Making Public Information Secret
A way to recover and enforce privacy

|
| McNealy bio source |
Scott McNealy, when he was the CEO of Sun Microsystems, famously said nearly 15 years ago, “You have zero privacy anyway. Get over it.”
Today I want to talk about how to enforce privacy by changing what we mean by “privacy.”
We seem to see an unending series of breaks into databases. There is of course a huge amount of theory literature and methods for protecting privacy. Yet people are still broken into and lose their information. We wish to explore whether this can be fixed. We believe the key to the answer is to change the question:
Can we protect data that has been illegally obtained?
This sounds hopeless—how can we make data that has been broken into secure? The answer is that we need to look deeper into what it means to steal private data.
After The Horse Leaves The Barn
The expression “the horse has left the barn” means:
Closing/shutting the stable door after the horse has bolted, or trying to stop something bad happening when it has already happened and the situation cannot be changed.
Indeed, our source gives as its main example: “Improving security after a major theft would seem to be a bit like closing the stable door after the horse has bolted.”
 |
| Photo by artist John Lund via Blend Images, all rights reserved. |
This strikes us as the nub of privacy. Once information is released on the Internet, whether by accident or by a break-in, there seems to be little that one can do. However, we believe that there may be hope to protect the information anyway. Somehow we believe we can shut the barn door after the horse has left, and get the horse back.
Suppose that some company makes a series of decisions. Can we detect if those decisions depend on information that they should not be using. Let’s call this Post-Privacy Detection.
Post-Privacy Detection
Consider a database that stores values 



Now say a decider is an entity 

The point here is that we can detect if 

Definition 1 Let a database contain values of the form
, and let
be a Boolean function. Say that the
part is effectively private for the decision
provided there is another function
so that
where
. A decider
respects
![\displaystyle \mathsf{Prob}[f(v,a)=g(v)] \ge 1-\epsilon,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathsf%7BProb%7D%5Bf%28v%2Ca%29%3Dg%28v%29%5D+%5Cge+1-%5Cepsilon%2C+&bg=e8e8e8&fg=000000&s=0&c=20201002)
We can prove a simple lemma showing that this definition implies that
Lemma 2 If the database is secure for
such that
.
Proof: Suppose for contradiction such an 


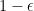



Pulling in the Long Reins
To be socially effective, our detection concept should exert influence on deciders to behave in a manner that overtly does not depend on the unauthorized information. This applies to repeatable decisions whose results can be sampled. The sampling would use protocols that effect transparency while likewise protecting the data.
Thus our theoretical notion would require social suasion for its effectiveness. This includes requiring deciders to provide infrastructure by which their decisions can be securely sampled. It might not require them to publish their 

What we can say now, however, is that there do exist ways we can rein in the bad effects of lost privacy. The horses may have bolted, but we can still exert some long-range control over the herd.
Open Problems
Is this idea effective? What things like it have been proposed?


Announcement
A thorough treatment of the settlement of P vs. NP is now put in book form.
Of the various questions pertaining to the conjecture that the book answers is the following from GLL:
People should soon see a follow-up with a bit more details (unless things go suddenly berserk like last time).
— Roielle Hugh
The Longest Second, now made available from both Amazon and NOOK, is a condensed version of the saga.
Even though there are very elaborate proofs for P vs. NP both formal and ‘relaxed’ in the book, the true purpose is not for such superfluity. We are to precisely answer the more fundamental questions:
Maybe more dramatically, with our resolution, is the following:
Despite the mild philosophical tint, the book has a quite practical side. It is to suggest to people, who want to prove, a way to produce a valid one, presenting a vivid and precise picture of what a proof will look like in two short paragraphs (of about 111 words) in the chapter “NP = P“. Implicitly, the book will also offer means to recognize insufficiency so that one who had an attempt can know in an exact manner whether it is valid or invalid. For those who has or will have such an attempt, a sense about the validity may also be gained (possibly before a claim is made).
The book has a specific chapter, Vetting Claims, to provide the guideline, the necessary and sufficient conditions for a valid proof.
It may or may not be a simple thing to settle, but won’t be as simple a task as prior believed with three bricks. The world evolved since 1998. It is already out of the scope of a single ASCII.
The book starts, as can be seen via a preview, with the (slightly metaphorical) re-capture of the moment in which the solution of the Trio was announced to the world.
— Roielle Hugh
NOTE:
Due to limitations of electronic delivery, the reader may have to put up with the less ideal formatting. Besides, math-related material is limited to a minimum and largely to text form, as shown in the following excerpt (of part of an informal discussion) from the book:
Since $$C_{n}^{*}$$ is large (with regard to $$F_{n}$$) and $$C_{n}^{*} \subseteq C_{n} \subseteq F_{n}$$, $$C_{n}$$ is primarily $$C_{n}^{*}$$, which means $$C_{n}$$ is primarily easy/hard, contradicting $$C_{n}$$ is hard/easy. ... On the other hand, if we have an easy predicate $$p$$ for $$f_{n} \in C_{n}$$ with $$C_{n}$$ hard, ...will be in the book in text form as:
Since $$C_{n}^{*}$$ is large (with regard to $$F_{n}$$) and $$C_{n}^{*}$$ is subset of $$C_{n}$$ which is subset of $$F_{n}$$, $$C_{n}$$ is primarily $$C_{n}^{*}$$, which means $$C_{n}$$ is primarily easy/hard, contradicting $$C_{n}$$ is hard/easy. ... On the other hand, if we have an easy predicate $$p$$ for "$$f_{n}$$ being a member of $$C_{n}$$ that is hard", ...Blockquote may work for the note above.
NOTE:
Due to limitations of electronic delivery, the reader will have to put up with the less ideal formatting. Besides, math-related material is limited to a minimum and largely to text form, as shown in the following excerpt (of part of an informal discussion) from the book:
will be in the book in text form as:
Dear Professors,
A major complexity class is NL. NL is the class of languages that are decidable on a nondeterministic logspace machine. A logspace machine is a Turing machine with a read-only input tape, a write-only output tape, and a read/write work tapes. The work tapes may contain at most O(log n) symbols. In addition, Sanjeev Arora described in his book “Computational complexity: A modern approach” the certificate-based definition for NL.
The certificate-based definition of NL assumes that a deterministic logspace machine verifies the elements in a NL language using another separated read-only tape for the certificate. On each step of the machine the machine’s head on that tape can either stay in place or move to the right. In particular, it cannot reread any bit to the left of where the head currently is. For that reason this kind of special tape is called “read once”.
CLIQUE is a well-known NP-complete problem. We show that a certificate u which represents a clique V’ of size k on a graph G can be verified by a deterministic logspace machine M using an additional special read-once input tape, and thereby CLIQUE will be in NL as a direct consequence of this previous definition. If any single NP-complete problem can be solved in polynomial time, then every NP problem has a polynomial time algorithm. However, every problem in NL is in P too. Consequently, we can conclude that P = NP.
You can understand more this idea and debug my verifier algorithm in
https://hal.archives-ouvertes.fr/hal-01316353/document
Any suggestion will be welcome,
Thanks in advance,
Frank.
Did it ever occur to you that begging people to read your P=NP proofs via comments on blog posts might be strong evidence against the fact you have solved the problem?
I mean surely if you are smart enough to have solved the problem it has occurred to you that blog comments to that effect wouldn’t be particularly believable.
—
I am going to do everything I can to convince all the other mathematicians I know to announce their major results through crackpot blog postings just for the humor value however.
Everyone does the best he can do…
This sounds like a very good idea if you want to regulate companies that (arguably illegally) buy and sell private user data. Unfortunately this technique doesn’t stop criminals who illegally buy and sell account information resulting from these leaks. Social pressure doesn’t influence them.
Off course it can stop criminals. If they cannot re-introduce this information (or a derivative of it) into the main stream, then it is useless.
That’s my point: criminals don’t work in the main stream. The technique in this post only applies to institutions that are subject to oversight, which (uncaught) criminals are not by definition. If someone hacks into your bank, steals your loan information, sells it to Nigerians who later try to scam you using that information, this scheme will not protect you. The horse is still out of the barn.
Ignoring the detailed mathematics, in terms of information leaked there’s “access data” (bank account numbers, SSNs, etc) and there’s more attribute like-data (eg, has recently lost a lot of weight, buys a lot of alcohol, has the spending pattern of an adulterer, etc). In privacy terms the attribute data is more significant in decision making.
The thing is that unlike access data which you can only know if you see it stored, roughly the same attribute data can be obtained from many sources (eg, for alcohol abuse from AA attendance, from empty alcohol cans in the garbage, from purchase records, from DUI citations, etc). So I think you face the problem of needing to show to a high-probability that the particular leaked version of the attribute data was used in a decision and not the same sort of datum from a different source.
This is not very related, but reading your post, I was thinking, why don’t they store dummy information in databases? For example, if someone stores one million records, they could add another million (or trillion!) phony entries. Only real entries could be logged into, because no one would know the password for the phony ones. If sometimes statistics needs to be done, then of course all phony entries should be generated from the real ones with some algorithm. If a real record is deleted, then even that could be balanced by generating more phony records. Even the number of the real records could be stored, if needed.
If you are a good person with nothing to hide, then “privacy” should not be an “issue”. End of story. Honest people are not afraid to post on the internet using their real identities.
You probably did not get it completely right.
A good person has nothing to hide and that is the exact reason for “privacy”. That is actually what “privacy” means.
Make a distinction between an identity (a name for the purpose) not used for deceit and information that has no purpose other than ‘intended’ use.
Not something quite clear cut, perhaps.
Am I a bad person because I have a credit card?
Fake named phoney’s are the real problem with the internet.
Interesting, but it’s just not what people care about when keeping private information private.
The information people really care about getting out is Information that is personally or professionally embarrassing. Things like membership in ashley madison, sexual orientation, activities at odds with one’s professional colleagues (or can be used against us legally like weed smoking)
In all these cases we KNOW (or at least suspect) that this information has been used when the bad effects happen.
The reason we worry about this information getting out isn’t that large corporations might secretly use it but we fear that some people will feel PERFECTLY JUSTIFIED IN USING THAT INFORMATION AGAINST US.
—
I suspect that if we had the choice to entirely abandon the kind of big data privacy your scheme protects (statistical decisions by banks etc..) while retaining the personal privacy I mention above we wouldn’t hesitate to do so. After all these statistical decisions lack any personal barb and promise to reward the virtuous (and we all think we will benefit from that the same way almost everyone believes they are an above average driver).
See an imaginary dialogue about the P vs NP problem: http://www.ptep-online.com/index_files/2016/PP-46-18.PDF
Craig
Sent from my iPhone
I’m sorry, I wasn’t trying to post it to this forum, since it is off topic. That was from a private email sent to Professors Lipton and Regan from my iphone.
You are putting privacy and copyright on the same bucket, like a huge DRM system; which isn’t necessarily bad.
Hey,
This year’s Lagos Women Run is in two categories, the Open category for runners who are 18 years old to age 44 years, and the Veteran category for runners who are 45 yrs and about.
The winner in the Open category will get N500, 000, while the Veteran champion will get N200,000 …….
Find out more here- http://necinsurance.co.zw/component/k2/itemlist/user/2055.html