Is it Time to Declare Victory in Counting Complexity?
The last dichotomy theorem: graph homomorphism with complex values

Jin-Yi Cai is a great theorist, a world expert on Dichotomy Theorems, and a best friend. We have talked about him before here for his work on these types of theorems, and more recently here.
Today is a new type of post for us—a guest post, by Jin-Yi. We have used his suggested post title, but have inserted a couple sections for added background.
Well we always do things differently here at GLL—as Tina Turner says:
You see we never ever do nothing
Nice and easy
We always do it nice and rough.
We have several guests lined up for the new year to write posts, but as always we will add a bit of extra flavor and a few comments—Ken and I hope that they will understand.
What Is A Dichotomy Theorem?
One of the central questions of complexity theory is: given a computational problem, can we tell whether it is easy or hard? For example, is it in polynomial time or not? In full generality this meta-problem of classifying problems is hopeless—beyond hopeless, if that makes sense. How could we possibly take an arbitrary problem and classify it?
Yet we would like to do this automatically and for as large a class of problems as possible. One method is to search the Web and see if it has been studied before; a related one is to use the famous Garey and Johnson book. But that only goes so far.
The central idea of a dichotomy theorem is two-fold, pun intended. It is to restrict both the family of problems and the notions of complexity. For every problem of a restricted kind, it says that either the problem is easy or it is definitively hard.
Definitively hard can mean many things, from 

A Failed Dichotomy?
Before the guest post, let’s talkabout the famous question that Emil Post raised in the early days of computability theory, in the 1940’s. Following Alan Turing’s seminal result that the Halting Problem is undecidable, people quickly undertook to classify problems as computable not. A problem—or if you prefer a set—is called computably enumerable (c.e.) if it is possible to list its values by a Turing machine. The old style that I learned was to call these sets r.e., but that name is out of date. So use “c.e.” if you want to seem to be au courant, especially if you are talking to logicians.
As people began to classify problems it quickly appeared that every one was either computable or equivalent to the Halting Problem. Somehow they could find nothing in-between. Post asked whether there were problems, natural or not, that were in-between. Essentially he asked: is there a dichotomy theorem for c.e. sets?
This great question led to a flurry of ideas and results, but no solution. Post and others defined a variety of types of sets: simple, hypersimple, hyperhypersimple, and others that attempted to solve his problem. (These are real names—I do not know if there was a hyperhyperhypersimple notion.) The idea was this: suppose that you could define a property 
- If a set
satisfies
- There are undecidable c.e. sets that satisfy
Then there would be sets between computable and complete—the dichotomy theorem for c.e. sets would fail. None of these notions worked, since the language they used for defining the property X was not powerful enough. Eventually, in a brilliant argument, at about the same time in the 1950’s, and independently, Richard Friedberg and Albert Muchnik proved that such intermediate sets do exist. The used a method, now called the priority method, to construct the sets. Therefore the dichotomy theorem failed for c.e. sets.
The issue then becomes whether properties 
Let’s now turn to Cai’s post on the current status of dichotomy theorems in complexity theory. We have edited it somewhat, and it refers to Jin-Yi in third person in some places to say we concur with some opinions.
The Guest Post
If you care about classification theorems in complexity theory, especially for the complexity theory of counting problems, or the so-called Sum-of-Product type problems (a.k.a. partition functions), you may want to know about the recent result of Jin-Yi and Xi Chen. Even if you do not care, you may still wish to know about this paper.
The paper has a plain title: Complexity of Counting CSP with Complex Weights. But what the paper has done can be the conclusion of an era for the theory of counting problems.
Or is it?
Let me (Jin-Yi) first give you some historical context, starting from the days of Kurt Gödel and Alan Turing and Emil Post.
Complexity theory—in particular Steve Cook’s NP-completeness—essentially springs from a direct adaptation of Post’s ideas with a polynomial time restriction. Post’s problem was so intriguing because most “natural problems” seem to be either decidable or as hard as the Halting Problem. In fact, it was said that one of the psychological barrier to proving Hilbert’s 10th Problem undecidable was the fear that it might be of intermediate computability, and no one knew then how to prove a natural problem undecidable unless it is as hard as the Halting Problem. Of course ultimately Hilbert’s 10th Problem was proved equivalent to the Halting problem, by the combined work of Martin Davis, Yuri Matiyasevich, Hilary Putnam and Julia Robinson, with Matiyasevich providing the last crucial step.
Back in Complexity Theory, the story is different. The analogue of decidable sets is P, and the analogue of c.e. sets is NP. We still can’t prove NP 
Dichotomy for CSPs
Giving this belief a precise form, Tomás Feder and Moshe Vardi formulated a CSP dichotomy conjecture. Here CSP stands for Constraint Satisfaction Problem. This is an extremely broad class of problems expressible as follows: Let 

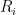
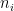

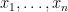

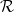
The Feder-Vardi Conjecture is about decision problems. There are two other versions of Constraint Satisfaction Problems. One is the optimization version: What is the maximum number of constraints that can be satisfied in a particular instance? The other is the counting version: How many satisfying assignments are there? It is in this counting version we wish to report a recent decisive victory.
One can express counting CSP problems as follows: Identify each 


where 

General Notions
In this Sum-of-Product form, there is a vast generalization where each function
In many physical systems, global behavior can be determined by local interactions, which are naturally expressed in this Sum-of-Product form. Included in this class are the Ising Model, the Potts Model, and many others. There is a long tradition in statistical physics to classify the so-called Exactly Solved Models, as expounded in this book by Rodney Baxter.
In computer science language this translates to polynomial time computable. Physicists did not have a rigorous notion of what is not Exactly Solvable; the proper notion in computer science is #P-hardness.
For the whole class #P, Ladner’s theorem still holds: If #P
A succession of beautiful papers can be seen in this light, culminating in the latest Cai-Chen dichotomy theorem. These papers give ever stronger indications to the scope of this general belief.
Graph Homomorphisms: A Natural Case
Over the years, a great deal of effort has been focused on a special case of CSPs: Graph Homomorphisms. This is the case when there is a single binary constraint function 


![\displaystyle Z_A (G) = \sum_{\xi:V\rightarrow [d]}\prod_{(u,v)\in E} A_{\xi(u),\xi(v)},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++Z_A+%28G%29+%3D+%5Csum_%7B%5Cxi%3AV%5Crightarrow+%5Bd%5D%7D%5Cprod_%7B%28u%2Cv%29%5Cin+E%7D+A_%7B%5Cxi%28u%29%2C%5Cxi%28v%29%7D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
where 
Let’s list some highlights of this substantial body of work:


The final step for
The Unified Dichotomy Theorem
Now all these dichotomy theorems have become special cases of the following theorem by Cai and Chen.
Theorem: Given any finite
and any finite set of constraint functions
, where each
maps
(for some
) to the complex numbers, the problem of computing the partition function
is either computable in P or #P-hard.
The tractability criterion for this theorem is explicitly given. However it is not known whether the criterion is decidable. The proof uses ideas from both the Dyer-Richerby paper and the Cai-Chen-Lu paper.
More than the technical issue of decidability of the criterion, there is a very different taste to this dichotomy theorem, compared to the Cai-Chen-Lu paper on Graph Homomorphism. There is a sense in which the Cai-Chen-Lu paper on Graph Homomorphism really lets you understand what makes a problem tractable, and what makes it #P-hard. The criterion is delicate, but roughly speaking, in order to be computable in polynomial time, the matrix 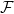
One can caricature the situation as follows: In the Cai-Chen-Lu dichotomy, they conquered the land with meticulous care. They catalogued all the flowers and inspected all the caves. In the latest CSP dichotomy, they claimed victory by having encircled the mountain; the land is logically conquered, but one does not really know what treasures lie within.
Open Problems
So is it time to declare victory? You be the judge.
One final comment, from Dick: One simple way to explain the reason for all the above beautiful work shooing that problems are either easy or hard is that 


Pretty nice post, I enjoyed reading it.
I think it would be more precise to call FP a counting problem solvable in polynomial time, as P denotes the decision problems solvable in polynomial time.
Do anybody believe that FP = #P? From this it would immediately follow that P = NP.
Yes I do.
Here are two links to some work in progress:
1. http://arxiv.org/abs/0812.1385
2. http://arxiv.org/abs/0906.5112
I’m a logician and most people I get on with still use r.e. and recursion theory, etc, not everyone subscribe to the rebranding!
Just curious. Why hasn’t this result generated the same level of excitement in the TCS community as the Matrix Multiplication work? Isn’t this a breakthru?
Perhaps because it is a far more difficult to say anything?
I guess because this is the culmination of a series of recent results, as opposed to a result coming out of the blue after no real progress for many years. Still, it’s a very significant result. There is much more to do, though, with many questions regarding the complexity of approximate counting still open.
R.E. and recursive seem to still dominate out in Berkeley…but when you aren’t a well known name and want to publish you cave.
Anyway no there was no hyperhyperhypersimple. The difference between hypersimple and hyperhypersimple depends on whether you give indexes to the finite sets appearing in the definition as explicitly given tuples or as programs for their enumeration. There is no natural way to continue extending this version of the definition and no one seems inclined to call any other kind of generalization hyperhyperhypersimple.
Besides, what’s the point. Once you know maximal r.e. sets exist there is less interest in pursuing notions of thinness for r.e. sets.
What is a “natural set/problem/property” exactly? Or is it just an intuitive notion?
Superb post.
I was thinking in a an analogy:
Maybe NP problems will be proven different from P, but the hard instances (that take exponential time) in a NP-complete problem will be proven to be perfectly characterized by a (decidable and) polinomial property (or maybe an undecidable one).
I think that would be a good solution that would break the dichotomy between the worlds “NP /= P so creativity exists” or “NP=P so creativity is gone” =P