Ode To The Math Monthly
Some fun results on matrices

Olga Taussky-Todd was one of the leading experts on all things related to matrix and linear algebra in the middle and late 1900’s. She was born in the Austro-Hungarian Empire in what is now the Czech Republic, and obtained her doctorate in Vienna in 1930. She attended the Vienna Circle while fellow student Kurt Gödel was proving his greatest results, and recalled that Gödel was very much in demand for help with mathematical problems of all kinds. She left Austria in 1934, worked a year at Bryn Mawr near Philadelphia, then held appointments at the universities of Cambridge and London until after World War II, when she and her husband John Todd emigrated to America.
Today I want to present a couple of simple, but very cool results about matrices.
Taussky-Todd once said in the American Mathematical Monthly—from now on the Monthly:
I did not look for matrix theory. It somehow looked for me.
That is to say, her doctorate was on algebraic number theory, and then she progressed to functional analysis. Heading in the direction of continuous mathematics was the available path. According to these biographical notes, the field of matrix theory did not really exist at the time. The notes hint that matrix theory was too light to be a main subject for graduate education unto itself, so perhaps the Monthly was a needed vehicle to help to launch it.
Matrix and Monthly
One of Taussky-Todd’s great papers is “A recurring theorem in determinants,” which proved a variety of simple, but fundamental, theorems about matrices. It appeared, as did many of her papers, in the Monthly. One of these theorems is a famous non-singularity condition:
Theorem: Let
be a complex
matrix, and let
stand for the sum of the absolute values of the non-diagonal elements in row
, namely
If
then

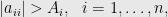

I recall as a student “meeting” Taussky-Todd’s work in a book on algebraic number theory. Somehow many of the results in that area could be reconstructed as theorems on matrices, and the resulting proofs sometimes were much more transparent.
Ivars Peterson has a nice discussion of her work here. The same biographical notes referenced above have this revealing passage:
Olga Taussky always wished to ease the way of younger women in mathematics, and was sorry not to have more to work with. She said so, and she showed it in her life. Marjorie Senechal recalls giving a paper at an AMS meeting for the first time in 1962, and feeling quite alone and far from home. Olga turned the whole experience into a pleasant one by coming up to Marjorie, all smiles introducing herself, and saying, “It’s so nice to have another woman here! Welcome to mathematics!”
Let’s look at two simple but I believe interesting results about matrices. One is from the Monthly, and perhaps Olga would appreciate them.
A Matrix Result
Consider the two matrices 


The question is it possible for a sequence of

The answer is 

The key is to look at the action of the matrices on positive vectors: the vector 
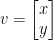
where 
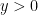
Also define 
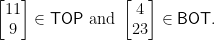
Let 



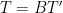
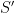

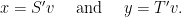
It follows that both vectors 

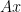


This neat argument is due to Reiner Martin answering a question in the Monthly—the question was raised by Christopher Hillar and Lionel Levine.
Another Matrix Result
There are many normal forms for matrices of all kinds. I recently ran into the following question, which was quickly solved by Mikael de la Salle. Let 

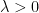


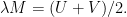
This says that any matrix, up to scaling, is the average of two unitary matrices. It seems this should be a useful fact, but I have not applied it yet.
We can find unitary matrices 

This is the famous Singular Value Decomposition. We can assume that the values on the diagonal are all at most 


where each 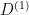
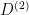



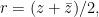
where 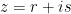
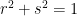
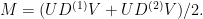
Open Problems
Which matrices are averages—or sums—-of some given fixed number of unitary matrices? With 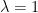
Do you have your own favorite matrix results that have a simple proof, but may not be well known to all? If so please share them with all of us.
Finally, I would suggest that you read the Monthly regularly, since it is filled with gems.


My favorite matrix result is C. Jordan’s lemma of 1875 on the relationship of two subspaces. Let P and Q be the projectors onto two subspaces, then there exists an orthonormal basis, such that P is diagonal and Q decomposes into the direct sum of simple 2×2 blocks and some more trivial 1×1 blocks. Considering how alternating applications of the two projectors P and Q (or their associated reflections (1-2P) and (1-2Q)) act on some input vector can often be reduced to the simple special case of how they act on a single 2×2 block. Understanding this single lemma explains essentially all quadratic speed-ups in quantum computing, including Grover search and Quantum Walks.
For those who are as confused as I was: replace
“But we note that Ax is in TOP and CX is in BOT…”
by
“But we note that Ax has to be in TOP and By has to be in BOT because of the specific forms of A and B and the positivity of x and y…”
Yet another nice thing about matrices is their association to mathematical problems that are simple and natural, yet undecidable.
I believe a matrix M = UDV is the average of n > 1 unitaries precisely when it has spectral norm ≤ 1.
If M is the average of unitaries, it must have spectral norm ≤ 1 since each unitary does. For the other direction, if M has spectral norm ≤ 1, note that D has the same norm as M, meaning all the diagonal elements have absolute value ≤ 1, and the rest is essentially the same as your proof above.
In case it wasn’t clear, this was meant to answer the first “open problem” above.
The first theorem about non-singularity of diagonally dominant matrices has a useful generalization. If A=(a_{i,j}) is an n-by-n real matrix with a_{i,i}=1 and |a_{i,j}|≤ε, then rank(A) is at least n/(2+2nε^2). There’s a really nice paper by Alon describing applications of this fact.
My favourite:
There exists a decomposition
M = S1 S2,
with M, S1, S2 square matrices and S1, S2 both symmetric.
Correct me if I’m wrong.
I thought the non-singularity theorem (which is beautiful) is fairly easy to prove as follows. Suppose det(A)=0, there exists a non-trivial solution to Ax=0. Let x=[x_1, …, x_n]^{t}. Pick among x_i the one with the largest absolute value, say x_k. |x_k|>=|x_i| for all 1<=i0. Consider row k of A multiplied by x using Einstein’s summation convention (where if a subscript appears twice, it’s meant to be summed over {1,…, n}).
|A_{k,i} * x_i| > | |A_{k,k}*x_k| – A_k*|x_k| | > 0
Hence, Ax \neq 0. Contradiction.
M.C.
It is easy to prove. Some times easy is still a great result.
Another way is to note that it is an immediate consequence of the Gershgorin disk theorm (http://en.wikipedia.org/wiki/Gershgorin_circle_theorem). i.e. if A is diagonally dominant then the origin does not lie in any Gershgorin disk and zero is not an eigenvalue, hence the deterninant is non-zero.
sit
Yes this is another nice approach. Thanks for the connection.
Any matrix M=UDV can be written a sum of unitary matrices.
Let n=2*ceiling(norm(M)/2). Then M/n is a matrix of spectral norm <= 1. According to Ørjan Johansen, M/n=(U'+V')/2, where U' and V' are unitary. Hence, M=n(U'+V')/2, which is a sum of n unitary matrices.
Note that the lower bound on number of matrices in a sum must be no less than ceiling(norm(M)). So the above construction is with a constant +1 of the lower bound.
My question is whether M can be written as a sum of distinct unitary matrices. And the answer is probably no if the number of matrices is required to achieve the lower bound. Consider M=nU, where U is unitary. Following a similar result in the vector space, I suppose it takes more than n distinct unitary matrices to have a sum equal to M.
from the today-I-learned dept.
The word matrix or matrices has an etymology related to womb. I first read this meaning in an essay by Hamann that has a very nice description of space and time in terms of a critique on Kant’s pure reason…
late 14c., from O.Fr. matrice, from L. matrix (gen. matricis) “pregnant animal,” in L.L. “womb,” also “source, origin,” from mater (gen. matris) “mother.”
That is wonderful etymology to know: surely matrices have “given birth” to many great and wonderful theorems, and even today they are “pregnant” with many further offspring! 🙂
Actually I considered but rejected making a play on that in the section titled “Matrix and Monthly” above, which has the “it’s nice to have another woman here” quotation.
Anonymous writes:
This theorem is a great favorite of engineers, and moreover, it is (arguably) the sole algebraic theorem to win a Nobel Prize, namely Lars Onsager’s 1968 Nobel Chemistry award, given for Onsager’s 1931 discovery of what is today called “Onsager Reciprocity.”
Concretely, under the following identification:
the Symmetric Matrix Decomposition Theorem asserts (in effect) that “An entropy-like function always exists such that the matrix of kinetic coefficients is symmetric.”
It is striking that Onsager’s reciprocity principle escapes being a sterile, physics-free mathematical tautology solely by its identification of the above “entropy-like function” with the physical entropy.
The thirty-seven year delay in Onsager’s receiving a Nobel is due largely to controversies among chemists and physicists with respect to the physical content (or the absence of physical content) respecting the reciprocity of the kinetic transport coefficients — controversies that have not entirely abated even today, and that are associated equally to both classical and quantum transport mechanisms.
Thus, taken all-in-all, the Symmetric Matrix Decomposition Theorem ranks among the deepest, most fascinating, most controversial, most colorful, and yet most practically relevant theorems of mathematics, physics, and chemistry … it would make a terrific article for Math Monthly.
By the way, regarding the section “Another Matrix Result”, it’s known that any real matrix can be written as a linear combination of four real orthogonal matrices, and it’s conjectured that four is tight. I forget the reference.