Making Algorithms Fair
We don’t need to be good. But let’s try to be fair. —Holly Black

|
| FairVis source/personal website |
Jamie Morgenstern is an assistant professor in Computer Science and Engineering at the University of Washington. Previously she was at the School of Computer Science at Georgia Tech—a place where I, Dick, spent some time too. We were sad when Jamie left to go west.
Today we thought we would talk about making algorithms fair.
We will focus on an aspect that first seems like something you would never think of. Then, when you think of it, getting fairness seems impossible. So when I thought of it, Ken and I thought maybe no one else had, and Ken came up only with one maybe-relevant paper that used blockchain. Then I found that some people have thought of it—including Jamie.
You can kind-of just make it out in the “elevator pitch” description of her work at the very top of her personal website:
How should machine learning be made robust to behavior of the people generating training or test data for it? How should ensure that the models we design do not exacerbate inequalities already present in society?
It’s in the word “generating.” Often we generate or select test data randomly. Or at least we say we do. How can we assure that our use of randomness is fair? Is that even a question? After all, randomness doesn’t intend bias. The epitome of randomness is something we call “flipping a fair coin” to begin with.
Never Thought of It
I believe that one of the issues that delayed the rise of fairness as a property of algorithms must be that it is not an obvious property.
First, what makes a Turing machine efficient? Complexity theory is based on time and space which was first defined for Turing machines. This started with the famous 1965 paper, “On the Computational Complexity of Algorithms” by Juris Hartmanis and Richard Stearns. The notion of time is clear—just count each step of the Turing machine. Space is more complicated—just counting squares of the tapes is too simple, one must allow the input tape to be different from the work tape. A workable definition is counting the tape cells that are ever changed.
Next, what makes a Turing machine fair? It seems impossible to imagine a universal definition like the above paper—fairness requires domain-specific information. There is no definition that looks just at the structure of a Turing machine.
So we went past the turn of the millennium without considering fairness, and missed a concept that has been around for millennia more. As stated in last June’s announcement of a Simons collaboration directed by Omer Reingold:
The study of fairness is ancient and multidisciplinary: philosophers, legal experts, economists, statisticians, social scientists and others have been concerned with fairness for as long as these fields have existed. Nevertheless, the scale of decision-making in the age of big data, the computational complexities of algorithmic decision-making and simple professional responsibility mandate that computer scientists contribute to this research endeavor.
Indeed we could quote many others on why fairness is important.
One of the embarrassments is that computer scientists did not study fairness earlier. I must admit I never did too. I was concerned about being “good”: about making algorithms faster and making them use less space. But not being fair.
In Search of Fairness
Okay, fairness requires domain-specific information. But are there some cases that could be defined in a way that avoids specialized knowledge? A more general definition would allow results to have more applications. And one domain that should naturally be more generic is the use of randomness.
The paper that caught my eye is titled, “Equalized odds post processing under imperfect group information,” by Morgenstern with Pranjal Awasthi and Matthaus Kleindessner. They say:
Most approaches aiming to ensure a model’s fairness with respect to a protected attribute (such as gender or race) assume to know the true value of the attribute for every data point. In this paper, we ask to what extent fairness interventions can be effective even when only imperfect information about the protected attribute is available.
At the high level the result is about how the ability to achieveness depends on the amount of information one has about values of the attribute 

Another area that yields a reasonably generic definition of fairness is algorithms for games of chance. The insight is: These all invoke randomness and the algorithms must not cheat. That is the generation and use of randomness must be fair—no cheating.
|
|
| Cropped from CasinosBlockchain.io source |

There are two different types of approaches to making the randomness fair. One uses blockchain technology, as presented in the article accompanying the above picture.
In a contest system on hybrid blockchain Dragonchain, a future hash of Bitcoin and Ethereum that has not been created yet, combined with an algorithm anyone can execute themselves, a provably fair random selection and revealing occurs, which is near impossible to profitably manipulate, as it is backed by hundreds of millions of dollars worth of proof from decentralized blockchains that Interchain with Dragonchain.
Another uses a more standard way to make the randomness secure. Here is one such paper.
In a provably fair gambling system, a player places bets on games offered by the service operator. The service operator will publish a method for verifying each transaction in the game. This is usually done by using open source algorithms for random seed generation, hashing, and for the random number generator.
Once a game has been played, the player can use these algorithms to test the game’s response to their in-game decisions, and evaluate the outcome by only using the published algorithms, the seeds, hashes, and the events which transpired during the game.
In a simplified way, players can always check that the outcome of every game round is fair and wasn’t tampered with, and so can the game’s operators. As such, cheating is arguably impossible.
In Search of Correctness
Let’s look at fairness from a complexity point of view. We are interested in seeing if NP gives us some insight to how to define fairness, at lest for games.
Consider an algorithm 



- Check for each edge
that
and
have different colors.
- Prove that the algorithm
We argue that there is a similar situation with an algorithm 
Trust, but verify.
In the above we can either trust the algorithm
Let’s look at this next.
A Fairness Problem
The question we consider is this: Imagine that 

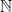

One possible solution is to have an algorithm that operates like this:
- Let us input the
- Then use the acceptance criterion to reduce this to a set
of
people that meet all the criteria.
- Finally randomly select
Note: Any choice of
A Solution
Here is a solution that uses a protocol between the selection algorithm and 
- It is a protocol that uses several players
- Only by having all
- It is public and can be checked after the fact.
- Its correctness assumes standard crypto methods are safe.
The protocol assume that 


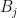





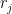


If it is
The claim is that unless the bit method is unsafe or all the players are cheating this is correct.
Open Problems
Does making coin flips fair solve any real problem? Does it help make some algorithms easier to show that they are fair?

|


There is some interesting math in there but the social problem is much deeper. As the various impossibility theorems show actual humans tend to have totally incoherent feelings about unfairness and, described in detail, any algorithm can be made to seem unfair.
For instance, consider the much publicized case of assessing risk of recidivism. The problem is that it both feels unfair for someone to be penalized because of their race in terms of their chance of reoffending and it feels unfair for someone to get a longer sentence than the best estimate of their chance of offending would support. After all, all sorts of the factors being considered are beyond the control of the individual in question (e.g. family support, family money which can purchase rehab, (in part) education level they were able to achieve etc.. etc..) so why should they be sentenced based on a prediction we know exceeds the best prediction. Unless you have complete statistical independence between the sensitive factor and what the algorithm is trying to predict you will have issues. But there are much cleverer ways to put this that really make it hard to reject any standard.
Regarding criminal punishment I don’t believe individualized risk of recidivism judgements is an appropriate way to set sentences in the first place. But for the larger issue it’s not really one for CS but one for sociology and philosophy since the really problem is less convincing people an algorithm has a given property and more deciding what property is desired.