Have I Been Cheating at Wordle?
What natural streaks say about some recent chess cheating accusations

|
| Sundials source |
Frank King programmed an ancestor of Wordle at Cambridge University in the late 1960s. That game, called “Bulls and Cows” or “Moo,” was popular on timeshare computers—so popular that various kinds of cheating and tampering arose, as attested by this 1972 note. Cheating at Wordle has been in the news again this month—to say nothing of new headline accusations of cheating at chess.
Today we discuss whether I have been cheating at Wordle—and how this should shape our thinking about the new allegations over winning streaks in chess.
The leading one is by the former world champion Vladimir Kramnik over a 46-game streak last month by the many-time US champion Hikaru Nakamura in blitz chess on Chess.com. Some further allegations have been brought to my attention just this morning. Replying in appropriate detail to everything will take more time than I’ve had at the end of a busy term before holiday travel. Here, now, I will only address an important principle that is often overlooked and misunderstood: the Look–Elsewhere Effect (LEE). The impasse is evident in Kramnik’s response to Chess.com’s Nov. 29 statement about the accusations:

The real logical fallacy isn’t analyzing one streak versus other streaks, it’s failing to include the non-streaks. Nakamura just yesterday passed 50,000 games in the two blitz categories alone. Another facet is the need to account various kinds of clustering in long sequence data, where any of those kinds might have provoked an equivalent response from you.
A Statement and Confession
Before I get to LEE, let me put this up-front: Using the same testing setup and policies I’ve applied for online blitz chess since the pandemic began—settings I used in my work on the Carlsen-Niemann case to FIDE, whose verdict released last week I am also reacting to:
For the 46-game streak, the tests of Nakamura’s concordance to several chess programs give
-scores between 0.6 and 1.7, all in the normal range. If the sequence is extended to include six more games against the same player he was playing at the end (two of which Nakamura lost)—which is the minimum responsible statistical selection policy—then the
Under a newer setup that up-weights positions with more at stake (all my setups already discount positions with obvious replies) the scores are somewhat higher, but still nowhere near the standard for evidence for the cherry-picked streak, and still nada when including the further six games. Also important are my Intrinsic Performance Rating measurements:
Whereas Nakamura played 50-to-75 Elo rating points above his expected accuracy level—a difference almost swallowed by the error bars and possible methodological skew—his opponents played more than 200 Elo below their expectations. Thus, various binomial simulations that were based on a neighborhood of 300–400 difference in official ratings need to widen that to 500–600, whereupon their assertions of unlikelihood disappear.
But LEE is primary—and a full accounting of it will deflate any attempt to squeeze significance from this or other streaks that Kramnik has fingered. To convey this as vividly as I can, I will begin with a confession:
I, too, have been guilty of streaky success this month—at Wordle. And once last year, to boot.
You, dear readers, will be able to run tests of my streaks quickly and freely on your screen, without needing to play any Wordle. On we go.
Some Game and Stats Background
The game programmed by King challenged players to guess a secret decimal 
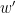
A non-tech version with colored pegs rather than digits subsequently became a smash hit under the name Master Mind. It used 6 colors rather than 10 digits, keeping 
Donald Knuth proved a strategy for winning within 5 turns. Others proved methods of obtaining as low as 4.34 in average case against random
Wordle differs by limiting

This affords a good analogy to golf scoring: solving in 4 turns is “par,” 3 is a “birdie,” and taking 5 turns is a “bogey.” Getting
Another difference is that the server, whose rights the New York Times purchased from originator Josh Wardle in early 2022, presents the same secret
A lot of Wordle players cheat (most obviously, from excessively many holes-in-one).
Am I among them? Let’s view the record.
My Recent Streak
Here are my scores over five days earlier this month:

Not only that, I had birdies on the days before and after the streak—and just now on Tuesday:

If you just look at the 5-day streak and multiply the chances of getting the score-or-better, the odds of it would seem to be
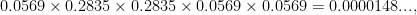
which is about 67,500-to-1 against. Throw in the other eagle (and never mind that I also scored 2 on Nov. 30), and multiplying another 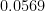
OK, without even putting a section heading in the way, I’ll say immediately that this crude multiplication is wrong. It is wrong for several reasons, some laughable, but others not so much.
Closed Worlds and Looking Elsewhere
The first reason it is wrong is that the multiplication gives the odds of getting the eagles and birdies in that order. In any five-game stretch, there are 5-choose-2 = 10 different ways the two 3s could have occurred. Two more of those ways use the middle three positions; the other seven would have given me the option of proclaiming three 2s in a row, or three in four tries.
The point is that any one of those ten orders would have generated a similar claim—or more. Thus the odds should be divided by (at least) a factor of 10. Then “6,750-to-1” comes noticeably closer to reasonableness. This is just saying that one needs to use a binomial—or multinomial—distribution. Bringing in the 3s that I scored on December 6 and 12 would change the local analysis but leave a similar order of apparent odds.
The largest reason, however, is that I haven’t only been playing Wordle this month. I’ve played almost 500 games total.

This graphic mercifully omits 8 failures to solve within six tries. Thus my eagle percentage is 
The major flaw in the above analysis that I am talking about is that it declared its own “closed world”—as if December 7–11 were the only days that Wordle was offered. The real world is open—there are many other times I could have had a streak, and those need to be accounted.
If you looked elsewhere—if the records are preserved longer than the NYT’s current 12-week horizon—then you would find a several-month stretch when I had only one 2-solve. I have referenced looking elsewhere here as “Littlewood’s Law” and here in regard to the “Doomsday Argument.” But those were about singleton unusual events. How does it work for streaks?
Taking a Second Moment
At issue is the tendency of moderately-unusual events to cluster. Here is a way I imagine an incredulous would-be accuser—of the kind I’ve seen a lot on social media—could reason:
But wait—the
rate amounts to one or two eagles per month. You’ve done it 4 times already this month, 5 if you count Nov. 30. And why are you doing it just when you’re called on to write an article on streaks in chess?
I did already consider writing a similar Wordle post when I had a streak of three 2s in a week last year. It came at the height of the Carlsen-Niemann furore. I broadcast this on Facebook to enunciate the same point about streaks that I am making now here:

And I had a 4th eagle come even more quickly after that:

What?—you had another similar streak? Also at a most opportune time?
A One-Shot Random Trial
I could launch into a deep mathematical analysis of clustering in long sequence data. Perhaps this is already being done specifically for Wordle. Integrals and approximations are passive and TL;DR-ish, however.
I’ve chosen to make my point a different way. It is one that you, dear readers, can replicate for yourselves—and without having to be good at Wordle over a 500-day period. I went to Random.org and clicked on the free Integer Generator. I asked for 500 draws of integers from 0 to 17, since 0.057 is about 1/18 (it’s midway to 1/17 but using the bigger range stacked odds slightly against me), in five columns. I did this only once—maybe Random.org keeps records that could verify this.
Here is what I got (cleaner download).
Sure enough, there is a row with three 2s and another one nearby, two-thirds of the way down:

This is even without considering simulated five-day sequences that span two rows.
I originally thought to look for 2s. Since I configured 0 as “low score,” maybe I should be held to choosing that digit. No problem—at the bottom:
![]()
And just a few rows above it, a wraparound trio in six not five “Wordle days”:
![]()
There’s also a three-in-five cluster of 0s if you go down by columns:

Did I leave out the number 1? Or is 13 your lucky number? OK, I must concede—there are no five-number sequences going by rows with 1 occurring thrice, nor 13. But there are three consecutive 1s in the fourth column. And as for 13, there’s this:

Here’s a nicely symmetric pattern—plus 12/13 is my wife’s birthday:

OK, this is getting more subjective—but that itself is a point: subjectivity amplifies the prior odds of getting something that piques you post-hoc. Sticking to the original three-in-five cluster criterion, please do see how often you get “hits” from completely random numbers.
You can also do random trials of the simulations based on rating differences—using an alphabet of size 
Open Problems
The three consecutive 1s in a column give me cover for a final admission: I came real close to getting three eagles in a row. I vary my starting word, and on December 12, the one I tried was lucky enough to leave just two possible secret words: these and those. I guessed the wrong one:

Does that prove—at least by the standards of social media—that I wasn’t cheating after all?
For a postscript, I intend to address Kramnik’s other allegations, most notably in rounds 7–11 of Chess.com’s “Titled Tuesday” blitz tournaments by those who have a shot at prizes. I obtain slight bumps on the edge of significance as mass phenomena over all players, but have not yet figured the selection bias of Kramnik’s list. Even more care will be needed to parse apart several possible natural expectations for such a bump:
- Those in contention may be a-priori having a good-form day.
- Adrenaline may kick in when you’re in contention.
- Survivor bias—and the mere fact of post-selection.
Accusers and their advisers need to put in this work—to say nothing of at least giving confidence intervals and normalized scores for their results.
[a couple word changes]


To start with, huge mistake in amount of blitz games of Nakamura, in fact 35454 for today. And of course the amount of streaks is decisive to calculate the probability. Great research, Mr.Regan!
There were in fact 35454 blitz games played by Nakamura instead of 50000 mentioned by the author. And many more streaks in a short period of time. Great competence,Mr.Regan,congratulations!
I (and the Chessdotcom statement) count Bullet as a form of Blitz. Hence, “two categories”.