Another Annoying Open Problem
The k-server problem: some progress, still wide open

Aleksander Mądry gave a stellar talk at our ARC Theory Day a week ago Friday. He is an expert on algorithmic graph theory, among other areas of theory. Already he has multiple best-paper awards, including the paper of this talk from FOCS 2011, and I expect he will get more in the future. This is good going considering that basic LaTeX systems lack a macro for the Polish ogonek diacritic in his name—Ken installed a special package called tipa to get it while editing this post.
Today I would like to talk about his result and the open questions that remain.
He with Nikhil Bansal, Niv Buchbinder, and Seffi Naor (BBMN) have made a recent important contribution to our understanding of the complexity of on-line algorithms. Aleksander’s talk was wonderful and explained what is known, their new result, and what still remains to be done. As he said:
One of the remaining open questions is really annoying—it should be solved—but it continues to resist attacks.
Before I discuss their result I would like to thank the Theory Day organizers Prasad Tetali and Prasad Raghavendra. It was held on the magical day 11/11/11, which does not happen that often, and in fact Mądry’s talk spanned 11:11:11am. Ken wore a red shirt in Buffalo but could not find the WW I remembrance poppy pin he acquired during his sabbatical in Canada. The full scorecard of talks and titles was:
- Thomas Dueholm Hansen: Subexponential lower bounds for randomized pivoting rules for the simplex algorithm.
- Aleksander Mądry: Online algorithms and the k-server conjecture.
- Mohit Singh: A Randomized Rounding Approach for Symmetric TSP.
- Ryan Williams: Algorithms for Circuits and Circuits for Algorithms.
The Problem
The problem he spoke about is the now classic on-line server problem. The simplest case is the problem of managing a computer $. Note that this is the way to tell a theory talk on computer caches from an architecture talk on computer caches—in architecture often $ is used to denote a cache. Perhaps this is changing, given the current economic turmoil, perhaps not.
The key is that there are 

Randomization comes to the rescue. If the strategy for eviction can be random, then it is known that an on-line random strategy exists that is 
The paging problem is just a special case of the general
In the 1990’s this problem was very “hot,” and there was a stream of results that tried to get good deterministic server strategies. The first results were exponential in 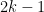
The BBMN Result
The new result is:
Theorem 1 There exists an
-competitive on-line strategy for the
-server problem.
This is a great improvement, but it also changes the rules. It is great since the competitiveness bound is poly-log in
See their paper for the proof. The key idea is that they: Reduce the 
Open Problems
The
-
If the strategy is deterministic it must take
- If the strategy is randomized it must take
. There is a huge and annoying gap to the known upper bounds here. There is no known strategy for even the simple case of the real line that is randomized but beats linear in
- Finally, are the polylog factors of
[fixed typo in Fiat et al. to O(log k)]


The Fiat, Karp, et al algorithm is O(lg k) competitive, not O(lg n) competitive.
Thanks for the fix.
Thank you for your post. I am very happy that you enjoyed the talk.
I just wanted to clarify one detail:
At a very high level, our algorithm consists of two main steps:
1) We reduce the k-server problem over an arbitrary metric to a different problem — called the allocation problem — over a very simple, “weighted star” metric. This allow us to deal with this simple metric — instead of the general one — but at a price of having to solve more difficult problem (i.e., the allocation problem).
2) We design an algorithm that solves this allocation problem over the “weighted star” metric” with sufficiently good competitive guarantee.
So, even though step 1) indeed uses the tree-embedding result of Fakcharoenphol-Rao-Talwar to get from arbitrary metric to an appropriate tree metric, it also requires some further work to be able to reduce the k-server problem on such a tree metric to the allocation problem over the “weighted star” metric. This second part is based on a modification of a similar reduction that was first constructed by Cote-Meyerson-Poplawski. (Cote-Meyerson-Poplawski were also the first to point out the connection between the allocation problem and the k-server problem.)
are there known lower bounds for this problem?