A Vast and Tiny Breakthrough
Christofides bound beaten by an epsilon’s idea of epsilon

|
| src1, src2, src3 |
Anna Karlin, Nathan Klein, and Shayan Oveis Gharan have made a big splash with the number

No that is not the amount of the US debt, or the new relief bill. It is the fraction by which the hallowed 44-year-old upper bound of 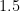
Today we discuss the larger meaning of their tiny breakthrough.
The abstract of their paper is as pithy as can be:
For some
we give a
approximation algorithm for metric TSP.
Metric TSP means that the cost of the tour 

according to a given metric 
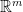
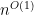

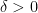


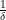


Some intermediate cases of metrics had allowed getting within a factor of 
A Proof in a Pub
Soon after starting as a graduate student at Oxford in 1981, I went with a bunch of dons and fellow students down to London for a one-day workshop where Christofides was among the speakers and presented his result along with newer work. I’d already heard it spoken of as a combinatorial gem and perfect motivator for a graduate student to appreciate the power of combining simplicity and elegance:
-
Calculate the (or a) minimum spanning tree
of the
given points.
-
Take
to be the leaves and any other odd-degree nodes of
of them.
-
The graph
has all nodes of even degree so it has an easily-found Eulerian cycle
.
-
The cycle
giving
.
Now any optimal TSP tour 




My memory of what we did after the workshop is hazy but I’m quite sure we must have gone to a pub for dinner and drinks before taking the train back up to Oxford. My point is, the above proof is the kind that can be told and discussed in a pub. It combines several greatest hits of the field: minimum spanning tree, perfect matching, Euler tour, Hamiltonian cycle, triangle inequality. The proof needs no extensive calculation; maybe a napkin to draw 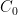
The conversation would surely have gone to the question,
Can the
factor be beaten?
A perfect topic for mathematical pub conversation. Let’s continue as if that’s what happened next—I wish I could recall it.
Trees That Snake Around
Note that the proof already “beats” it in the sense of there being a strict inequality, and it really shows

where 

The staff is a path 




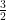


-
The
snake edges, plus one path edge to connect them, make a maximum-weight spanning tree
in the graph
formed by the two kinds of edges. Yet
-
When one is given only the
of the previous path has weight
.
-
Thus
-
The advantage of
that incorporates a term for “odd-closeness.”
In 1981, we would not have known about Arora’s and Mitchell’s results, so we would have felt fully on the frontier by embedding the points in the plane and sketching spanning trees and cycles on a piece of paper. After a couple pints of ale we might have felt sure that a simple proof with such evident slack ought to yield to a more sophisticated attack.
Helpful Trees
There is one idea that we might have come up with in a pub. The motivation for choosing
Oveis Gharan did have such an idea jointly with a different group of authors a decade ago, in the best paper of SODA 2010. We cannot seem to get our hands on the optimal tour, nor even a “good” tour if that means a better than 


The objective then becomes to design distributions 
-
Sampling
is polynomial-time efficient.
-
For every edge
where
is tiny.
-
The distribution
The algorithmic strategy this fits into is to sample
The Proof and the Pudding
The first two conditions are solidly defined. Considerable technical details in the SODA 2010 paper and another paper at FOCS 2011 that was joint with Amin Saberi and Mohit Singh are devoted to them. A third desideratum is that the distribution 

The third condition, however, follows the maxim,
“the proof of the pudding is in the eating.”
As our source makes clear, this does not refer to American-style dessert pudding, but rather savory British pub fare going back to 1605 at least. The point is that we ultimately know a choice of
In America, we tend to say the maxim a different way:
“the proof is in the pudding.”
The new paper uses the “pudding” from the 2011 paper but needed to deepen the proof. Here is where we usually say to refer to the paper for the considerable details. But in this case we find that a number of the beautiful concepts laid out in the paper’s introduction, such as real stability and strong Rayleigh distributions, are more accessibly described in the notes for the first half of a course taught last spring by Oveis Gharan with Klein as TA. One nub is that if a set of complex numbers all have positive imaginary part, then any product 

Rigidity of the TSP Universe
I’ll close instead with some remarks while admitting that my own limited time—I have been dealing with more chess cases—prevents them from being fully informed.
The main remark is to marvel that the panoply of polynomial properties and deep analysis buy such a tiny improvement. It is hard to believe that the true space of TSP approximation methods is so rigid. In this I am reminded of Scott Aaronson’s calculations that a collision of two stellar black holes a mere 3,000 miles away would stretch space near you by only a millimeter. There is considerable belief that the approximation factor ought to be improvable at least as far as 
It strikes me that the maximum-entropy condition, while facilitating the analysis, works against the objective of making the trees more special. It cannot come near the kind of snaky tree 



This forces us to take
very small, which is why we get only a “very slightly” improved approximation algorithm for TSP. Furthermore, since we use OPT edges in our construction, we don’t get a new upper bound on the integrality gap. We leave it as an open problem to find a reduction to the “cactus” case that doesn’t involve using a slack vector for OPT (or a completely different approach).
What may be wanting is a better way of getting the odd-valence tree nodes to be closer, not just fewer in number. To be sure, ideas for “closer” might wind up presupposing a metric topology on the
Open Problems
Will the tiny but fixed wedge below
There is also the kvetch that the algorithm is randomized, whereas the original by Christofides and Serdyukov is deterministic. Can the new methods be derandomized?
[fixed = to + sign at end of Christofides proof; fixed wording of “nub” at end of pudding section; added


Is there connection between UGC and this?