering such questions … and a set of folks who thoroughly understand the ramifications of such questions … and a set of folks who are immensely skilled at explaining such questions. If we are lucky, then the intersection of these three sets has at least one person in it … and for sure, that person isn’t me! 🙂
John, you should read Russell Impagliazzo’s “Five Worlds” paper if you haven’t:
http://www.cs.ucsd.edu/users/russell/average.ps
My personal view is that P vs NP research is not of much concern to traditional branches of engineering like (say) mechanical engineering. The actual situation (IMO) is that SAT takes exponential time whether we can prove it or not, so the presence or absence of a proof doesn’t really affect how engineers deal with SAT problems. They have to use exponential or heuristic algorithms either way. Of course in the extremely unlikely event that P=NP and there is a fast (e.g. linear time) practical SAT algorithm, then everything in every engineering topic goes out the window, but IMO that’s not going to happen.
In software engineering, P vs NP may be more relevant. The reason is the biggest challenge facing software engineers is program reliability, and carefully-designed programming languages are among the most useful tools for writing reliable code, and advances in programming languages these days are informed more and more by mathematical logic, and P vs NP is at its center a towering logic problem that reaches into all sorts of areas. We “know” perfectly well that P!=NP but we have not developed good enough reasoning techniques about program behavior to create a proof. If can develop those techniques, we may be able to use the new knowledge to create better tools and languages that let us embed high-level specifications into program code, such that a compiler can check (without running the program) that the program actually does what the specification says (the way we do that now even in “advanced” languages like Coq is still very primitive). In that sense a P!=NP proof would not be directly useful “technology”, but the knowledge gained from proving it would be “meta-technology”. Sort of like how pursuing the moon landing advanced the development of airplanes and computers.
I better add that the above spew about P/NP and software is not any kind of accepted wisdom, it’s just the free-association spouting-off of an anonymous internet nerd (me). But maybe there is something to it.
@Sidles:
“So one way to phrase my question is, is V&V fundamentally easy? Can we accomplish it via some concrete, PTIME algorithm?”
If I understand your question correctly, then the answer is provably no.
The following language is undecidable: Given a program P, does it run in polynomial time on all inputs?
It follows from Rice’s theorem which says that any nontrivial property of languages is undecidable.
Thank you again, none (if you are the same “none”). Yes, Impagliazzo’s paper is terrific. For me, the question “Is P natural?” grew out of the Impagliazzo-inspired question, “Would a world of strictly validated and verified languages be at least as dumb as Impagliazzo’s world Cryptomania?”
After sleeping on it, this class of question is looking increasingly tough (to me). For example: if the answer to “Is homomorphic encryption feasible?” is “Yes”, then the answer to “Is P natural?” is in some sense “No” … on the grounds that P includes homomorphically encrypted codes that (by design) resist efficient verification and validation.
There are some questions that are so tough as to be unsuited to the blogosphere, because they are too far beyond our present state-of-understanding … perhaps “Is P natural?” is in this exceptionally tough class.
Yes, that is me; there is only one of me, or rather, none of me.
What do you mean by “is P natural”? Do you mean in Scott’s sense that C is a natural class if C^C=C? Then yes P is natural, while NP is probably unnatural.
Looking at some of your other comments it looks like you’re fairly well-informed of high-level consequences of the P/NP question, but a bit weak on the basic definitions and proofs. The classic textbook (actually a fairly thin paperback) is Garey and Johnson, “Computers and Intractability”, which is pretty accessible. It defines P and NP, and goes through Cook’s original proof that SAT is NP-hard. It’s worth studying that in detail. Then it does reductions from a bunch of other classic problems to SAT. The book is pretty old by now but at the basic level it still is probably pretty good. Maybe others here have other recommendations.
Oded Goldreich has a new book with the advantage that drafts of the first few chapters are online. I haven’t read them but a quick peek looks promising: http://www.wisdom.weizmann.ac.il/~oded/bc-book.html
Quantum Tennis Match:
Whether P runs in polynomial time is not a property of the language it accepts, so Rice’s theorem doesn’t apply directly. Being only an amateur on this stuff, I don’t recall whether there is a different proof of it being undecidable.
@Ørjan Johansen:
If I remember correctly, there is a stronger version of Rice’s theorem which can be used to show that it is impossible to decide if a program runs in polynomial time. The intuitive reason is as follows: any TM for an r.e. index set needs to make its decision based only on executions (for finite amount of time) of a given program on finitely many inputs, more formally any member of the r.e. index set needs to have a finite restriction inside the set, and no finite function is in P (functions in P are total).
The preceding comments, in aggregate, are a considerable advance toward rigorously specifying a dumber-than-Impagliazzo world, that was once only an engineer’s fantasy. For this I am very grateful … grateful especially to be having considerable fun (which for me is the main point). And I don’t mind confessing that there is still much that is murky (to me, anyway) regarding the natural role(s) of checkability in the P≠NP problem.
Thank you for the references, none! Issues associated to verification and validation (variously “V&V” or “checkability” or “checking relations”, etc., depending on the discipline) have been ubiquitous across the blogosphere this past two weeks—beginning with Vinay Deolalikar’s claimed proof, obviously—and they’ll be ubiquitous too at next week’s Boundaries II Workshop.
I guess I had always read the standard definition of P without ever noticing that it makes no explicit reference to V&V, whereas this attribute—in the form of “checking relations”—is at the heart of the definition of NP (at least, as Steve Cook’s problem statement has it).
Every discipline has its own notions of naturality … what helps technologies to work is natural to engineers … what helps proofs to work is natural to mathematicians … and so we can hope that there is a substantial overlap of these ideals of naturality … but this is not guaranteed.
Essays that help to establish shared ideals of naturality across communities are broadly welcomed by all communities, and definitely I wish someone (not me!) would write one on this topic.
You mean THIS week’s Barriers II workshop! I’m about to fly out now – hope to meet you there if you’re attending.
Also, I think an interesting tangent to the whole V&V thought is the LANGUAGE or MODEL underlying the actual product you’re trying to check.
When computing theorists/mathematicians work with the class P, we’re assuming the underlying model is a Turing machine. The overwhelming majority of the time, we don’t mention Turing machine operations; rather, we think very abstractly about the idea of operations on a Turing machine. (Incidentally, Lipton’s latest post on Quantum Algorithms highlights a very similar phenomenon to what I’m describing here!)
However, when you’re doing V&V on an actual program, the underlying model has changed on you. You’re not dealing *directly* with Turing machines; instead, you’re dealing with C++ or Java, or whatever the case might be.
Two thoughts:
1) Of course the two models are very, very closely related from a theoretical/mathematical point of view. But from a purely pragmatic, engineering point of view, they’re quite different.
2) As Quantum Tennis Match points out, it’s provably impossible to verify that a program (or Turing machine, or…) is PTIME (or accepts languages in P, etc.).
That said, in the engineering context, you have to be further concerned – not just with the runtime of the algorithm in question – but with the expressive power of the language you’re dealing with. Some languages, for instance, can pack very powerful (and costly) algorithms in a very short amount of code. As a simplistic example, it’s possible to write an infinite loop in one line of code in C++.
The thing to keep in mind, though, is that the class P is about formal, mathematical/logical proofs. Rarely do formal proofs actually line up with reality. There are many ways they can help practically (obviously, formal proofs are useful somehow, or no one would spend time producing them!), but I think overly concerning yourself, as an engineer, with the methods of checking/verifying from a “formal” perspective can actually end up hurting your engineering practice! This is absolutely not to say “get out of here, you nasty engineer!” It’s more of: I think I agree with you, that P has a much more limited role in engineering than it does in theory.
Daniel, I’m sorry not to be able to attend Barriers II (Princeton being inconveniently far from Seattle), but I do want to express my thanks to you and to “none” for your thoughtful comments.
As it happens, None’s pointer to Oded Goldreich’s (on-line draft) text provided precisely the engineering-compatible discussion of (in effect) V&V that I have been seeking. Hurrah! In particular, Oded’s discussion of “proof-oblivious verification procedures,” together with (the immediately following) discussion of Section 4.3.3: Is it the case that NP-proofs are useless? was just what I had been looking for.
Thus (for what it’s worth) Oded’s text receives at least one systems engineer’s enthusiastic praise … so much so, that perhaps later in the week I will attempt to retell Oded’s P≠NP narrative from a strictly engineering-centric perspective.
First let me introduce myself. Although I started out my career studying complexity. I ended up spending most of my professional life either as a software engineer specializing in computing languages (language lawyer), or trying to get massive (usually Air Force or NASA) software projects from design to fielding without leaving huge gaps for the squirrels to get in.
John Sidles said: What happens in practice, is that engineers require that mission-critical codes be accompanied by a V&V certificate. That in practice these certificates are deplorably non-rigorous must be admitted. Engineers never construct even non-rigorous certificates ex post facto, because in practice this proves to be infeasibly hard. For this reason, mission-critical languages whose acceptance codes are unaccompanied by a V&V certificate are simply rejected out-of-hand … and even certified codes too often run forever (or return answers that are just plain not what the certificates claim).
So one way to phrase my question is, is V&V fundamentally easy? Can we accomplish it via some concrete, PTIME algorithm?
No, no, a thousand times no. Let me give two particular horrible examples of why V&V is not fundamentally a mathematical problem. The first Ariane 5 was destroyed by ground control after the engines had deflected far enough to cause the stack to break. (The stack is the assembled launch vehicle including all stages. Exceeding the stack’s limits will cause it to break like a chimney falling down.) Although the report on the failure is complete in its details, it does a nice job of obscuring how badly the bureaucrats had blown it. The flight guidance software was developed as an upgrade for the Ariane 4, and was used there without problem. However, the developers of the software were not allowed to see the physical specs for the Ariane 5 to prevent their company from getting a head start in bidding on the Ariane 5.
Do you see where this is going? The original plan for the Ariane 5 called for a hardware test frame and supporting software to “fly” in simulation the Ariane 5 missions before they took place, but this fell behind schedule and went way over budget. So the decision was made to use the well tested SRI system with no changes from the Ariane 4. Bad decision, very bad decision. The physical properties of the Ariane 5 were not the same as the Ariane 4. Different moments of inertia, much higher thrust to weight ratio at launch and during flight, etc.
The exact failure sequence included some software that needed to be running on Ariane 4 in case of a launch abort in the last few seconds before takeoff. This software wasn’t needed on Ariane 5–but changing anything would require doing over the testing that was never done. Right? The cascade from there was inevitable. The error detected by the software was in the “physically can’t happen” bucket. Remember that the Ariane 5 had a higher thrust to weight ratio? For the error to occur on Ariane 4, either the inertial guidance hardware would have to fail, or the rocket would have blown up. So switch to the redundant system–which is busily detecting the same problem, and send the faulty data down the bus to the engine controller so the telemetry can be used to diagnose the problem. Sending telemetry data down the inactive bus to the engines may have been a clever trick, since that data never made it to the engines. But if both channels are diagnostics not flight data? Boom!
What if the timing or flight path had been slightly different, and the unneeded software got disabled before it signaled a problem? The flight would have gotten past the 40 second mark, and if the upper atmosphere was quiet enough, might have made it to orbit. But any wind shear would have started a dance of death. (Well for Ariane 501 anyway.) Remember that the flight guidance software held control laws that reflected the Ariane 4 stack. For small deviations, it would still work, but get the slightest bit from vertical, and the nose will start tracing a widening spiral. Oops, again!
This was a management problem. Right? Well sort of. The management failures prevented those who would have known what was going wrong from even knowing of the problems. But there is the rub. It is easy to show how a system will fail, or did fail given a trace through the system. But like N=NP, you can easily prove a failure mode once you see it–but you have to see it, and that is the NP (or worse) part of the analysis.
Is it possible to develop a programming language that has an associated theorem prover, state all the requirements for the software, then prove that the software meets those requirements? Actually, yes. The limits on the programming language, and the requirements of the theorem prover mean that there are lots and lots of programs that are ruled out. You don’t care, as long as one solution to your requirements is allowed and your programmers can find it.
The Airbus A320 has a very sophisticated flight control system. The pilot and co-pilot for the most part don’t fly the plane, they manage the autopilot. Airbus used a special language (will associated theorem prover) and had two different implementations of the flight software, both of which proved correct against the same requirements. (Why would you have different requirement sets? And it would be silly to fly computers with software that met different requirements. Right? Read on.)
Before the Airbus 32o entered service, at a demonstration at an air show, a plane did a low, slow, gear down pass in front of the crowd. Pulling out at the end of the runway, the tail hit some trees. Three passengers died. Oops! Even bigger oops was that the French didn’t want the crash to affect sales, so they substituted a different black box. (Well, I don’t know that the French were responsible for the substitution, but the recorders were tampered with while in police custody.)
Then came Strasbourg. The fatal flaw in the software should have been figured out during the investigation, but it took another two fatal crashes before investigators figured it out. Set multiple waypoints from takeoff through landing. (Just one is all that is necessary.) Waypoints are usually over radio beacons at a specified height above ground. Also set the intended runway and direction. When the last waypoint is cleared, the autopilot will put the plane on the glide path specified for that runway and direction.
Does that last sentence fill you with chills when you read it? It should. Left out were three rather necessary requirements. First, it might be handy to add “without controlled flight into terrain.” Second, “while maintaining controlled flight” would be useful too. And finally, if the airplane is approaching the runway from the wrong direction, the plane should stay away from that glidepath until it is correctly aligned.
Without those requirements, Flight 148 passed over the last waypoint at 1000 feet above the beacon–the beacon was well above sea level in a mountain pass, so the 1000 feet was AGL, above ground level. But the glide path extended from the runway passed under the beacon. One crew member and five passengers survived. Even though they all testified to the abrupt nose dive the original investigation called it pilot error.
So if you design your system and use the most magical of software engineering tools available today, there is no magic that can insure that the requirements match the real world, and actual hardware the system will be working with.
Incidentally, I am very much a fan of writing programs in readable languages, and rewriting code several times, if necessary, to make it clearer. I happen to like Ada, but you can write good–or bad–code in any programming language. The real reason I like Ada is that I can deal with the exceptions first.
Robert, there’s not much I can add to your very interesting post, except to say that we quantum systems engineers are fully aware that 21st century quantum technologies are following a developmental arc that is startling similar to 20th century aerospace technologies.
Here is a set of references that are particularly relevant to quantum systems engineering (most of which can be found on-line). We can begin with a PNAS review (that I wrote) of IBM’s recent quantum spin microscope experiments titled Spin Microscopy’s Heritage, Achievements, and Prospects.
The PNAS review begins with a reference to a visionary letter that John von Neumann wrote to Norbert Weiner fifty-four years ago (in 1946). A Google search for the phrase “foresee the character, the caliber, and the duration” will find the text of this letter in The Proceedings of the Norbert Wiener Centenary Congress.
As yet, there is no history of quantum spin microscopy—whose development after all will occur mainly in the 21st century—but we can perceive the broad outlines in the literature of aerospace engineering … it is only necessary to substitute “quantum dynamics” for “fluid dynamics”.
It is helpful too to appreciate that designing and operating a quantum spin microscope—or an ion trap, or an NV center microscope, or any quantum device, etc.—is comparably challenging to designing and operating a small satellite in low earth orbit. And low-earth-orbit satellites in-turn are comparably complex to color inkjet printers … which is saying a lot!
To travel back in-time, one illuminating systems-engineering reading-list is JPL’s manual Design, Verification/Validation and Operations Principles for Flight Systems (2006, DMIE-43913); S. B. Johnson’s history The Secret of Apollo: Systems Management in American and European Space Programs (2002); R. Booton and S. Ramo’s IEEE review article The development of systems engineering (1984), Neil Sheehan’s A Fiery Peace in a Cold War: Bernard Schriever and the Ultimate Weapon (2009, see particularly Sheehan’s in-depth discussion of von Neumann’s role in organizing the SMEC conference of 1953); and Denis Serre’s recent Bull. AMS review Von Neumann’s comments about existence and uniqueness for the initial-boundary value problem in gas dynamics (2010). As Serre describes, it was at this 1949 conference that von Neumann set forth the mathematical and computational toolset that enabled SMEC and all that followed.
To a systems engineer, these various sources tell one central story: the essential role of solid mathematical foundations in creating large enterprises. In the 20th century vast enterprises were constructed upon classical dynamical foundations that were largely laid by by von Neumann; now in the 21st century we are conceiving similarly vast quantum enterprises … also upon dynamical foundations that were largely laid by (who else?) von Neumann. It’s fun! 🙂
Robert,
You have missed a fundamental fine print in the [V& V is fundamentally] “easy” part.
n^100 is also polynomial– theoretically. But in practice the difference between O(C^n) and O(n^100) will be noticeable only for sufficiently large values of n (and of course depending on the constant C)
So how can you determine if your V&V process was not actually “easy” from a time complexity point of view?
Unfortunately most CS theoreticians also overlook (or ignore) this point when they start lecturing on the consequences of P==NP.
An algorithm with a time complexity of O(n^100) is totally useless for most practical applications. Even O(n^20) would have very limited use in the foreseeable future.
Moreover, just because a P-time algorithm has not been found, it does not mean it does not exist.
The V&V domain faces the same issue (of verification algorithm in P-time ) as the original “problem”, it is just that it has not arisen in the NP-complete problems we have discovered so far.
Has anyone tried to come out with a formal definition of the V&V problem?
By the way, Robert (Eachus), my colleague Jon Jacky is familiar with your work on software reliability and engineering; he praises that work and sends you his respectful regards.
John, what file and page number of Oded Goldreich’s book are you looking at? In the bc-3 draft, section 4.3.3 is about something different and I can’t find the stuff you mention.
If you want to see the current practice in one style of software verification, you could look at “Certified Programming with Dependent Types” by Adam Chlipala: http://adam.chlipala.net/cpdt/
None, let’s synchronize for definiteness on Oded’s bc-3 draft (click here), which AFAICT is the most recent.
Then the referenced passage is on the page numbered 53 (which is the 79th page of the PDF file), beginning with the paragraph preceding Section 2.3.3 (not 4.3.3 as I originally typed).
Some of these same ideas are covered in Oded’s essay On Teaching the Basics of Complexity Theory, which also can be found on his web site. There’s a ton of great material there!
Dear Professor Lipton,
Your use of the word *obvious* to describe current algorithms for NP-complete problems (say, 3SAT) is misleading. Here is why:
1) There is the obvious *search the entire space* one assignment at a time algorithm. Lets call it the *obvious* algorithm
2) There are current SAT algorithms that are much smarter (and very useful). They are not obvious.
Granted they have the same worst-case complexity as the obvious algorithm. However, thats missing the point. If we just listen to your analysis, then it will lead to a very depressing picture. However, if you connect with reality the picture is much more optimistic (and constantly getting better). I am sure you and others are aware of the rapid progress in practical SAT technology.
This brings me to my most important question:
1) Why are we so obsessed with worst-case complexity? It makes perfect sense to be obsessed with it when we are talking about algorithms that have worst-case of n^3 or below. However, beyond that worst-case doesn’t help at all. As a systems builder, worst-case complexity beyond n^3 doesn’t tell me anything. Often, I can come up with bag of heuristics that solve these problems very efficiently, and they tackle 90% of the inputs that occur in practice. When they don’t, systems engineers pull some approximation trick.
If you look at the practical SAT community, they are able to solve problems that were considered impossible even 5 years ago. And, these heuristics are NOT *obvious*.
2) This whole obsession with worst-case beyond n^3 is unhealthy. We need a different measure. Average-case doesn’t cut it either. I wish I knew the answer. Maybe it is parametric complexity.
3) I also urge the theoreticians to talk more with practitioners. Otherwise, a lot of things being discussed may become less and less relevant.
This whole obsession with worst-case beyond n^3 is unhealthy. We need a different measure. Average-case doesn’t cut it either. I wish I knew the answer. Maybe it is parametric complexity.
I haven’t looked at this issue since the 90’s but an anecdote may help. Most provably best algorithms in P not only take polynomial time, but less than n^3 time for any reasonable measure n.
I ran into a case where I needed to solve a variation of the assignment problem. The assignment problem is given two sets m and p of equal size, assign a pairing between the two sets such that the sum over some function, (call it f) on the selected pairs is minimized. The classic example is a set of people and jobs such that you have the best possible net fit to all the jobs. In my case, I had three added difficulties. The size of the two sets might be different, and even then the best assignment could leave one or more of the members of the smaller set unassigned. Oh, and I had to solve the problem in a few hundred microseconds.
The first algorithm proposed by the contractor worked in time (size(m)+size(p))^8. Doable, but not very useful. First I used some theory from operations research to simplify the calculation of f. Drastically. The problem was obviously repetitive–that’s where the real time requirement comes from. But you want a form for f that is simple to calculate. By clever transformations, all the information in all the previous data was encoded into the solution to the previous iteration. No need to look at long histories. Also a very clever (if I say so myself) transformation replaced the mismatched sizes with a case where both sets are of size, size(m)+size(p). (I should publish that step, but it is less than a line of latex. A very minimal minimal paper.)
But I just made the problem bigger. Time for a literature search that resulted in finding a paper with an n^3lg2(n) algorithm. I few weeks finding bugs in the code and fixing them, and I was almost there. Now for the real magic. There was a step repeated n lg2(n) times clearing an n^2 array to zero. All the other steps were repeated n lg2(n) times as well, but they operated on scalars. Theory is nice, but now I could use the fact that we were building hardware. Put in a memory chip just for that array, and clear it to zero in constant time!
Obviously an effective n lg2(n) algorithm was much better than any alternative. From a theory standpoint, it was still n3 lg2(n), but in reality, since the algorithm needed that space, to solve a larger case you put in a bigger DRAM. 😉
Was this a weird special case? Not really. For most algorithms in P, known best lower bounds are between n and n2. Notice that above, I “cheated” on the computation rules to get a more useful real result. Modern CPUs do a lot of things in one instruction that would take hundreds of instructions on even a Turing Machine with an Oracle that could compute sum, difference, product, logical and, logical or, etc., on registers. Even more impressive, modern CPUs average completing several instructions of a serial program in one clock cycle. (They also have multiple cores which execute different threads in parallel. But that is a detail.) One of my favorites, which is finally getting implemented is the sum of set bits in a 64-bit or 128-bit register. Very useful for chomping through boolean vectors quickly.
So, even if you know a hard lower bound, progress is just around the corner. In other words, solutions for real problems in P are fast, and if necessary will get faster.
“The proof makes an interesting connection between two very different areas of theory. Deolalikar used a special way to define efficient algorithms that is based on logic. This method of defining efficient computation does not use machines at all—it is called ‘finite model theory’. His proof also used an area of statistical physics.
Two things struck me immediately. I had never seen the connection of these areas in any attempted proof of Q. Also, the area of finite model theory has had a number of tremendous successes before. Without going into any details, one of the principles of mathematical proofs is that often there are multiple ways to define something. Many times one definition, even though it is equivalent to another, is the right way to prove something. Deolalikar’s use of this logical theory seemed to be potentially very powerful.”
… Richard. J. Lipton, ‘A Tale of A Serious Attempt At P?NP’, August 15 2010, BLOG@CACM.
(I penned the following comments before the issue of whether the classes P and NP are adequately defined within computational theory was raised by John Sidles. The ensuing discussion suggests that some of the theoretical concerns raised below may be of some practical interest.)
Your highlighting (in the CACM blog) of Vinay Deolalikar’s attempt to define efficient algorithms using logic implicitly suggests the question:
Is the PvNP problem a victim of inadequate definition within an inappropriate perspective?
More particularly:
Is there a danger that the concepts of computability and verifiability are being used to address the PvNP problem without adequate or precise definitions within an appropriate formal language?
To illustrate, consider the following foundational definitions.
(a) Define a boolean number-theoretic formula [F(x1, x2, …, xn)] of a formal language as instantiationally verifiable if, and only if, there is a Turing machine TM that, for any given sequence of numerals [(a1, a2, …, an)], will accept the natural number input m if m is a unique identification number of the formula [F(a1, a2, …, an)], and will always then halt with one of the following as output:
(i) 0 if [F(a1, a2, …, an)] computes as 0 (or interprets as true) over the domain N of the natural numbers;
(ii) 1 if [F(a1, a2, …, an)] computes as 1 (or interprets as false) over N.
(b) Define a boolean number-theoretic formula [F(x1, x2, …, xn)] of a formal langauge as algorithmically computable if, and only if, there is a Turing machine TM_F that, for any given sequence of numerals [(a1, a2, …, an)], will accept the natural number input m if, and only if, m is a unique identification number of the formula [F(a1, a2, …, an)], and will always then halt with one of the following as output:
(i) 0 if [F(a1, a2, …, an)] computes as 0 (or interprets as true) over N;
(ii) 1 if [F(a1, a2, …, an)] computes as 1 (or interprets as false) over N.
Now, in Theorem VII of his seminal paper on formally undecidable arithmetical propositions, Goedel introduced a curious function—now known as the Goedel-Beta function—which has the property that, given any recursive relation of the form x3 = phi(x1, x2) defined by the Recursion Rule, we can use the function to constructively define an arithmetical formula [F(x1, x2, x3)] only through its instantiations, in such a way that [F] represents phi formally in a Peano Arithmetic such as first-order PA.
The proof is standard and tedious, but nevertheless illuminating;.
Illuminating because a remarkable—but apparently unremarked— consequence of Goedel’s constructive argument is that the arithmetical formula [(Ex3)F(x1, x2, x3)] is instantiationally verifiable, but not algorithmically computable.
Remarkable because, first, ‘instantiational verifiability’ immediately suggests a definition of ‘effective computability’ that may have been acceptable to both Goedel and Church; and, second, because such a definition would falsify Church’s (and Turing’s) Thesis.
(To place this in perspective, see Wilfrid Sieg’s ‘Step by recursive step: Church’s analysis of effective computability’.)
Now, how would one relate the PvNP problem to the above definitions?
Clearly, by Cook’s definition of the class P, every member of P is algorithmically computable.
Also, every algorithmically computable number-theoretic function is instantiationally verifiable.
What about the class NP?
If the definition of a number-theoretic function as computable by a non-deterministic Turing machine in polynomial time is intended to adequately ‘capture’ the concept of ‘efficient verifiability’ in a formal language (in this case ZF), then every member of NP should be instantiationally verifiable.
The question arises:
If we accept that SAT and the Travelling Salesman are instantiationally verifiable, can we claim that they are also algorithmically computable?
In other words, can we validly assume that these problems are formalisable by means of some algorithmically computable relations/functions?
Or, if we call formulas such as [F(x1, x2, x3)] above Goedelian, can we presume that SAT and the Travelling Salesman are not Goedelian?
I suspect—and argue—that a satisfactory resolution of the PvNP issue will necessarily require addressing this question from a perspective that is able to interpret first-order PA finitarily in computability theory (as sought by Hilbert), and not from a perspective that seeks (as appears to be the case at present) to interpret computability theory in a set theory such as ZF.
Reason: Unlike PA, ZF cannot tolerate that a primitive recursive relation may be instantiationally equivalent to, but computationally different from, an arithmetical relation – where the former is algorithmically decidable over N, whilst the latter is instantiationally decidable, but not algorithmically decidable, over N.
(See: http://alixcomsi.com/27_Resolving_PvNP_Update.pdf)
Einstein’s general relativity and computation
Assume Two computer or TM near different monmenum objects such as two stars solve same problem by same algorithm,the velocities or the times they take to solve the problem are different.Then by some communication,one computing more slowly can get the result outputed by the other computer computing faster,thus we can accelerate the computation.
There is a problem ,that is the time spent to transport the information or output from one computer to another is related to the distance between the two objects,which must be long enough to let the acceleration be possible.
one clarification:monmenum should be mass.