Separating Words by Automata
Another exponential gap in complexity theory?

|
| [ From his home page ] |
Jeffrey Shallit is a famous researcher into many things, including number theory and being a skeptic. He has a colorful website with an extensive quotation page—one of my favorites by Howard Aiken is right at the top:
Don’t worry about people stealing an idea. If it’s original, you will have to ram it down their throats.
Today I thought I would discuss a wonderful problem that Jeffrey has worked on.
Jeffrey’s paper is joint with Erik Demaine, Sarah Eisenstat, and David Wilson. See also his talk. They say in their introduction:
Imagine a computing device with very limited powers. What is the simplest computational problem you could ask it to solve? It is not the addition of two numbers, nor sorting, nor string matching—it is telling two inputs apart: distinguishing them in some way.
More formally:
Let
and
be two distinct
long strings over the usual binary alphabet. What is the size of the smallest deterministic automaton
that can accept one of the strings and reject the other?
That is, how hard is it for a simple type of machine to tell 

Some History
Pavel Goralčik and Vaclav Koubek introduced the problem in 1986—see their paper here. Suppose that 

Theorem 1 For all distinct binary words

That is the size of the automaton is asymptotically sub-linear. Of course there is trivially a way to tell the words apart with order
In 1989 John Robson obtained the best known result:
Theorem 2 For all distinct binary words

This bound is pretty strange. We rarely see bounds like it. This suggest to me that it is either special or it is not optimal. Not clear which is the case. By the way it is also known that there are

Thus there is an exponential gap between the known lower and upper bounds. Welcome to complexity theory.
What heightens interest in this gap is that whenever the words have different lengths, there is always a logarithmic-size automaton that separates them. The reason is our old friend, the Chinese Remainder Theorem. Simply, if 




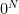




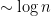
Some other facts about SWP can be found in the paper:
- (a) It does not matter whether the alphabet is binary or larger.
-
(b) For random distinct
, the expected number of states needed to separate them is at most
.
-
(c) All length-
.
Point (b) underscores why it has been hard to find “bad pairs” that defeat all small DFAs. All this promotes belief that logarithmic is the true upper bound as well. Jeffrey stopped short of calling this a conjecture in his talk, but he did offer a 100-pound prize (the talk was in Britain) for improving Robson’s bound.
Some Questions
There are many partial results in cases where


Recall 

Open Problems
The SWP is a neat question in my opinion. I wonder if there would be some interesting consequence if we could always tell two words apart with few states. The good measure of a conjecture is: how many consequences are there that follow from it? I wonder if there could be some interesting applications. What do you think?


The bound in Robson’s theorem very vaguely looks like bounds on integer factorization, with an exponential shift though. Using the [L-notation](https://en.wikipedia.org/wiki/L-notation): L_n[x, c] = exp((c+o(1)) (ln n)^x (ln ln n)^(1-x)), Robson’s bound can be written ln( L_{exp(n)}[2/5, c] ) for some c.
In other words, there is this “trade-off” between the exponent of n and the exponent of log(n), where the two sum to 1, that we find in the complexities of fast integer factorization algorithms.
The quantum version of this problem is also interesting: We conjectured that a complex-valued (logical) qubit is enough to distinguish the given pair of the strings with zero-error.
Aleksandrs Belovs, J. Andres Montoya, Abuzer Yakaryilmaz:
On a Conjecture by Christian Choffrut. Int. J. Found. Comput. Sci. 28(5): 483-502 (2017)
https://www.worldscientific.com/doi/abs/10.1142/S0129054117400032
An earlier arXiv version can be accessible from here: https://arxiv.org/abs/1602.07967
English person here.
“a 100-pound prize” sounds wrong, although “a 100-dollar prize” sounds ok; “a prize of 100-pounds sounds” fine.
Taking a cue from Babai’s quasipolynomial time graph isomorphism algorithm, we could try to split the problem into two cases. In one case, the strings are so different that there has to be an easy way to tell them apart locally. In the other case, the strings are so similar that they have to have some shared global structure that we can exploit.
For example, we might try to find some function f(n) and split on whether the Hamming distance between the strings is more or less than f(n). We know from the paper that O(1) Hamming distance between x and y is sufficient to guarantee sep(x, y) = O(log(n)) — maybe this result could be extended to larger Hamming distances. But we could also use some other similarity condition besides Hamming distance.
In the case where the strings have lots of differences, then maybe we can use some Ramsey theory result to show that any string pair with that many differences must have some easily recognizable difference between them.
In the case where the strings are very similar, then maybe we can use this to show that there must exist some small noncommutative group, such that we can map each fixed-size chunk of the input onto a generator of the group so that the product of the group elements in string 1 is different than the product of the group elements in string 2. This is different than the “permutation automata” mentioned in the paper because we are allowed to choose how large we want the chunks to be based on the particular input strings to give us more options for finding a suitable group. Also, by restricting this case to only be used when the strings are very similar, we may be able to get better bounds than the existing bounds for permutation automata on arbitrary strings.
The mention of group theory in the context of finite state machines also reminds me of the proof of Barrington’s theorem. Maybe there is something we can borrow from there.
Anyway, bumping my comment on the previous post because it is more relevant to this post: https://rjlipton.wordpress.com/2019/09/04/self-play-is-key/#comment-104679
I wonder if SWP is related to the simplicity of “increment & branch” Universal Turing machine?
(Resubmitting my comment from this morning because it seems like WordPress might have eaten it for containing a link?)
Taking a cue from Babai’s quasipolynomial time graph isomorphism algorithm, we could try to split the problem into two cases. In one case, the strings are so different that there has to be an easy way to tell them apart locally. In the other case, the strings are so similar that they have to have some shared global structure that we can exploit.
For example, we might try to find some function f(n) and split on whether the Hamming distance between the strings is more or less than f(n). We know from the paper that O(1) Hamming distance between x and y is sufficient to guarantee sep(x, y) = O(log(n)) — maybe this result could be extended to larger Hamming distances. But we could also use some other similarity condition besides Hamming distance.
In the case where the strings have lots of differences, then maybe we can use some Ramsey theory result to show that any string pair with that many differences must have some easily recognizable difference between them.
In the case where the strings are very similar, then maybe we can use this to show that there must exist some small noncommutative group, such that we can map each fixed-size chunk of the input onto a generator of the group so that the product of the group elements in string 1 is different than the product of the group elements in string 2. This is different than the “permutation automata” mentioned in the paper because we are allowed to choose how large we want the chunks to be based on the particular input strings to give us more options for finding a suitable group. Also, by restricting this case to only be used when the strings are very similar, we may be able to get better bounds than the existing bounds for permutation automata on arbitrary strings.
The mention of group theory in the context of finite state machines also reminds me of the proof of Barrington’s theorem. Maybe there is something we can borrow from there.
Anyway, bumping my comment on the previous post because it is more relevant to this post: (link to my comment on the “Self-Play Is Key?” post snipped to avoid offending the WordPress gods)
I feel like I’m missing something important here.
For each x,y pair, SEP(x,y) can be a different Turing machine, correct? And since x!=y, there must be a bit position m <= n such that they differ on that position. So why can't you just count over m bits, and halt accepting or rejecting based on the value of that bit? I don't see why we'd need more than O(log m) states to do this counting, so why isn't the answer O(log n) in worst case? There must be something in the problem statement I'm missing, or something wrong with my solution, because this is too simple. What am I missing here?
Doh. Its “automaton” not turing machine.
You can do it using $\log m$ bits of memory, which is $m$ states, not $\log m$ states.
Any two n-bit strings can be separated by a Turing machine with only O(log(n)/log(log(n))) states. It’s surprising that you can do better than O(log(n)).
You essentially encode the least point where the two strings differ into the transition diagram in a clever way.
The details can be a little tricky, but I wrote it up a few years ago.
A collaborator of mine informed me that this method was already in the literature, but I don’t recall the paper’s name.
If anyone happens to be interested in this, please let me know. Thank you!
That is surprising and interesting. I would like to hear more, or even just a reference if you find that paper.
Thank you very much for the reply! I really appreciate it. 🙂
Here is my write-up from a few years ago: http://michaelwehar.com/documents/mwehar_FPII_12_28_13.pdf
The write-up was from summer research I did in 2013. It’s a bit rough, but I would be happy to explain the argument if you contact me via email.
Here is a paper by Dmitry Chistikov that is also relevant: drops.dagstuhl.de/opus/volltexte/2014/4854/pdf/30.pdf
Hope that you have a nice day!
Dear Michael:
Thanks and hope all going well. The TM question is interesting. Hmmm.
Best
Dick
Reblogged this on Pink Iguana.
Dear E. L. Wisty:
Thanks very much.
Best
Dick
Here is another easy upper bound for this problem. Suppose x and y are binary words, and the binary integer value of x is not congruent to the binary integer value of y modulo some positive integer m. Then SEP(x, y) ≤ m, because we can compute remainder mod m using a DFA with m states (or fewer, see Suttner (2009). “Divisibility and State Complexity”).
In particular, this means that any string pair that requires more than O(log n) states to separate must be congruent modulo the first O(log n) positive integers—while at the same time satisfying all the other restrictions. Quite the balancing act! Can any strings pull it off?
Dear Aaron Rotenberg:
Thanks for comment. I think modulo is too weak. Think this way. Let h(x) be the hash function that maps string x to a value modulo n to some power. By pigeonhole it follows that there distinct x and y so that h(x)=h(y). But then the outlined method would fail. Note this works for much larger number of states.
Did I miss something?
Best
Dick
We have another variable free when designing a congruence machine. In addition to the modulus q, we also can choose the base b of the two numbers represented by our two words, so each word represents the coefficients of an n-degree polynomial in b over Z/q. If the difference D of these two polynomials is not identically zero mod q then there is some b which distinguishes the two words with q states. I think this should give an O(sqrt(n)) bound.
D has coefficients only in {-1, 0, 1}. Borwein has some papers on polynomials with these restricted coefficients, so there may exist some bounds on zeroes of these polynomials over finite fields that could be used.
It does not help to interpret “0” and “1” as some other base-b digits c and d, as D would then have coefficients in {(c-d), 0, -(c-d),} so (c-d) factors out and does not help distinguish words.
However, interpret symbols in our words pairwise as codes for four distinct coefficients of n/2-degree polynomials at an expense of increasing the number of states by a factor of 4. Then D has up to 13 distinct coefficients mod q which can be chosen so as not to factor out. Does the freedom to choose coefficient values here add distinguishing power?
Dear Jordan:
Thanks for thinking some more. I am not clear what you are doing here. The rough trouble is this: This idea is trying to find a machine that separates S and T but does not depend on them. That is why taking them mod small q is too weak. The same is true for playing with the base and so on.
There are strings so the method must depend on the strings to have a chance. Am I getting the idea correctly?
strings so the method must depend on the strings to have a chance. Am I getting the idea correctly?
Best
Dick
Right, b would be a free parameter and would depend on the input strings. A fixed-base modulus q would hash strings into q buckets. So instead of a fixed hash h(x), you’d have a parameterized hash h(x,b) where b is also modulo q.
The idea behind treating blocks of symbols as symbols in a larger alphabet is to give some more free parameters to enter in as coefficients.
Hashing function for binary strings h(x, p, a)= sum^{i<n}_{i=a mod p} & x_i = 1 may also be interesting I think. If for two strings x and y h(x,p,a)!=h(y,p,a) with p = O(log n) than strings can be separated with Polylog states. How much strings cannot be separated by this hashing?