A Neat Result About The Simplex Algorithm
And a neat question about the neat result

Thomas Hansen gave a talk at our ARC Theory Day a week ago Friday. He is at the Center for the Theory of Interactive Computation, in the Department of Computer Science, Aarhus University. He has won best-paper awards already for his terrific work on the complexity of linear programming.
Today I (Dick) would like to talk about his result and an open question that was raised at the end of his talk.
Before I discuss the result I would like to thank the organizers Prasad Tetali and Prasad Raghavendra again. One reason our Theory Day on 11/11/11 was special, besides the thrice-in-a-century pattern of the date, was the international mix of the participants.
I have just come back from a visit to the Middle East, where the State of Qatar is expanding their vision for computer science research. The Qatari capital Doha is itself an international city, as workers from other countries actually outnumber local residents. It will be interesting to see the expansion of computer science into regions such as the Mideast and Africa and into smaller countries like Qatar.
Some Simplex History
A linear program in 





If 



This enhanced the idea of selecting a neighbor at random from among all 


The Result
The paper presented by Hansen is joint with Oliver Friedmann and Uri Zwick, and is titled: Subexponential lower bounds for randomized pivoting rules for the simplex algorithm. It appeared in the last STOC conference. The new theorems all are of the form:
Theorem 1 For the random pivoting rule X there is a concrete family of linear programs
so that for all
, the expected time using rule X is at least

where
is a constant that depends on X.
The proofs are quite intricate and clever—see the paper for the details, and also this followup paper by Friedmann. The results use connections between pivoting steps performed by simplex-based algorithms and improving switches performed by policy iteration algorithms for solving Markov Decision Processes.
The Question
At the end of the talk a question was raised by an audience member—I am sorry I do not know who. I thought the question was quite neat and would like to repeat it here. The question makes sense for algorithms other than just simplex, but I will phrase it as only a question about simplex.
Suppose that you have two pivoting rules 
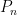

-
The rule
steps on
-
The rule
Can we prove that there must be one family of linear programs 

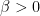

Informally, is there a way to put together a linear program family that fools both rules? Note, it seems possible that rule 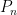
Note that we are talking about fooling for all 

A Related Question
Ken contributes a related question. Define a “meld” of rule
Given 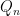
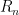
Now the question seems to be nontrivial even if we only mean fooling at infinitely many
Open Problems
Solve the question that was raised—it may be easy. Or work on more complex pivoting rules. Is there a randomized rule 
Note that many basic questions about linear programming are still wide open. Earlier we blogged about the surprising refutation of Warren Hirsch’s conjecture that there would always exist a path to an optimum vertex in
It is commonly known that linear programming belongs to 


The results of Oliver, Thomas, and Uri are truly wonderful and so is the connection with various classes of stochastic games.
“…, but this presumes that the number of bits needed to specify the coefficients factors into the input length.” ?
… is unlimited ?
Why isn’t the answer to the problem (gives an infinte number of problems)?
the answer to the problem (gives an infinte number of problems)? could solve the
could solve the 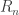 in less than
in less than  steps, it would also solve
steps, it would also solve  as a side result in less than
as a side result in less than  steps.
steps. by making problems larger. Are there reasons, why this property should be unrealisitic?
by making problems larger. Are there reasons, why this property should be unrealisitic?
If rule
Hence, we could speed up rule
So, we can argue analogously for strategy . Hence we cannot solve
. Hence we cannot solve  in less than
in less than  steps. So we cannot solve
steps. So we cannot solve 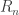 in less than
in less than  steps with
steps with  .
.
This solution looks a bit trivial, so what am I missing?
If I am not mistaken, it should also be true that if are adjacent vertices of
are adjacent vertices of  , then
, then 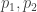 should be adjacent vertices of
should be adjacent vertices of  and similarly for
and similarly for  . So we are actually only making the problem larger in a very specific way.
. So we are actually only making the problem larger in a very specific way.
Uhh.. just noticed: Taking the product of two polytopes only adds the number of variables and constraints. So its . And we can even find better bounds on
. And we can even find better bounds on  .
.