Generating Functions and Singularities
Sharpening an analytic tool for regular languages

|
| IEEE source for Book, Even, Ott photos |
Ronald Book, Shimon Even, Sheila Greibach, and Gene Ott proved a fact that may escape attention nowadays. Everyone knows the equivalence of finite automata (of all major kinds) and regular expressions. But do you know that the regular expressions can be made unambiguous?
Today we explore consequences of this fact for analyzing automata via generating functions.
A regular expression 
-
wherever
occurs inside
;
-
wherever
occurs inside
can be written in exactly one way as
with
and
;
-
wherever
occurs inside
can be written in exactly one way as a concatenation of strings in
.
The last clause entails in particular that the empty string cannot match 


Is there an easy way to convert any given regular expression
DFAs Give Unambiguous Regexps
If we have a deterministic finite automaton 

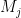
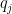

and moreover this union is disjoint: Because 
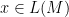
Hence to build an unambiguous regular expression for 



![{A[i,j] = c}](https://s0.wp.com/latex.php?latex=%7BA%5Bi%2Cj%5D+%3D+c%7D&bg=ffffff&fg=000000&s=0&c=20201002)



![{A[i,j] = \emptyset}](https://s0.wp.com/latex.php?latex=%7BA%5Bi%2Cj%5D+%3D+%5Cemptyset%7D&bg=ffffff&fg=000000&s=0&c=20201002)

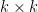
for (k = n; k > 2; k--) //bypass and eliminate state k
for (i = 1; i < k; i++) //obviate incoming arc (i,c,k)
for (j = 1; j < k; j++) //update transition from i to j
A[i,j] = A[i,j] + A[i,k] A[k,k]* A[k,j];
The loop maintains three invariants:
-
Computations on strings matching
involve no intermediate states
.
-
All strings that take
-
of zero or more terms having different leading characters.
If ![{A[i,k]}](https://s0.wp.com/latex.php?latex=%7BA%5Bi%2Ck%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{A[k,k]^*\cdot A[k,j]}](https://s0.wp.com/latex.php?latex=%7BA%5Bk%2Ck%5D%5E%2A%5Ccdot+A%5Bk%2Cj%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
-
The previous
, so
and the character taking it there in
-
is unambiguous because, by the second invariant, substrings matching
can be uniquely parsed.
-
The
concatenation is uniquely parsable at front and back, and does not match
are unambiguous and do not match
On loop exit, the regular expression ![{A[1,1]^*}](https://s0.wp.com/latex.php?latex=%7BA%5B1%2C1%5D%5E%2A%7D&bg=ffffff&fg=000000&s=0&c=20201002)

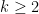

![{A[1,1]^*\cdot A[1,2] \cdot A[2,2]^*}](https://s0.wp.com/latex.php?latex=%7BA%5B1%2C1%5D%5E%2A%5Ccdot+A%5B1%2C2%5D+%5Ccdot+A%5B2%2C2%5D%5E%2A%7D&bg=ffffff&fg=000000&s=0&c=20201002)

The paper proves a stronger statement about preserving ambiguities. The above looks like a polynomial-time (indeed, cubic time) algorithm but is not—because the sizes of the
Generating Functions
Let us fix the binary alphabet 



where 
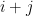

Note that if we identify 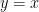

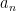
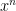



Theorem 1 If
is regular, then there are two polynomials
and
such that

That is, the generating function of a regular language is a rational function. The converse does not hold, because there are regular and non-regular languages that have the same “census counts”

To prove this theorem, we start by simply associating to every regular expression 
-
-
-
,
-
-
-






Clearly the function thus defined is rational. The observation that finishes the proof is:
If
is unambiguous, then
equals
where
That every regular language 

Machines and Invariant Denominators
Given any 





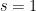

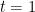
![\displaystyle A_M[i,j] = A_M[i,j] + \frac{A_M[i,k]\cdot A_M[k,j]}{1 - A_M[k,k]}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++A_M%5Bi%2Cj%5D+%3D+A_M%5Bi%2Cj%5D+%2B+%5Cfrac%7BA_M%5Bi%2Ck%5D%5Ccdot+A_M%5Bk%2Cj%5D%7D%7B1+-+A_M%5Bk%2Ck%5D%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
The result is the generating function for the language 



Theorem 2 If a DFA
is strongly connected then for all states
and
, the bivariate generating function of
is given by
where
and the numerator has no common divisor with

The proof only requires analyzing the two-state case. If 


The generating functions shown for 




Thus 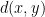

Singular Sets
The zeroes of the polynomial 



The line 

What does 

Some three-state automata exhibit other interesting behaviors. The two in the middle should be plotted in the complex plane.

Intersecting 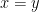
Open Problems
Have you seen this two-variable generating function for regular languages? What can be done with it?
[added note about why
2023 NAE Meeting
With a memorial to William Wulf
Anita Jones will be attending the next 2023 National Academy of Engineering’s annual meeting in Washington DC. Kathryn and I will travel there this weekend. Here is a photo of her winning the Philip Hauge Abelson award in 2012, the top honor of the American Association for the Advancement of Science. (The JFIF original there is sharper; see this for why.)

Four and More Colors of Mathematics
A memorial to Wolfgang Haken (1928–2022) and more in the AMS Notices
This month’s Notices of the American Mathematical Society for October 2023 has just been mailed to me.

This issue is special in several ways:
- It is large and thick with many pages;
- It has a lot of technical material on decision procedures;
- It has both a feature and a memorial for Wolfgang Haken, who passed away late last year.
2023 NAE Meeting
One of the new members they will welcome
Telle Whitney has just been selected to be a new member of the National Academy of Engineering. I will see her at the next 2023 National Academy of Engineering’s annual meeting—where she will be admitted to the NAE.
Congrats to Telle on being selected to the join the NAE this year.

|
| her website |
Happy Birthday 77
With brief musings on AI and the blog

Richard Lipton has turned 77 today. He and Kathryn are back in Manhattan after spending much of the summer in Harbor Springs, Michigan. The original for the photo at right was taken from the local newspaper there.
Today I am delighted to wish Dick a happy birthday and riff a little on “artificial existentialism.”
Read more…
Congrats to Three Colleagues
And a fourth

|
| Composite crop of src1, src2, src3 |
Vinod Vaikuntanathan and Santosh Vempala and Virginia Williams have a common thread. No, it’s not that they all have a name that starts with a V. Yes, they all are at an institute that is of the form:
X Institute of Technology
But it is really that they all have made important contributions to theory. The Simons Foundation has selected them as winners of the 2023 awards in theory.
They are at the end of the overall list of winners for 2023. No, it’s not because they have names that start with V, V, and W. Yes, it’s because the winners in each field are grouped together and theory comes last.
The Winners
Here are the citations for the three in Theoretical Computer Science:
- Vinod Vaikuntanathan, Massachusetts Institute of Technology: Vinod Vaikuntanathan’s research is in the foundations of cryptography and its applications to theoretical computer science at large. He is known for his work on fully homomorphic encryption, a powerful cryptographic primitive that enables complex computations on encrypted data, as well as lattice-based cryptography, which lays down a new mathematical foundation for cryptography in the post-quantum world. Recently, he has been interested in the interactions of cryptography with quantum computing, as well as with statistics and machine learning.
-
Santosh Vempala, Georgia Institute of Technology: Santosh Vempala has made fundamental advances in the theory of algorithms: for sampling high-dimensional distributions, computing the volume of a convex body, optimization over convex sets, randomized matrix approximation, as well as basic problems in machine learning. In many cases, these were the first polynomial-time algorithms and co-evolved with insights into high-dimensional geometry and probability. Recent highlights include proving that sufficiently sparse linear systems can be solved faster than matrix multiplication (
, the workhorse of modern computation); extending sampling methods to non-Euclidean (Riemannian) geometries to make them faster (leading to practical methods in very high dimension); pioneering techniques for algorithmic robust statistics (immune to adversarial corruptions); and developing a rigorous theory of computation and learning in the brain in a biologically plausible model (how does the mind emerge from neurons and synapses?). He continues to be puzzled by whether an unknown polytope can be learned in polytime from samples, whether its diameter is bounded by a polynomial in its description length, whether its volume can be computed in polytime without randomization, and whether the answers to these questions will be discovered by humans or by AI.
- Virginia Williams, Massachusetts Institute of Technology: Virginia Vassilevska Williams’ research is broadly in theoretical computer science, and more specifically in designing algorithms for graphs and matrices, and uncovering formal relationships between seemingly very different computational problems. She is known for her work on fast matrix multiplication, both in co-developing the world’s fastest algorithm and in proving limitations on the known techniques for designing matrix multiplication algorithms. Williams is also one of the original founders and leaders of fine-grained complexity, a blossoming new branch of computational complexity.
One More Makes Four
The areas of the other winners are: Mathematics, Physics, Theoretical Physics in Life Sciences, and Astrophysics. One of the winners in plain-vanilla Physics is another old friend:
- Aram Harrow, Massachusetts Institute of Technology: Aram Harrow studies quantum computing and information. He works to understand the capabilities of the quantum computers and quantum communication devices we will build in the future, and in the process, he creates connections to other areas of theoretical physics, mathematics and computer science. He has developed quantum algorithms for solving large systems of linear equations and hybrid classical-quantum algorithms for machine learning. Harrow has also contributed to the intersection of quantum information and many-body physics, with work on thermalization, random quantum dynamics, and the “monogamy” property of quantum entanglement.

|
| src |
We interacted with Aram through almost the entire year 2012 as we hosted an eight–part debate between him and Gil Kalai on the scalability of universal quantum computing.
In his own work, one of the things he is famous for is the HHL algorithm with Avinatan Hassidim and Seth Lloyd. We covered it in a 2019 post. This is mainly what the line that he “has developed quantum algorithms for solving large systems of linear equations” is referring to.
Now wait a second: this is just the same thing as solving
Should quantum
be called “the unicorn of modern computation?”
All kidding aside, we congratulate Aram on this award.
Open Problems
And our congrats to all the award winners in all areas.
The Distributed Prize
And a ‘new’ computing ‘blog’ with over 1,300 sizable ‘posts’ unearthed

Edsger Dijkstra contributed to many aspects of computing. His name is attached to Dijkstra’s Algorithm, of course, but his 1972 Turing Award citation does not mention it. His 1974 paper on self-stabilization of distributed programs won the Influential Paper Award awarded during the annual ACM Principles of Distributed Computing (PODC) conference in July 2002. The award was subsequently co-sponsored by the EATCS Symposium on Distributed Computing (DISC) and named for Dijkstra after he passed away a month later in 2002.
Today we recognize this year’s winners.
Read more…
Should These Quantities Be Linear?
Drastic proposals for revamping the chess rating system

Jeff Sonas is a statistician who runs a consulting firm. He also studies skill at chess. He has advised the International Chess Federation (FIDE) about the Elo rating system for over a quarter century. He and FIDE have just released a 19-page study and proposal for a massive overhaul of the system.
Today I ask whether larger scientific contexts support the proposal. Besides this, I advocate even more radical measures.
Read more…
TTIC Makes a Hire
Avrim Blum just announced that Shiry Ginosar has accepted his offer and will be joining TTIC as a tenure-track Assistant Professor starting this Fall 2024. Avrim is the chief academic officer for TTIC.
Shiry works in computer perception, including vision, audio, and other sensory modalities, as well as machine learning and AI more broadly. Her work focuses on artificial social intelligence, including social learning, Human-Human, and Human-AI interaction.
Welcome, Shiry!! Says Avrim.

Two Other Tests of Time
Mihalis Yannakakis 70-Fest and the 2023 Gödel Prize

|
| 2020 AAAS election—congrats on that too |
Mihalis Yannakakis is being honored with a 70th-birthday festival next month at Columbia University in Manhattan. It is organized by Xi Chen, Ilias Diakonikolas, Kousha Etessami, Christos Papadimitriou, Dimitris Paparas, and Rocco Servedio.
Today we congratulate him and consider this as one way to mark a “test of time.” Then we discuss another.
There is a free but required registration for the August 16–18 event. Here is the current all-star list of speakers and topics:

Our friend Vijay Vazirani leads off with a talk that will reference Mihalis’s ideas on linear programming and optimization problems. The fourth talk by Toniann Pitassi is on communication complexity. These lead us to think of a variation on the “test of time” idea.
We have just been discussing ACM STOC and IEEE FOCS “Test of Time” awards. We posted a note in 2021 when they were created, and sure enough, Mihalis was one of three judges on the initial panel.
A Second-Order Test of Time
The above awards are “first-order” in the sense of being direct honors for a paper. The papers are expected to have stimulated other important papers, which might later receive their own awards. Our idea for a second kind of test-of-time award inverts the time flow.
A prize for a paper that unambiguously led to papers that won prizes, without having won a prize itself.
Here is the paper—note it is singly authored:
- M. Yannakakis, “Expressing Combinatorial Optimization Problems by Linear Programs,” ACM STOC 1988 and J.C.S.S. special issue, 1991.
And here are the papers it led to—winning the 2023 Gödel Prize no less:
- Samuel Fiorini, Serge Massar, Sebastian Pokutta, Hans Raj Tiwary, and Ronald de Wolf, “Exponential Lower Bounds for Polytopes in Combinatorial Optimization, ACM STOC 2012 (with different title) and Journal of the ACM 2015.
- Thomas Rothvoss, “The matching polytope has exponential extension complexity, ACM STOC 2014 and Journal of the ACM 2017.
The former paper also won the 2022 Test of Time 10-year award; the latter will be up for the first time next year. But Mihalis’s paper did not win in 2022 when it was eligible for the 30-year award with its four-year horizon rule; two other papers from the 1988 STOC did win. Nor does the paper seem to be mentioned or specifically implied in the citation for Mihalis’s 2005 Knuth Prize. Thus it seems to meet the eligibility condition for our prize.
The relevance condition is clear: The 2023 Gödel prize citation says that the five authors of the first paper
“made ingenious use of techniques from communication complexity (following a framework pioneered by Yannakakis) to show that any extended formulation for the TSP polytope has exponential size.”
The second paper is cited as “Building on these techniques, …” The Test of Time citation notes that the first paper “resolved a 25-year open problem”—namely one that was posed by Yannakakis as they say in their abstract. In our own post on this topic in 2012 we called Mihalis’s 1988 work “a famous paper.” Yet, again, it seems to be eligible for our no-prizes prize.
Open Problems
Is Mihalis’s 1988 paper really eligible for our prize, or has it already won a prize we haven’t found?
Again, we congratulate Mihalis warmly on his 70th birthday and we congratulate the winners of the 2023 Gödel Prize.
[fixed a spelling inconsistency]

