We revisit a paper from 1994

Richard Lipton is, among so many other things, a newlywed. He and Kathryn Farley were married on June 4th in Atlanta. The wedding was attended by family and friends including many faculty from Georgia Tech, some from around the country, and even one of Dick’s former students coming from Greece. Their engagement was noted here last St. Patrick’s Day, and Kathryn was previously mentioned in a relevantly-titled post on cryptography.
Today we congratulate him and Kathryn, and as part of our tribute, revisit a paper of his on factoring from 1994.
They have just come back from their honeymoon in Paris. Paris is many wonderful things: a flashstone of history, a center of culture, a city for lovers. It is also the setting for most of Dan Brown’s novel The Da Vinci Code and numerous other conspiracy-minded thrillers. Their honeymoon was postponed by an event that could be a plot device in these novels: the Seine was flooded enough to close the Louvre and Musée D’Orsay and other landmarks until stored treasures could be brought to safe higher ground.
It is fun to read or imagine stories of cabals seeking to collapse world systems and achieve domination. Sometimes these stories turn on scientific technical advances, even purely mathematical points as in Brown’s new novel, Inferno. It needs a pinch to realize that we as theorists often verge on some of these points. Computational complexity theory as we know it is asymptotic and topical, so it is a stretch to think that papers such as the present one impact the daily work of those guarding the security of international commerce or investigating possible threats. But from its bird’s-eye view there is always the potential to catch a new glint of light reflected from the combinatorial depths that could not be perceived until the sun and stars align right. In this quest we take a spade to dig up old ideas anew.
 |
Pei’s Pyramid of the Louvre Court = Phi delves out your prime factor… (source)
|
The Paper and the Code
The paper is written in standard mathematical style: first a theorem statement with hypotheses, next a series of lemmas, and the final algorithm and its analysis coming at the very end. We will reverse the presentation by beginning with the algorithm and treating the final result as a mystery to be decoded.
Here is the code of the algorithm. It all fits on one sheet and is self-contained; no abstruse mathematics text or Rosetta Stone is needed to decipher. The legend says that the input  is a product of two prime numbers,
is a product of two prime numbers,  is a polynomial in just one variable, and
is a polynomial in just one variable, and 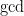 refers to the greatest-common-divisor algorithm expounded by Euclid around 300 B.C. Then come the runes, which could not be simpler:
refers to the greatest-common-divisor algorithm expounded by Euclid around 300 B.C. Then come the runes, which could not be simpler:
-
Repeat until exit:
-
 a random number in
a random number in  ;
;
-
 ;
;
-
if
 then exit.
then exit.
Exiting enables carrying out the two prime factors of —but a final message warns of a curse of vast unknowable consequences.
How many iterations must one expect to make through this maze before exit? How and when can the choice of the polynomial speed up the exploration? That is the mystery.
Our goal is to expose the innards of how the paper works, so that its edifice resembles another famous modern Paris landmark:

This is the Georges Pompidou Centre, whose anagram “go count degree prime ops” well covers the elements of the paper. Part of the work for this post—in particular the possibility of improving  to
to  —is by my newest student at Buffalo, Chaowen Guan.
—is by my newest student at Buffalo, Chaowen Guan.
A First Analysis
Let  with
with  and
and  prime. To get the expected running time, it suffices to have good lower and upper bounds
prime. To get the expected running time, it suffices to have good lower and upper bounds
![\displaystyle \pi_p \leq \Pr_a[\phi(a) \equiv 0 \!\!\pmod{p}] \leq \rho_p](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cpi_p+%5Cleq+%5CPr_a%5B%5Cphi%28a%29+%5Cequiv+0+%5C%21%5C%21%5Cpmod%7Bp%7D%5D+%5Cleq+%5Crho_p+&bg=ffffff&fg=000000&s=0&c=20201002)
and analogous bounds  for . Then the probability
for . Then the probability  of success on any trial
of success on any trial  is at least
is at least

This lower bounds the probability of  , whereupon
, whereupon  gives us the factor .
gives us the factor .
We could add a term  for the other way to have success, which is
for the other way to have success, which is 
 . However, our strategy will be to make
. However, our strategy will be to make  and hence
and hence  close to
close to  by considering cases where
by considering cases where  but is still large enough to matter. Then we can ignore this second possibility and focus on
but is still large enough to matter. Then we can ignore this second possibility and focus on  . At the end we will consider relaxing just so that is bounded away from
. At the end we will consider relaxing just so that is bounded away from  .
.
Note that we cannot consider the events  and
and  to be independent, even though and are prime, because
to be independent, even though and are prime, because  and may introduce bias. We could incidentally insert an initial text for
and may introduce bias. We could incidentally insert an initial text for  without affecting the time or improving the success probability by much. Then conditioned on its failure, the events
without affecting the time or improving the success probability by much. Then conditioned on its failure, the events  and
and  become independent via the Chinese Remainder Theorem. This fact is irrelevant to the algorithm but helps motivate the analysis in part.
become independent via the Chinese Remainder Theorem. This fact is irrelevant to the algorithm but helps motivate the analysis in part.
This first analysis thus focuses the question to become:
How does computing  change the sampling?
change the sampling?
We mention in passing that Peter Shor’s algorithm basically shows that composing certain (non-polynomial) functions  into the quantum Fourier transform greatly improves the success of the sampling. This requires, however, a special kind of machine that, according to some of its principal conceivers, harnesses the power of multiple universes. There are books and even a movie about such machines, but none have been built yet and this is not a Dan Brown novel so we’ll stay classically rooted.
into the quantum Fourier transform greatly improves the success of the sampling. This requires, however, a special kind of machine that, according to some of its principal conceivers, harnesses the power of multiple universes. There are books and even a movie about such machines, but none have been built yet and this is not a Dan Brown novel so we’ll stay classically rooted.
Using Polynomial Roots
Two great facts about polynomials 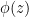 of degree
of degree  are:
are:
-
There are guaranteed to be at most roots.
-
If
 , then
, then  .
.
The second requires the coefficients of to be integers. Neither requires all the roots to be integers, but we will begin by assuming this is the case. Take  to be the set of integer roots of . Then define
to be the set of integer roots of . Then define
![\displaystyle S_p = \{u + cp \!\!\pmod{x} : u \in R \wedge c \in [q]\},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++S_p+%3D+%5C%7Bu+%2B+cp+%5C%21%5C%21%5Cpmod%7Bx%7D+%3A+u+%5Cin+R+%5Cwedge+c+%5Cin+%5Bq%5D%5C%7D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
where as usual ![{[q] = \{0,\dots,q-1\}}](https://s0.wp.com/latex.php?latex=%7B%5Bq%5D+%3D+%5C%7B0%2C%5Cdots%2Cq-1%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . The key point is that
. The key point is that

To prove this, suppose the random belongs to  but not to . Then
but not to . Then  for some
for some  , so
, so  , but
, but  since
since  . There is still the possibility that
. There is still the possibility that 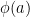 is a nonzero multiple of , which would give
is a nonzero multiple of , which would give  and deny success, but this entails
and deny success, but this entails  and so this is accounted by subtracting off .
and so this is accounted by subtracting off .
Our lower bound 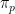 will be based on
will be based on  . There is one more important element of the analysis. We do not have to bound the running time for all , that is, all pairs
. There is one more important element of the analysis. We do not have to bound the running time for all , that is, all pairs 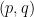 of primes. The security of factoring being hard is needed for almost all . Hence to challenge this, it suffices to show that is large in average case over . Thus we are estimating the distributional complexity of a randomized algorithm. These are two separate components of the analysis. We will show:
of primes. The security of factoring being hard is needed for almost all . Hence to challenge this, it suffices to show that is large in average case over . Thus we are estimating the distributional complexity of a randomized algorithm. These are two separate components of the analysis. We will show:
For many primes  belonging to a large set
belonging to a large set  of primes of length substantially below
of primes of length substantially below  , where
, where 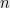 is the length of
is the length of  ,
,  is “large.”
is “large.”
We will quantify “large” at the end, and it will follow that since is substantially greater, is “tiny” in the needed sense. Now we are ready to estimate the key cardinality  .
.
The Lever
In the best case,  can be larger than
can be larger than  by a factor of . This happens if for every root
by a factor of . This happens if for every root  , the values
, the values  do not hit any other members of . When this happens, itself can be as large as . Then
do not hit any other members of . When this happens, itself can be as large as . Then

By a similar token, for any 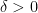 , if
, if  , then
, then  —or in general,
—or in general,

The factor of  is the lever by which to gain a higher likelihood of quick success. When will it be at our disposal? It depends on whether is “good” in the sense that
is the lever by which to gain a higher likelihood of quick success. When will it be at our disposal? It depends on whether is “good” in the sense that  and also on itself being large enough.
and also on itself being large enough.
For each root and define the “strand” ![{S_{u,p} = \{v_c : c \in [q]\}}](https://s0.wp.com/latex.php?latex=%7BS_%7Bu%2Cp%7D+%3D+%5C%7Bv_c+%3A+c+%5Cin+%5Bq%5D%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) where
where  There are always distinct values in any strand. If
There are always distinct values in any strand. If  then every strand has most
then every strand has most  as non-roots. There is still the possibility that
as non-roots. There is still the possibility that  —that is, such that
—that is, such that  —which would prevent a successful exit. This is where really comes in, attending to the upper bound .
—which would prevent a successful exit. This is where really comes in, attending to the upper bound .
 |
The Paris church of St. Sulpice and its crypt (source)
|
Hence what can make a prime “bad” is having a low number of strands. When  and
and  the strands
the strands  and
and  coincide—and this happens for any other
coincide—and this happens for any other 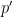 such that divides
such that divides  .
.
Here is where we hit the last important requirement on . Suppose  where
where  is the product of every prime
is the product of every prime  other than . Then
other than . Then  and
and  coincide for every prime . It doesn’t matter that
coincide for every prime . It doesn’t matter that  is astronomically bigger than or
is astronomically bigger than or  ; the strands still coincide within
; the strands still coincide within ![{[x]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and within
and within ![{[x']}](https://s0.wp.com/latex.php?latex=%7B%5Bx%27%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
Hence what we need to do is bound the roots by some value  that is greater than any
that is greater than any  we are likely to encounter. The is not too great: if we limit to of some same given length as that of , then
we are likely to encounter. The is not too great: if we limit to of some same given length as that of , then  so
so  . We need not impose the requirement
. We need not impose the requirement ![{R \subseteq [L]}](https://s0.wp.com/latex.php?latex=%7BR+%5Csubseteq+%5BL%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) but must replace above by
but must replace above by  where
where ![{R' = R \cap [L]}](https://s0.wp.com/latex.php?latex=%7BR%27+%3D+R+%5Ccap+%5BL%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . We can’t get in trouble from
. We can’t get in trouble from  such that divides
such that divides  and divides
and divides  since then divides already. This allows the key observation:
since then divides already. This allows the key observation:
For any distinct pair  , there are at most
, there are at most  primes such that divides
primes such that divides  .
.
Thus given 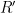 we have
we have  “slots” for primes . Every bad prime must occupy a certain number of these slots. Counting these involves the last main ingredient in Dick’s paper. We again try to view it a different way.
“slots” for primes . Every bad prime must occupy a certain number of these slots. Counting these involves the last main ingredient in Dick’s paper. We again try to view it a different way.
Counting Bad Primes
Given  , and replacing the original with , ultimately we want to call a prime bad if
, and replacing the original with , ultimately we want to call a prime bad if  , where . We will approach this by calling “bad” if there are
, where . We will approach this by calling “bad” if there are  strands.
strands.
For intuition, let’s suppose  ,
,  . If we take
. If we take  as the paper does, then we can make bad by inserting it into three slots: say
as the paper does, then we can make bad by inserting it into three slots: say  ,
,  , and
, and 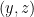 . We could instead insert a copy of into ,
. We could instead insert a copy of into , 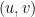 , and , which lumps
, and , which lumps  into one strand and leaves
into one strand and leaves 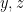 free to make two others. In the latter case, however, we also know by transitivity that divides
free to make two others. In the latter case, however, we also know by transitivity that divides  , , and
, , and  as well. Thus we have effectively used up
as well. Thus we have effectively used up 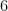 not
not  slots on . Now suppose
slots on . Now suppose  instead, so “bad” means getting down to
instead, so “bad” means getting down to  strands. Then we are forced to create at least one -clique and this means using more than
strands. Then we are forced to create at least one -clique and this means using more than  slots. Combinatorially the problem we are facing is:
slots. Combinatorially the problem we are facing is:
Cover  nodes by
nodes by  cliques while minimizing the total number
cliques while minimizing the total number 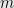 of edges.
of edges.
This problem has an easy answer: make all cliques as small as possible. Supposing  is an integer, this means making
is an integer, this means making  -many
-many  -cliques, which (ignoring the difference between
-cliques, which (ignoring the difference between  and
and  ) totals
) totals  edges. When is constant this is
edges. When is constant this is  , but shows possible ways to improve when is not constant. We conclude:
, but shows possible ways to improve when is not constant. We conclude:
Lemma 1 The number of bad primes is at most  .
.
We will constrain  by bounding the degree of . By this will also bound relative to so that the number of possible strands is small with respect to , which will lead to the desired bound on . Now we are able to conclude the analysis well enough to state a result.
by bounding the degree of . By this will also bound relative to so that the number of possible strands is small with respect to , which will lead to the desired bound on . Now we are able to conclude the analysis well enough to state a result.
The Result
Define ![{\mathsf{RAVGTIME}_{\gamma}[t(n)]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BRAVGTIME%7D_%7B%5Cgamma%7D%5Bt%28n%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) to mean problems solvable on a
to mean problems solvable on a  fraction of inputs by randomized algorithms with expected time
fraction of inputs by randomized algorithms with expected time 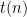 . Superscripting means having an oracle to compute from for free. If is such that the time to compute is and this is done once per trial, then a given
. Superscripting means having an oracle to compute from for free. If is such that the time to compute is and this is done once per trial, then a given ![{\mathsf{RAVGTIME}^{\phi}_{\gamma}[t(n)]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BRAVGTIME%7D%5E%7B%5Cphi%7D_%7B%5Cgamma%7D%5Bt%28n%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) algorithm can be re-classified into
algorithm can be re-classified into ![{\mathsf{RAVGTIME}_{\gamma}[t(n)^2]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BRAVGTIME%7D_%7B%5Cgamma%7D%5Bt%28n%29%5E2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) without the oracle notation.
without the oracle notation.
Theorem 2 Suppose ![{[\phi_n]}](https://s0.wp.com/latex.php?latex=%7B%5B%5Cphi_n%5D%7D&bg=e8e8e8&fg=000000&s=0&c=20201002) is a sequence of polynomials in
is a sequence of polynomials in ![{\mathbb{Z}[u]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BZ%7D%5Bu%5D%7D&bg=e8e8e8&fg=000000&s=0&c=20201002) of degrees
of degrees  having
having  integer roots in the interval
integer roots in the interval ![{[0,L_n]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2CL_n%5D%7D&bg=e8e8e8&fg=000000&s=0&c=20201002) , for all . Then for any fixed
, for all . Then for any fixed  , the problem of factoring -bit integers
, the problem of factoring -bit integers  with
with  belongs to
belongs to
![\displaystyle \mathsf{RAVGTIME}^{\phi_n}_{\Omega(1)}[O(n^2 \log L_n)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathsf%7BRAVGTIME%7D%5E%7B%5Cphi_n%7D_%7B%5COmega%281%29%7D%5BO%28n%5E2+%5Clog+L_n%29%5D+&bg=e8e8e8&fg=000000&s=0&c=20201002)
provided  and
and  .
.
Proof: We first note that the probability of a random ![{a \in [x]}](https://s0.wp.com/latex.php?latex=%7Ba+%5Cin+%5Bx%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) making is negligible. By the Chinese Remainder Theorem, as remarked above, gives independent draws
making is negligible. By the Chinese Remainder Theorem, as remarked above, gives independent draws ![{a_p \in [p]}](https://s0.wp.com/latex.php?latex=%7Ba_p+%5Cin+%5Bp%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and
and ![{a_q \in [q]}](https://s0.wp.com/latex.php?latex=%7Ba_q+%5Cin+%5Bq%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and whether depends only on
and whether depends only on  . This induces a polynomial
. This induces a polynomial  over the field
over the field  of degree (at most)
of degree (at most) 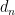 . So the probability of getting a root mod is at most
. So the probability of getting a root mod is at most
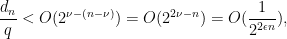
which is exponentially vanishing. Thus we may ignore in the rest of the analysis. The chance of a randomly sampled in a strand of length coinciding with another member of is likewise bounded by  and hence ignorable.
and hence ignorable.
The reason why the probability of  giving a root in the field
giving a root in the field  is not vanishing is that
is not vanishing is that  is close to . By
is close to . By  , we satisfy the constraint
, we satisfy the constraint

The condition  ensures that this is the actual asymptotic order of . Since we are limiting attention to primes of the same length as , the “
ensures that this is the actual asymptotic order of . Since we are limiting attention to primes of the same length as , the “ ” above can be to base . Hence has the right order to give that for some and constant fraction of primes of length
” above can be to base . Hence has the right order to give that for some and constant fraction of primes of length  , the success probability
, the success probability  of one trial over satisfies
of one trial over satisfies
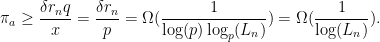
Hence the expected number of trials is  . The extra
. The extra 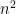 in the theorem statement is the time for each iteration, i.e., for arithmetic modulo and the Euclidean algorithm.
in the theorem statement is the time for each iteration, i.e., for arithmetic modulo and the Euclidean algorithm. 
It follows that if  is also computable modulo in
is also computable modulo in 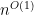 time, and presuming
time, and presuming  so that
so that  , then factoring products of primes whose lengths differ by just a hair is in randomized average-case polynomial time. Of course this depends on the availability of a suitable polynomial . But could be any polynomial—it needs no relation to factoring other than having plenty of distinct roots relative to its degree as itemized above. Hence there might be a lot of scope for such “dangerous” polynomials to exist.
, then factoring products of primes whose lengths differ by just a hair is in randomized average-case polynomial time. Of course this depends on the availability of a suitable polynomial . But could be any polynomial—it needs no relation to factoring other than having plenty of distinct roots relative to its degree as itemized above. Hence there might be a lot of scope for such “dangerous” polynomials to exist.
 |
Is there a supercomputer under the Palais Royale? (source)
|
Dick’s paper does give an example where a with specified properties cannot exist, but there is still a lot of play in the bounds above. This emboldens us also to ask exactly how big the “hair” needs to be. We do not actually need to send toward zero. If a constant fraction of the values get bounced by the event, then the expected time just goes up by the same constant factor.
Open Problems
We have tried to present Dick’s paper in an “open” manner that encourages variations of its underlying enigma. We have also optically improved the result by using  rather than
rather than 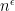 as in the paper. However, this may be implicit anyway since the paper’s proofs might not require “
as in the paper. However, this may be implicit anyway since the paper’s proofs might not require “ ” to be constant, so that by taking
” to be constant, so that by taking  one can make
one can make  for any desired factor
for any desired factor  . Is all of this correct?
. Is all of this correct?
If so, then possibly one can come even tighter to  for the length of . Then the question shifts to the possibilities of finding suitable polynomials . The paper “Few Product Gates But Many Zeroes,” by Bernd Borchert, Pierre McKenzie, and Klaus Reinhardt, goes into such issues. This paper investigates “gems”—that is, integer polynomials of degree
for the length of . Then the question shifts to the possibilities of finding suitable polynomials . The paper “Few Product Gates But Many Zeroes,” by Bernd Borchert, Pierre McKenzie, and Klaus Reinhardt, goes into such issues. This paper investigates “gems”—that is, integer polynomials of degree  having distinct integer roots and minimum possible circuit complexity for their degree—finding some for as high as 55 but notably leaving
having distinct integer roots and minimum possible circuit complexity for their degree—finding some for as high as 55 but notably leaving  open. Moreover, the role of a limitation on the magnitude of a constant fraction of a gem’s roots remains at issue, along with roots exceeding having many relatively small prime factors.
open. Moreover, the role of a limitation on the magnitude of a constant fraction of a gem’s roots remains at issue, along with roots exceeding having many relatively small prime factors.
Finally, we address the general case  with rational coefficients
with rational coefficients  (and
(and  ). If
). If  in lowest terms then
in lowest terms then  means (divided by
means (divided by  ) so the algorithm is the same. Suppose
) so the algorithm is the same. Suppose  is a rational root in lowest terms and does not divide , nor the denominator of any
is a rational root in lowest terms and does not divide , nor the denominator of any  Then we can take
Then we can take  such that
such that  for some
for some  and define
and define  . This gives
. This gives
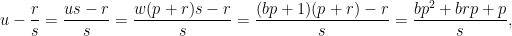
which we write as  . Then
. Then  . Because is a root, it follows that
. Because is a root, it follows that  is a sum of terms in which each numerator is a multiple of and each denominator is not. So
is a sum of terms in which each numerator is a multiple of and each denominator is not. So  in lowest terms where possibly
in lowest terms where possibly 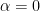 . Thus
. Thus  either yields or falls into one of two cases we already know how to count: is another root of or we have found a root mod . Since
either yields or falls into one of two cases we already know how to count: is another root of or we have found a root mod . Since  behaves the same as for all
behaves the same as for all ![{c \in [q]}](https://s0.wp.com/latex.php?latex=%7Bc+%5Cin+%5Bq%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , we can define integer “strands”
, we can define integer “strands”  as before. There remains the possibility that strands induced by two roots
as before. There remains the possibility that strands induced by two roots  and
and  coincide. Take the inverse
coincide. Take the inverse 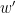 for
for 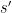 and resulting integer
and resulting integer  , then the strands coincide if
, then the strands coincide if  . This happens iff
. This happens iff  . Multiplying both sides by
. Multiplying both sides by  gives
gives

so it follows that divides the numerator of  in lowest terms. Thus we again have “slots” for each distinct pair
in lowest terms. Thus we again have “slots” for each distinct pair  of rational roots and each possible prime divisor of the numerator of their difference. Essentially the same counting argument shows that a “bad” must fill
of rational roots and each possible prime divisor of the numerator of their difference. Essentially the same counting argument shows that a “bad” must fill  of such slots. The other ways can be bad include dividing the denominator of a root or the denominator of a coefficient —although neither way is mentioned in the paper it seems the choices for and in the above theorem leave just enough headroom. Then we just need to be a bound on all numerators and denominators involved in the bad cases, arguing as before. Last, it seems as above that only a subset of the roots with
of such slots. The other ways can be bad include dividing the denominator of a root or the denominator of a coefficient —although neither way is mentioned in the paper it seems the choices for and in the above theorem leave just enough headroom. Then we just need to be a bound on all numerators and denominators involved in the bad cases, arguing as before. Last, it seems as above that only a subset of the roots with  constant (or at least non-negligible) is needed to obey this bound. Assuming this sketch of Dick’s full argument is airtight and works for our improved result, we leave its possible further ramifications over the integer case as a further open problem.
constant (or at least non-negligible) is needed to obey this bound. Assuming this sketch of Dick’s full argument is airtight and works for our improved result, we leave its possible further ramifications over the integer case as a further open problem.
Update 7/10: >
I’ve made a web folder of photos from Dick’s wedding and honeymoon.
[linked wedding announcement, clarified nature of Shor’s phi, added more about gems, linked photos, fixed n/2 – eps to n/2 – eps*n in theorem statement]
Related


:star: congratulations! paris/ louvre huh? pretty suave! guess there is hope/ inspiration for hardcore geeks/ hackers/ mathematicians/ scientists everywhere in the luv department now. & dont forget the Musee de Orsay too ofc.
<3
oh re the technical content: it seems like the theoretical grounding of RSA deserves a lot more analysis and that an entire book could be written on the subj. there is some, maybe lots of mystery remaining. its basically a special case of turings halting problem once again… if there were a top 10 algorithms for CS, it seems like RSA would be in top 5 or maybe even top 3…
Congratulations Dick and Kathryn! Best wishes to both of you!
are you saying factoring is in P?
No. The original big obstacle is the complexity of the sequence of polynomials φ_n in terms of n. This is related to the so-called “tau” conjecture of Lenore Blum, Michael Shub, and Steve Smale. The post clarifies L as a second obstacle even in the integer-roots case where all arithmetic can be done mod x. However, the original paper’s limitation to p being much smaller than q may be largely removable, and the timing also improved a bit at least in the terms stated—Dick’s paper defines everything to be quasi-polynomial from the get-go. But both he and I take very seriously the position that factoring may be in P.
Two queries:
1) If straight line complexity of factorial (n!) is small does that mean there exists at least one polynomial of form (x-a1)…(x-am)g(x) at every m such that straight line complexity of this polynomial is O((log m)^c)?
2) If integer factorization is easy then does that mean there exists at least one polynomial of form (x-a1)…(x-am)g(x) at every m such that straight line complexity of this polynomial is O((log m)^c)?
What is lipton blog’s stance on P=BPP?
Congratulations! I was wondering, what level of mathematics is recommended for understanding these posts? I am going into AP Calc next year, and I have trouble understanding some of the jumps you make and notation you use. Are there any good write ups on the mathematical concepts used most often in TCS?
Thank You
Julian, thanks for the interesting comment. When we get technical, we center on promoting undergraduates and early-year graduate students to take up computing theory. This present post is also at research level—it’s in the gray zone where it’s not really an original paper (though it may become the “journal version” of one) but is pointing out some things that may be new. The part after “Open Problems” is a technical appendix that I wanted to include for peers but keep out of the main narrative. I for one may have special interest in adjusting my writing to high-school level.
As for a good source on concepts, this is part of the argument connected with the previous post on CS theory education. The answer is a background in discrete mathematics, automata/formal-languages, and elementary linear algebra, which typically range 1xx–3xx in college. In particular there is a move to fuse the first and second at maybe 2xx level as opposed to having separate textbooks like Rosen’s and Sipser’s which I could point you to now. But if I recall right, Hungary in the late 1950s or early 1960s started a program to introduce this material in high school. Dick and I started discussing this before this post last December.
Congratulations to Dick and Kathryn!
Dear Gil, I understood the follow the perturbed leader principle, which had been bothering me for a while what it really means, in realizing that Hedge is a log sum exp version of it. The true meaning of why being greedy doesn’t make sense in computational complexity theory implies that I still don’t get why I did not immediately get why non stochastic means probabilistic. I think it is weird that learning theory should do some soul searching on their definitions and how they apply to gaming adversaries. Rob Schapire’s famous one line proof that Hedge cannot compete against an arbitrary opponent is wrong I think. As Richard points out in his book it makes little sense that one bit impossibility proofs (cf. P is not equal to NP) are seriously problematic only to thank the people who commented that his question makes sense. Best, Yannis (to contact me should you wish please refer to my contact details in this blog as a one time pad)
Τι κάνουν τα πουλιά όταν πεθαίνουν τραγουδώντας; Βγαζουν αυτό το ωραίο άρθρο: http://www.mixanitouxronou.gr/ta-poulia-pethenoun-tragoudontas-o-pater-ralf-itan-gkei-ke-i-megki-eroteftike-ton-antra-pou-misise-sto-sirial/ που ακυρώνει τις μαλακίες που έφαγε μια ωραία γερμανίδα στο YouTube.
I had asked Jen that I cannot find a good relationship between optimization and security in walking on Nassau Street toward the Fitz-water gate. Very good water though. The gate is actually FitzRandolph in Princetoniana font.
Look up and look up Straffin’s book because liberal art colleges are not like Princeton. Your’s truly from the love seat in my western movie.
May I kindly ask when was this house built and for what reason?
The microeconomics bible explains the story differently, first you do optimization for one person against the economy and then the economy asks his wife to pray to money. Did she know about it and what if he did not have a wife. Will he ever?
Apologize to the FitzRandolph Gate.
Τιποτα αλλο εχεις να πεις, ή με αυτο τα ειπες ολα και εξαντληθηκες?
(translation)
Is there anything else you wish to say, or you actualy exhausted all that was to be said?
Do you think we are stupid?
Hi: I was reading a newspaper article on Georgia being up to the effort of germinating wellsprings only to be disappointed by the jest of the Athens decorum having had declined in with the idea that geopolitics should be based on the principle that academic institutions can only flourish under principles of treason unless trails of history are laid bare. In other words, Georgia Tech sounds weird however Georgia** Tech sounds more honest. Maybe the wildcards should correspond to the order in which Georgia was instituted as a state of the United States of America to pay tribute to the fact that γεωργία means something else in Greek which only makes sense as an echo from a slightly different culture if and only if this difference is, in my humble opinion, properly clarified. Maybe the difference however is not so slight but I would like to know about it.
Yannis whatever
Congratulations on your wedding!
But Paris under the water was a great sight too…
http://www.cbc.ca/news/multimedia/this-is-what-it-looks-like-in-flooded-paris-1.3614718
“The extra ${n^2}$ in the theorem statement is the time for each iteration, i.e., for arithmetic modulo {x} and the Euclidean algorithm.”
Can the ${n^2}$ be replaced by something quasilinear, i.e., ${n (\log n)^2 \log \log n}$, by using a fast Euclidean algorithm?
(Also, has the degree of the polynomial been included in the iteration analysis? I would think there should be a $\log d$ term here when evaluating the polynomial, but perhaps I missed something.)
Thanks, yes, a faster Euclidean algorithm would cut the time. I left as a hedge the possibility of using modular exponentiation in O(n^2) time. The polynomial is treated as an oracle with evaluations “for free”, thus skirting the degree being exponential in n in the theorem statement. The straight-line programs used in Dick’s paper can reach high degree quickly by iterated squaring (unlike formulas), whence your log(d) term would enter, but the polynomial may also have exponentially-many terms. The tau-conjecture is about the complexity of polynomials with many distinct roots; this and the magnitude L of the roots are two defenses for factoring from the attack in the paper—do you think perhaps the “p << q" condition in the paper no longer is?
Thanks, I had forgotten the oracle would sidestep the polynomial evaluation.
It seems like this tightens p’s size significantly, so yes, my intuition says it’s not the issue. But the tau-conjecture is pretty significant.
The “gem” paper is fascinating. I’d seen a limited case of it in Crandall-Pomerance (the normalized gems), but this gives much more details.
Thanks as always for the great blog!
A hearty congratulations from your first student
I may have stumbled on a factoring method that would confirm what Professors Lipton and Regan have been promoting on this blog, that factoring is in P. I would like to have Professor Lipton’s permission to post it as a comment. I can think of no better place to post it. Please notify me by email if I am granted permission. Thanks.