Cleverer Automata Exist
A breakthrough on the separating words problem

|
Zachary Chase is a graduate student of Ben Green at Oxford. Chase has already solved a number of interesting problems–check his site for more details. His advisor is famous for his brilliant work—especially in additive combinatorics. One example is his joint work with Terence Tao proving this amazing statement:
Theorem 1 The prime numbers contain arbitrarily long arithmetic progressions.
Today we wish to report Chase’s new paper on a problem we have twice discussed before.
But first Ken wants to say something about Oxford where he got his degree long before Green arrived.
Oxford Making Waves
Green moved to Oxford in 2013. He holds a professorship associated to Magdalen College. I (Ken) did not know him when I started at Oxford in 1981. It would have been hard, as Green was only 4 years old at the time. But I did know the preteen Ruth Lawrence when she started there and even once played a departmental croquet match including her in which Bryan Birch made some epic long shots. Lawrence had joined St. Hugh’s College in 1983 at the age of twelve.
Oxford has been Dick’s and my mind more in the past six years than before. Both of us were guests of Joël Ouaknine in 2012–2015 when he was there. Oxford has developed a front-line group in quantum computation, which fits as David Deutsch’s role as an originator began from there—note my story in the middle of this recent post.
Recently Oxford has been in the news for developing a promising Covid-19 vaccine. ChAdOx1 heads Wikipedia’s list of candidate vaccines and has gone to final trials, though there is still a long evaluation process before approval for general use.
Before that, a modeling study from Oxford in March raised the question of whether many more people have had Covid-19 without symptoms or any knowledge. This kind of possibility has since been likened to a “dark matter” hypothesis, not just now regarding Covid-19 but a decade ago and before.
A main supporting argument is that a wide class of mathematical models can be fitted with higher relative likelihood if the hypothesis is true. I have wanted to take time to evaluate this argument amid the wider backdrop of controversy over inference methods in physics, but online chess with unfortunately ramped-up frequency of cheating has filled up all disposable time and more.
The Problem
Back to Chase’s new results on the following problem:
Given two distinct binary strings of length
there is always a finite state deterministic automaton (FSA) that accepts one and rejects the other. How few states can such a machine have?
This is called the separating words problem (SWP). Here we consider it for binary strings only.
John Robson proved 


Theorem 2 For any distinct
, there is a finite state deterministic automaton with
states that accepts
but not
.
We previously discussed this twice at GLL. We discussed the background and early results here. The original problem is due to Pavel Goralcik and Vaclav Koubek. They proved an upper bound that was 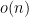
The Approach
All the approaches to SWP seem to have a common thread. They find some family of “hash” functions 
-
Any
in
-
For any
binary strings of length
, there is an
so that
.
The challenge is to find clever families that can do do both. Be easy to compute and also be able to tell strings apart. Actually this is only a coarse outline—Chase’s situation is a bit more complicated.
The Proof
We have taken the statement of Theorem 2 verbatim from the paper. It has a common pecadillo of beginning a sentence for a specific 


A length-![{A \subseteq [n]}](https://s0.wp.com/latex.php?latex=%7BA+%5Csubseteq+%5Bn%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



where 





Then by the Chinese Remainder Theorem, there is a prime 

Now we can make a finite automaton 






Lemma 3 For any distinct
—of size at most
such that for some
,

The power 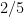








Proposition 4 For all distinct
there is
such that
and

A finite automaton using this extension needs 

Lemma 5 (?) For any distinct
there is a prime
such that for some
Now we need to balance the levers using the proposition and the lemma together. Since 


on the magnitude of the needed primes
Here a famous New Yorker cartoon with the caption “If only it were so simple” comes to mind. But there is a catch. Chase is not quite able to prove lemma 5. However, the 

This is classic high-power mathematics. When some idea is blocked, try to weaken the requirements. Sometimes it is possible to still proceed. It is a lesson that we sometimes forget, but a valuable one nevertheless.
Open Problems
We like the SWP and think Chase’s contribution is impressive. Note that it adds a third element 
We feel there could also be interesting applications for his theorem as it stands. Is the ability to tell two strings apart with a simple device—a FSA with not many states—useful? Could it solve some open problem? It does seem like a basic insight, yet we have no candidate application. Perhaps you have an idea.
[added Q on Lemma 5 to “Open Problems”, “lower” bound –> “upper” bound in third section, update in Open Problems.]


Is there an obv lower bound or a conj of the optimal?
Both are log n. Here is a good survey: https://arxiv.org/abs/1103.4513
This is awesome! I’m still going through, but thanks so much for the nice explanation.
Regarding Lemma 3:
(1) You don’t need to focus on primes for Lemma 3. Actually, I believe that primes add a log factor.
You should be able to show that for distinct A, B subset [n], there exists d = O(sqrt(n)) and i in [d] such that |A(i,d)| != |B(i,d)|. In other words, d doesn’t need to be a prime number which turns your O~ to O.
(2) As far as I can tell, this approach was presented in “Separating Words by Occurrences of Subwords” by Vyalyi and Gimadeev. I mentioned it in the previous comments using a less succinct notation: https://rjlipton.wordpress.com/2019/09/16/separating-words-decoding-a-paper/#comment-105362
Note: My comments (1) and (2) were just in regards to Lemma 3.
What a nice summary! Thanks for bringing attention to this; I really hope someone can improve upon n^(1/3). I wanted to quickly mention that Lemma 5 is not true as stated. For example, for any m, if you take n large enough, you can have A={1} and B={(\prod_{p ≤ m} p)+1}. However, I do think Lemma 5 is true if n is a polynomial of N, with the power of the implicit logarithm for the upper bound on p depending on the degree of the polynomial.
You’re very welcome, and thanks for the note about the queried lemma—I’ve added an update. This has been a personal favourite problem of ours for awhile, besides our both knowing Jeff Shallit for a long time, I all the way back to Princeton undergrad days, and note comments above by my graduated student Mike Wehar.
I came across a technical report from 2016 which claims an O(log n) bound on the number of states required to separate two words (of equal length too) http://invenio.nusl.cz/record/251413/files/content.csg.pdf
Am I missing something?
Dear Anoop SKM:
I believe that the proof is not correct. The machines would work if they scanned the two inputs at the same time. But I will check it out again…
Thanks for comment
Best
Dick
Dear Anoop SKM, dear Dick,
I believe that the proof of Theorem 3.4 in that paper is incorrect. Namely, it tries to prove by contradiction a statement of the form “For all S, P(S)”, but they incorrectly assume “For all S, not P(S)”, instead of “Exists S, not P(S)”. You can see it in the 4th paragraph, the assumption is originally for S, but they also use it for S’.
More generally, this theorem proves that for all n and set S \subseteq [n], there exists i such that R_S(i, p_k) contains an odd number of elements, where p_k is the smallest prime such that “p_k# > n” (p_k# = p_1 * p_2 * … * p_k is the product of the first k primes).
Moreover, it is easy to find a counterexample to their statement using a small program (it boils down to solving linear equations in F2).
Here is one: n = 30 = 235, so p_k is 7. Yet, if you consider the set S = {0, 2, 3, 4, 6, 7, 9, 10, 14, 15, 17, 18, 20, 21, 22, 24}, then for any prime number p = 2,3,5,7,11, R_S(i, p) contains an even number of elements. Notice that it works for 7, but also for 11. So it cannot be easily fixed by taking p_{k+1} instead of p_k. Similarly, you can find counter examples with a larger gap (i.e. n = p_k#, but R_S(i, p) is odd for every i and every p up to p_{k+t} for arbitrarily large t).
So I believe that the construction in the paper (Testing the parity of R_S(i, p)) is correct, but definitely not for p = O(log n).
Best,
Gabriel