Discrepancy Games and Sensitivity
Can we connect the talks that closed this month’s Random Structures and Algorithms conference?

|
| Cropped from NYU homepage |
Joel Spencer gave the closing talk of last week’s Random Structures and Algorithms conference at ETH Zurich.
Today we discuss his talk and the one that preceded it, which was by Hao Huang on his proof this month of the Boolean sensitivity conjecture.
Spencer’s talk was titled “Four Discrepancies” and based on a joint paper with Nikhil Bansal. The main new result in the talk was a case where a bound of 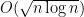
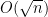
We will talk about this first, but then progress to the talk that preceded Spencer’s. It was by Hao Huang, who was extended an invitation right after his announced proof of the Boolean Sensitivity Conjecture earlier this month. Our ulterior purpose is to ask whether any concrete connections can be found besides both talks addressing problems on the 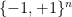
Discrepancy Games
First suppose you get a stream of single bits 







Now suppose the bits come in pairs 


The trouble with extending this idea to vectors of length 



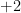
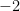

A final help is if we know the number 
- Does it matter whether the sequence of vectors given is random or worst-case?
- Can you do better than choosing “keep” or “flip” randomly?
Long back, Spencer proved that if you can see the whole sequence of 
Theorem 1 If an adversary can choose the next vector based on your current sums, then the best bound
such that you can keep all your sums within absolute value
. Moreover, up to the constant in the “
” with high probability you cannot do any better than choosing the sign for each vector randomly.
See also his famous book, The Probabilistic Method, with Noga Alon. The new theorem is:
Theorem 2 If the adversary presents vectors uniformly at random, then you can achieve
with high probability—and not by choosing the signs randomly.
The algorithm defines a kind of potential function and has you play “keep” or “flip” according to which has the lesser growth in potential. The analysis is quite complicated. As usual we refer to the paper for details. Instead we ask: are there insights to mine here for further advances on the Boolean sensitivity problem?
Boolean Sensitivity
We didn’t talk about Boolean sensitivity in our previous post on it. Our purpose now is to convey how many concepts are related, hence how they might connect to discrepancy on the hypercube.
To get the idea of sensitivity, first consider the parity function 





The OR function 


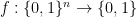

The OR-of-AND function 









If we make each block of 





We can, however, consider ![{[n]}](https://s0.wp.com/latex.php?latex=%7B%5Bn%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)





Note that not every member of the partition has to flip the function—we can discard the ones that don’t flip and count only the disjoint subsets that do flip the value. So back to our example, we have

Andris Ambainis and Xiaoming Sun improved the constant from 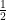
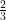
Some Boolean Complexity Connections
This example of quadratic discrepancy is still the best known lower bound on 

 .
.
This bound is concrete, not just asymptotic. It still leaves a gap between quadratic and quartic. It is, however, the combination of two quadratic upper bounds. One was shown by Nisan and Szegedy in their paper:

where 

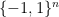

in a 1992 paper by Craig Gotsman and Nati Linial. Huang proved this by exploiting a connection to graphs that was also shown by Gotsman and Linial. Consider any red-or-white coloring of the 





is not very sensitive. Moreover, it has the same sensitivity as the function 


Theorem 4 Provided
, every graph
induced by
nodes of the
-cube has
if and only if every Boolean function
has
.
The proof uses some Fourier analysis with 
The main open question now is whether the 4th-power upper bound in Huang’s theorem 3 can be improved to quadratic. It is possible that a deeper application of Fourier analysis may show that cases of quadratic separation from block-sensitivity to degree and degree to sensitivity cannot “amplify” any more than quadratic. This is where there might be some commonality with discrepancy.
There is a much wider suite of Boolean complexity measures besides 

![{I \subseteq [n]}](https://s0.wp.com/latex.php?latex=%7BI+%5Csubseteq+%5Bn%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)





Weak Adjacency Matrices
We—that is Ken and I—have been thinking about how to build on Huang’s proof. We take a somewhat more-general approach compared to the paper and Ken’s post.
Definition 5 Let
is a weak adjacency matrix of
- Every entry
is bounded by
in absolute value;
- For all
if
is not an edge in
.
As usual the maximum degree of 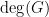
Lemma 6 (H-Lemma) Suppose that
is an eigenvalue of

Proof: By the definition of eigenvalue, there is some non-zero vector 



But then the last sum is upper bounded by

where 



Dividing by 

Let 


Lemma 7 Suppose that
,
is a weak adjacency matrix of
.
Proof: The bound on the entries of 
Lemma 8 Suppose that
. Then every induced subgraph
of
vertices has degree at least
Definition 9 The hypercube
is the graph on
Theorem 10 The hypercube
.
Proof: Let 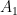

and 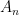

Induction shows that 

implies that

Thus

So the eigenvalues are 
The upper-left and lower-right blocks of 

Corollary 11 Every induced subgraph
vertices has degree at least
.
Open Problems
Can the last two talks at the conference be further connected?
Trackbacks
- Amazing: Hao Huang Proved the Sensitivity Conjecture! | Combinatorics and more
- Animated Logical Graphs • 24 | Inquiry Into Inquiry
- La conjetura de la sensibilidad ha sido demostrada - La Ciencia de la Mula Francis
- Animated Logical Graphs • 28 | Inquiry Into Inquiry
- Paul Balister, Béla Bollobás, Robert Morris, Julian Sahasrabudhe, and Marius Tiba: Flat polynomials exist! | Combinatorics and more
- Predicting Predictions For the 20s | Gödel's Lost Letter and P=NP
- Animated Logical Graphs • 28 | Inquiry Into Inquiry


Just by way of a general observation, concepts like discrepancy, influence, sensitivity, etc. are differential in character, so I tend to think the proper grounds for approaching them more systematically will come from developing the logical analogue of differential geometry.
[edited]
edit: delete 2nd “them”
Dear Jon Aubrey:
I edited your comment. Also thanks as always for your comments. I like the view that could be generalized to handle diff operators. I will ponder this.
Best
Dick
Dear Professor Lipton,
Thanks for the reply and edit. I took a few steps in this direction some years ago in connection with an effort to understand a certain class of intelligent systems as dynamical systems. There’s a motley assortment of links here:
• Survey of Differential Logic
Regards,
Jon
Here’s a series of posts where I looked at links between logical differential operators and the brand of Boolean influence you applied to the Frankl Conjecture:
• Frankl Conjecture
Bhansal –> Bansal
Thanks!