Timing Leaks Everything
Facing the awful truth that computers are physical machines

|
| As moderator of RSA 2016 panel |
Paul Kocher is the lead author on the second of two papers detailing a longstanding class of security vulnerability that was recognized only recently. He is an author on the first paper. Both papers credit his CRYPTO 1996 paper as originating the broad kind of attack that exploits the vulnerability. That paper was titled, “Timing attacks on implementations of Diffie-Hellman, RSA, DSS, and other systems.” Last week, the world learned that timing attacks can jeopardize entire computing systems, smartphones, the Cloud, everything.
Today we give a high-level view of the Meltdown and Spectre security flaws described in these papers.
Both flaws are at processor level. They are ingrained in the way modern computers operate. They are not the kind of software vulnerabilities that we have discussed several times before. Both allow attackers to read any memory location that can be mapped to the kernel—which on most computers allows targeting any desired memory contents. Meltdown can be prevented by software patches—at least as we know it—but apparently no magic bullet can take out Spectre.
Kocher was mentioned toward the end of a 2009 post by Dick titled, “Adaptive Sampling and Timed Adversaries.” This post covered Dick’s 1993 paper with Jeff Naughton on using timing to uncover hash functions. Trolling for hash collisions and measuring the slight delays needed to resolve them required randomized techniques and statistical analysis to extract the information. No such subtlety is needed for Meltdown and Spectre—only the ability to measure time in bulky units.
Running On Spec
The attacks work because modern processors figuratively allow cars—or trolleys—to run red lights. An unauthorized memory access will raise an exception but subsequent commands will already have been executed “on spec.” Or if all the avenue lights are green but the car needs to turn at some point, they will still zoom it ahead at full speed—and weigh the saving of not pausing to check each cross-street versus the minimal backtrack needed to find a destination that is usually somewhere downtown.
Such speculative execution leverages extra processing capacity relative to other components to boost overall system speed. The gain in time from having jumped ahead outweighs the loss from computing discarded continuations. The idea of “spec” is easiest to picture when the code has an if-else branch. The two branches usually have unequal expected frequencies: the lesser one may close a long-running loop that the other continues, or may represent failure of an array-bounds test that generally succeeds. So the processor applies the scientific principle of induction to jump always onto the fatter branch, backtracking when (rarely) needed.
Meltdown applies to the red-light situation, Spectre to branches. Incidentally, this is why the ghost in the logo for Spectre is holding a branch:

The logos were designed by Natascha Eibl of Graz, Austria, whose artistic website is here. Four authors of both papers are on the faculty of the Graz University of Technology, which hosts the website for the attacks. The Graz team are mostly responsible for the fix to Meltdown called KPTI for “kernel page-table isolation,” but the Spectre attack is different in ways that make it inapplicable.
There have been articles like this decrying the spectre of a meltdown of the whole chip industry. We’ll hold off on speculating about impending executions and stay with describing how the attacks work.
Meltdown Example in C-like Code
The Meltdown paper gives details properly in machine code, but we always try to be different, so we’ve expressed its main example in higher-level C code to convey how an attacker can really pull this off.
To retrieve the byte value 




object Q; //loaded into chip memory
byte b = 0;
while (b == 0) {
b = K[x]; //violates privilege---so raises an exception
}
Q = A[b]; //should not be executed but usually is
//continue process after subprocess dies or exception is caught:
int T[256];
for (int i = 0; i < 256; i++) {
T[i] = the time to find A[i];
}
if T has a clear minimum T[i] output i, else output 0.
What happens? Let’s first suppose 
![{A[b]}](https://s0.wp.com/latex.php?latex=%7BA%5Bb%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{T[i]}](https://s0.wp.com/latex.php?latex=%7BT%5Bi%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

The reason for the special handling of 

A second key point is that Intel processors allow the speculatively executed code the privilege needed to read 
Spectre
The Spectre attack combines “spec” with the old bugaboo of buffer overflows. Enforcing array bounds is not only for program correctness but also for securing boundaries between processes. The attacker uses an array 


![{B[x]}](https://s0.wp.com/latex.php?latex=%7BB%5Bx%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

if (x < s) { y = A[256*B[x]]; }
To create the delay during which the body will execute speculatively, the attacker next thrashes the cache so that 
![{b = B[x]}](https://s0.wp.com/latex.php?latex=%7Bb+%3D+B%5Bx%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Spectre is more difficult to exploit but what makes it scarier is that now the out-of-bounds access is not treated as guarded by a higher privilege level: it involves the attacker’s own array 
![{B[x']}](https://s0.wp.com/latex.php?latex=%7BB%5Bx%27%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The paper concludes with variants that allow similar timing attacks to operate under even weaker conditions. One does not even need to manipulate the cache beforehand. The last one is titled:
Leveraging arbitrary observable effects.
That is, let 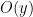

if (x < s) {
y = A[256*B[x]];
O(y);
}
Open Problems
We’ve talked about timing attacks, but can we possibly devise a concept of timing defenses? On first reflections the answer is no. Ideas of scrambling data in memory space improve security in many cases, but scrambling computations in time seems self-defeating. Changing reported timings randomly and slightly in the manner of differential privacy is useless because the timing difference of the cached item is huge. Computers need to assure fine-grained truth in timing anyway.
Besides timing, there are physical effects of power draw and patterns of electric charge and even acoustics in chips that have been exploited. Is there any way the defenders can keep ahead of the attackers? Can the issues only be fixed by a whole new computing model?
[some word and format changes, qualified remark on software nature in intro and linked more related posts]


As you suggest, one way to prevent this is to not allow unprivileged code to perform accurate timings. I don’t immediately see why this would be bad. How often does code actually need to do accurate timings?
Userspace drivers come to mind, as many communication protocols are quite time-sensitive (e.g. RS-232). Forcing all drivers to be kernel-level would also be a security hazard. Other network communications, for instance multiplayer gaming requires high resolution timing to order events. Even where perhaps not strictly needed, high-resolution timestamps are pretty pervasive currently, e.g. Chrome profiles events to µs resolution.
Even if you limited accuracy to something quite slow (say, ms), my instinct is that this could be overcome by repeating the operation enough. If meltdown reads 500kB/s, then even if timings were artificially 1000x less accurate than today then it would still be feasible to read your ssl key in couple seconds.
> Both flaws are at processor level. They are ingrained in the way modern computers operate. They are not faults of software.
Those are *microcode bugs*. Microcode is software! So much so that it is patchable (in fact most Linux distributions have such patches by now and will them automatically).
Thanks. The quoted part reflected () this sentence in the Meltdown paper’s abstract: “The attack is independent of the operating system, and it does not rely on any software vulnerabilities.” and () the reasons why Spectre “will haunt for a long time.” But I’ve changed the last part to say, “They are not the kind of software vulnerabilities that we have discussed several times before.” While composing the HTML I’d thought of but avoided linking some previous security posts—now I’ve done so under the last seven words.
Thanks! Also note that the microcode update mitigates both Meltdown and Spectre (at least for Intel?)
Is there a short explanation as to why AMD processors do not have this issue?
For Meltdown the point is that the Intel processors allow the required gain in privilege. Spectre applies to AMD and processor families quite generally.