Level By Level
Impetus to study a new reducibility relation

|
| See Mike’s other projects too |
Michael Wehar has just earned his PhD degree in near-record time in my department. He has posted the final version of his dissertation titled On the Complexity of Intersection Non-Emptiness Problems which he defended last month. The dissertation expands on his paper at ICALP 2014, joint paper at ICALP 2015 with Joseph Swernofsky, and joint paper at FoSSaCS 2016.
Today, Dick and I congratulate Mike on his accomplishment and wish him all the best in his upcoming plans, which center on his new job with CapSen Robotics near Pitt and CMU in Pittsburgh.
Mike’s thesis features a definition that arguably has been thought about by researchers in parameterized complexity but passed over as too particular. If I were classifying his definition like salsa or cheddar cheese,
- Mild;
- Medium;
- Sharp;
then Mike’s definition would rate as
- Extra Sharp.
Too sharp, that is, for 


What are the relationships between the
levels of deterministic versus nondeterministic time and/or space, and versus
or
“Fairly counted” space means that we cast away the “linear space-compression” theorem by restricting Turing machines to be binary, that is to use work alphabet 
Questions about particular polynomial-time exponents and space-usage factors animate fine-grained complexity, which has seen a surge of interest recently. Consider this problem which is central in Mike’s thesis:
-
Intersection (Non-)Emptiness
: Given
automata
, each with
states, is
?
The “naive” Cartesian product algorithm works in time basically 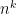



Mike’s thesis expands the mechanism that produces this and related results, with the aim of a two-pronged attack on complexity bounds. He has framed it in terms of parameterized complexity, which we’ll discuss before returning to the thesis.
Some Fixed-Parameter Basics
Consider three classic 
-
Vertex Cover: Is there
of size at most
?
-
Clique: Is there
-
Dominating Set: Is there
Parameterized complexity started with the question:
What happens when some value of the parameter
is fixed?
For each problem 



Can we solve each slice faster? In particular, can we solve
in time
where the exponent
is fixed independent of
The start of much combinatorial insight and fun is that the three problems appear to give three different answers:
-
Vertex Cover: Build
in a fixed order. If neither
nor
already belongs to
when we accept if it’s a cover. If not, start over and try the next string in
to guide the choices. This gives time
for some fixed
.
-
Clique: We can get
where
(see this), but the exponent is still linear in
-
Dominating Set: No algorithm with time better than
is known or expected.
The exact 


Parameterized Reductions and Logspace
To exemplify an FPT-reduction, consider the problem
-
Short NTM Acceptance: Does a given nondeterministic Turing machine
accept the empty string within
When 








FPT-reductions work similarly to ordinary polynomial-time reductions. If our NTM problem belongs to ![{\mathsf{W[1]}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BW%5B1%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{\mathsf{W[2]}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BW%5B2%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\mathsf{W[2] = W[1]}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BW%5B2%5D+%3D+W%5B1%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Just like all major 







All four of our problems belong to 

LBL Reductions
Our reduction from Clique to Short NTM Acceptance bumped 

- polynomially, or
- linearly.
But before now, we haven’t noted in this line a strong motivation to limit the blowup even further, such as to 


Our reduction also bumped up the alphabet size. This appears necessary because for binary NTMs the problem is in 
So what can we do if we insist on binary TMs? Mike and Joseph fastened on to the idea of making the 
The
Definition 1 A parameterized problem
LBL-reduces to a parameterized problem
if there is a function
computable in
space such that for all
and
, where
That is, in the general FPT-reduction form 


|
| With our Chair, Chunming Qiao, and his UB CSE Graduate Leadership Award. |
Some Results
The first reason to care about the sharper reduction is the following theorem which really summarizes known diagonalization facts. The subscript 
![{\mathsf{DTIME}[n^{ck}]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BDTIME%7D%5Bn%5E%7Bck%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Theorem 2
- If a parameterized problem
and all
.
- If a parameterized problem
.
- If
.
Moreover, if there is a constant
such that each
belongs to
,
, or
, respectively, then these become LBL-equivalences.
The power, however, comes from populating these hardnesses and equivalences with natural problems. This is where the 
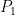

by the name 

Theorem 3
is LBL-equivalent to Log NTM Acceptance. Hence there is a
.
is LBL-equivalent to Medium DTM Acceptance. Hence there is a
.
Between the ICALP 2015 paper and writing the thesis, Mike found that the consequence of (a) had been obtained in a 1985 paper by Takumi Kasai and Shigeki Iwata. Mike’s thesis has further results establishing a whole spectrum of
Onto Bigger Questions
The way the attack on complexity questions is two-pronged is shown by considering the following pair of results.
Theorem 4
if and only if
Theorem 5 If for every
there is a
, then
.
It has been known going back to Steve Cook in 1971 that logspace machines with one auxiliary pushdown, whether deterministic or nondeterministic, capture exactly 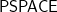
What Mike’s theorem does is shift the combinatorial issue to what happens when the pushdown is added to a collection of DFAs. Unlike the case with an auxiliary pushdown to a 
At the very least, Mike’s LBL notion provides a succinct way to frame finer questions. For example, how does 
![{\mathsf{DTIME[n^k]}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BDTIME%5Bn%5Ek%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\mathsf{DSPACE[n^k]}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BDSPACE%5Bn%5Ek%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


Theorem 6
if and only if
and
are LBL-equivalent.
Mike’s thesis itself is succinct, at 73 pages, yet contains a wealth of other
Open Problems
How can one appraise the benefit of expressing “polynomial” and “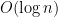
It has been a pleasure supervising Mike and seeing him blaze his way in the larger community, and Dick and I wish all the best in his upcoming endeavors.
[fixed first part of Theorem 2, added link to Cygan et al. 2011 paper, added award photo]


Interesting post! A remark wrt. the line “But before now, we haven’t noted a strong motivation to limit the blowup even further, such as to {k” = k + o(k)} or {k” = k + d} for some fixed constant {d}”. This is the central point in lower bounds under the Strong ETH, see for example the “On problems as hard as CNF-SAT” paper by Cygan et al
Thanks, Daniel! In that line, reference within parameterized complexity was meant. But I’ll consider further.
Thank you very much for sharing the paper. It’s great!
By the way, I am a big fan of your book “Parameterized Algorithms”!
Thanks, glad you liked it [it]!