Casinos beware—the primes are not random
Robert Lemke Oliver and Kannan Soundararajan have observed that the primes fail some simple tests of randomness in senses that are both concrete and theoretical.
Today we discuss this wonderful work and what it means both for properties of the primes and for asymptotics.
At the heart is the question,
How closely does the sequence of primes emulate a truly random sequence?
Lemke Oliver and Soundararajan use a genre of simple tests of randomness—ones that we might have thought would be true. The simplest one is:
Let  and
and  be consecutive primes in order. If is congruent to
be consecutive primes in order. If is congruent to  mod
mod 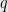 , then is less likely to also be congruent to mod .
, then is less likely to also be congruent to mod .
They note that among the first billion primes the expected frequency is much less than 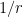 , where
, where  is the number of positive integers
is the number of positive integers  that are relatively prime to
that are relatively prime to  . They argue based on a famous
. They argue based on a famous  -tuple conjecture of Godfrey Hardy and John Littlewood holds that this bias persists through the whole sequence of primes. Yet it follows that the proportion of cases where the next prime has the same congruence mod is
-tuple conjecture of Godfrey Hardy and John Littlewood holds that this bias persists through the whole sequence of primes. Yet it follows that the proportion of cases where the next prime has the same congruence mod is  . This is not a contradiction.
. This is not a contradiction.
Primes Are Not Random
From first principles the primes are completely not random: they are determined by a tiny rule. In this respect they are like the digits of  . Unlike the primes also flunk an immediate frequency test: only one even number is prime. We can make a fairer comparison by taking the primes mod and expanding in base . Call these infinite base-
. Unlike the primes also flunk an immediate frequency test: only one even number is prime. We can make a fairer comparison by taking the primes mod and expanding in base . Call these infinite base- sequences
sequences  and
and  , respectively. Jacques Hadamard and Charles-Jean de la Vallée Poussin proved that each “digit” of appears with frequency asymptotic to , but this has not been proved for any even with
, respectively. Jacques Hadamard and Charles-Jean de la Vallée Poussin proved that each “digit” of appears with frequency asymptotic to , but this has not been proved for any even with  . Yet and its analogues for
. Yet and its analogues for  and
and  and other famous irrational constants are commonly expected to be normal in every base . Normal means that every sequence of digits occurs with frequency asymptotic to
and other famous irrational constants are commonly expected to be normal in every base . Normal means that every sequence of digits occurs with frequency asymptotic to  ; the case
; the case  is called “simply normal.”
is called “simply normal.”
Indeed, the normality of and the other constants follows from some reasonable hypotheses about digital dynamical systems. So what about ? One difference is that whereas the normality of a number in base is equivalent to its being simply normal in base  for all , this doesn’t carry over to the primes mod even when you find
for all , this doesn’t carry over to the primes mod even when you find 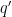 such that
such that  . Still, it is significant that the primes meet the case for all . So what about
. Still, it is significant that the primes meet the case for all . So what about 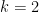 ? This is where Lemke Oliver and Soundararajan weighed in with a universally regarded surprise.
? This is where Lemke Oliver and Soundararajan weighed in with a universally regarded surprise.
The Bias
They posted their paper two weeks ago, and it has been covered by Scientific American, by Nature, by the New Scientist, and by Quanta Magazine. Terry Tao also posted about it, and he explicates the gist in a wonderful way.
Also wonderful are the diagrams in this 2002 paper by Chung-Ming Ko, in which much of the concrete numerical evidence was observed. A 2011 paper by Avner Ash, Laura Beltis, Robert Gross, and Warren Sinnott, observed the numerics and went further to try to explain them by heuristic formulas. However, one needs Lemke Oliver and Soundararajan (and a nod to Tao’s exposition) to plumb the relations among asymptotics, heuristics, and theory.
The easiest case for us to visualize is  ,
,  . All primes other than 2—which is a very odd prime—must have a last digit of 1, 3, 7, or 9. The first and last of these are quadratic residues mod 10, and a long-known bias, which was first noted by Pafnuty Chebychev in the case
. All primes other than 2—which is a very odd prime—must have a last digit of 1, 3, 7, or 9. The first and last of these are quadratic residues mod 10, and a long-known bias, which was first noted by Pafnuty Chebychev in the case 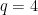 , , explains why they usually occur less often in concrete tables up to some number
, , explains why they usually occur less often in concrete tables up to some number  than 3 and 7 as last digits. For the first
than 3 and 7 as last digits. For the first  primes the counts are:
primes the counts are:

Here only primes congruent to 1 mod 10 are lagging overall. There are values of  for which 1 has the highest number, but—as has been proved assuming the Generalized Riemann Hypothesis—they are in certain senses sparse, so that this picture is typical. This bias varies as
for which 1 has the highest number, but—as has been proved assuming the Generalized Riemann Hypothesis—they are in certain senses sparse, so that this picture is typical. This bias varies as  (recall that in general
(recall that in general  by the Prime Number Theorem), so it is pretty mild. The bias found by Lemke Oliver and Soundararajan for
by the Prime Number Theorem), so it is pretty mild. The bias found by Lemke Oliver and Soundararajan for  , however, blows it away. Let
, however, blows it away. Let 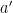 stand for the cyclic successor of
stand for the cyclic successor of  in
in  , so for example
, so for example  groups the pairs
groups the pairs  :
:

Most of the bias is against the next prime having the same last digit as the previous one. It is gigantic. How can this be?
Not the Usual “Laws”
One can try to view the primes as the outcome of a random process. Say we are up in the range from  up to , maybe up to
up to , maybe up to 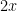 . The density of primes there is about
. The density of primes there is about  , so let’s picture a series of random trials each with success probability
, so let’s picture a series of random trials each with success probability  . If was the congruence mod of our last success, then the point is that ,
. If was the congruence mod of our last success, then the point is that , 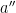 , and
, and  (etc.) get the next cracks at being prime before the turn of comes around again. As some commenters to the above news items have remarked, this could be analogous to Benford’s Law in base , which we once covered in regard to baseball.
(etc.) get the next cracks at being prime before the turn of comes around again. As some commenters to the above news items have remarked, this could be analogous to Benford’s Law in base , which we once covered in regard to baseball.
Our  counts above make this plausible, but the idea falls apart when looking at individual pairs of digits. For instance, conditioned on a prime
counts above make this plausible, but the idea falls apart when looking at individual pairs of digits. For instance, conditioned on a prime  being 3 mod 10, the next prime
being 3 mod 10, the next prime 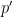 is more often congruent to 9 than 7, by a count of
is more often congruent to 9 than 7, by a count of  to
to  . Lemke Oliver and Soundararajan (LOS) further note that the above bias should be no greater than the probability of
. Lemke Oliver and Soundararajan (LOS) further note that the above bias should be no greater than the probability of 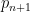 being less than
being less than  —because once you get to
—because once you get to  which is
which is  , the case
, the case  has first crack in every coming cycle. But it is known that this probability is asymptotically less than the bias they identify in their argument. In a comment to his own post, Tao calculates for that the “next-crack” argument would predict 20% for , not the observed 18%.
has first crack in every coming cycle. But it is known that this probability is asymptotically less than the bias they identify in their argument. In a comment to his own post, Tao calculates for that the “next-crack” argument would predict 20% for , not the observed 18%.
The authors say they were motivated by a second principle they heard in a lecture by Tadashi Tokieda: Suppose Alice rolls a 4-sided die with faces marked trying to roll a  two consecutive times, while Bob rolls the same die trying to get a followed by a
two consecutive times, while Bob rolls the same die trying to get a followed by a  . Occurrences of
. Occurrences of 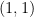 and
and  are equally likely, yet Alice will need appreciably more rolls on average to meet her goal than Bob. The reason is that when Alice rolls a but then fails by getting ,
are equally likely, yet Alice will need appreciably more rolls on average to meet her goal than Bob. The reason is that when Alice rolls a but then fails by getting , 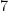 , or
, or 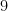 on her next roll, she has to roll some more to get a again, whereas Bob on rolling can fail by getting another , which sets him up immediately for another try. Stated in this form, the issue resembles the exposé of a simple bias of studies of the “hot hand” fallacy, which we discussed last October.
on her next roll, she has to roll some more to get a again, whereas Bob on rolling can fail by getting another , which sets him up immediately for another try. Stated in this form, the issue resembles the exposé of a simple bias of studies of the “hot hand” fallacy, which we discussed last October.
However, this argument goes away when we change Alice’s goal to rolling any and Bob’s to rolling any 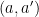 . Now both have a 1-in-4 chance of winning on any roll after the first, so there should be no bias. Another fix to Alice and Bob, analogous to our suggestion in the “hot-hand” case, makes no difference for LOS: make their goals be to roll and beginning with an odd-numbered roll. Then their expected trials to first success is the same. In the prime case this means considering
. Now both have a 1-in-4 chance of winning on any roll after the first, so there should be no bias. Another fix to Alice and Bob, analogous to our suggestion in the “hot-hand” case, makes no difference for LOS: make their goals be to roll and beginning with an odd-numbered roll. Then their expected trials to first success is the same. In the prime case this means considering  where is odd (
where is odd (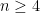 to rule out the primes
to rule out the primes  ). Does the bias in such pairs persist? Yes, because we could equally well start with even, and the overall bias is the average of these two cases.
). Does the bias in such pairs persist? Yes, because we could equally well start with even, and the overall bias is the average of these two cases.
However imperfect, these analogies directed them to suspect and consider a deeper connection to the theory of gaps between primes.
The Argument of the Paper
At the heart is a conjecture by Godfrey Hardy and John Littlewood that we discussed last August. LOS started with a strong form of it that expedited their mod- twist. Given any prime and any finite set  of integers including
of integers including  , let
, let  denote the proportion of
denote the proportion of ![{a \in [0 \dots p-1]}](https://s0.wp.com/latex.php?latex=%7Ba+%5Cin+%5B0+%5Cdots+p-1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) that are not congruent to any element of modulo . Then define the product series
that are not congruent to any element of modulo . Then define the product series

If hits every congruence class modulo some then  , so in particular cannot include any odd numbers. If
, so in particular cannot include any odd numbers. If  then
then  so
so  . Finally let
. Finally let  denote the number of
denote the number of  such that for all
such that for all 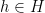 ,
,  is prime. The so-called “First” Hardy-Littlewood conjecture then states that for any and
is prime. The so-called “First” Hardy-Littlewood conjecture then states that for any and  ,
,

When , the integrand is the offset log-integral function (the paper uses  for this) and this becomes a well-known equivalent form of the Riemann Hypothesis (RH)—and still equivalent if the error is sharpened to
for this) and this becomes a well-known equivalent form of the Riemann Hypothesis (RH)—and still equivalent if the error is sharpened to  . When
. When  this subsumes the Twin Primes conjecture. Thus Hardy and Littlewood presented their conjecture as a natural strong extension of RH.
this subsumes the Twin Primes conjecture. Thus Hardy and Littlewood presented their conjecture as a natural strong extension of RH.
The twist by LOS starts by excluding the finitely many primes that divide from the product, calling the resulting function  . They need to relate this to tuples a of congruences mod . They break a down according to how equal congruences mod are situated; these become like diagonal entries of a matrix and there are symmetries around this “diagonal.” The lone hard-and-fast theorem in their paper, called Proposition 2.1, shows that their formulas faithfully follow the original Hardy-Littlewood intuition about the behavior of the series. Eventually they boil all this down into functions
. They need to relate this to tuples a of congruences mod . They break a down according to how equal congruences mod are situated; these become like diagonal entries of a matrix and there are symmetries around this “diagonal.” The lone hard-and-fast theorem in their paper, called Proposition 2.1, shows that their formulas faithfully follow the original Hardy-Littlewood intuition about the behavior of the series. Eventually they boil all this down into functions  and
and  which become appropriate constants when and a are fixed.
which become appropriate constants when and a are fixed.
In terms of and the length of a, and recalling , we can call  the “naive” estimate of the number
the “naive” estimate of the number  of primes
of primes 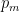 among the first primes such that
among the first primes such that  for each
for each  ,
,  . In terms of , the natural estimate is
. In terms of , the natural estimate is  . The new conjecture by LOS shows how far this needs to be adjusted—and the overhead is far bigger than the gentle in the analogous factored form of RH or Hardy-Littlewood:
. The new conjecture by LOS shows how far this needs to be adjusted—and the overhead is far bigger than the gentle in the analogous factored form of RH or Hardy-Littlewood:
Conjecture:

As often in number theory, the “ ” is meant in the sense of “
” is meant in the sense of “ for some error term
for some error term  .” The paper closes with detailed numerical evidence supporting this expression. As usual we say to consult the paper for further details, but we have some final remarks about the two or three big terms in this formula.
.” The paper closes with detailed numerical evidence supporting this expression. As usual we say to consult the paper for further details, but we have some final remarks about the two or three big terms in this formula.
About the Asymptotics
The three terms still all go to as  . Let’s go back to our original focus on the frequency. Call it
. Let’s go back to our original focus on the frequency. Call it  for the primes below and just
for the primes below and just 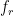 in the limit. from being asymptotic to . Then it is perfectly mathematically consistent to prove theorems—maybe contingent on a generalized RH and/or Hardy-Littlewood and/or related principles—with diametrically opposite messages:
in the limit. from being asymptotic to . Then it is perfectly mathematically consistent to prove theorems—maybe contingent on a generalized RH and/or Hardy-Littlewood and/or related principles—with diametrically opposite messages:
-
(a)
 —so in the long run the primes behave randomly in this case after all.
—so in the long run the primes behave randomly in this case after all.
-
(b) is always vastly less than
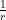 , so the primes are always substantially non-random.
, so the primes are always substantially non-random.
The paper indeed conjectures “always” in a related case, so we might not even have the kind of sporadic remissions seen in the Chebychev bias. We can’t imagine any more opposite than this.
Now number theory is used to emphasis on lower-order terms—as we noted above, RH is equivalent to lower-order behavior of 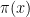 . But it strikes us that complexity theory has rarely been so subtle. We prove theorems of type (a) all the time. Are we perhaps missing important ways to sharpen and qualify our asymptotic estimates?
. But it strikes us that complexity theory has rarely been so subtle. We prove theorems of type (a) all the time. Are we perhaps missing important ways to sharpen and qualify our asymptotic estimates?
Open Problems
How does this discovery align with other observations of unexpected structure in the primes, including ramifications of Stanislaw Ulam’s spiral?
Tao makes a point of noting—including in his followup comments to his own piece—that while the  term is already sizable and responsible for much of the deviation tabulated for
term is already sizable and responsible for much of the deviation tabulated for  , the asymptotically bigger
, the asymptotically bigger  term is novel and potentially more important theoretically. We look forward to further developments. Can readers say ways in which asymptotics in complexity theory are showing the same maturity?
term is novel and potentially more important theoretically. We look forward to further developments. Can readers say ways in which asymptotics in complexity theory are showing the same maturity?
Related



Let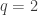 … oh, never mind …
… oh, never mind …
:star: 💡 😎 <3 ❗ 😀 this new apparently fundamental prime pattern and the big media attn is super exciting to me and so way cool! the greats of the field such as hardy or ramanujan seemed to pursue similar patterns ages ago (which reminds me, theres a new ramanujan movie out at the end of april, hope you cover it, plan to blog on it myself.) note that the pattern was found with empirical studies which are an increasingly big deal and maybe even a very slow/ long paradigm shift in (T)CS in action. one might argue it ties in heavily with statistical/ “big data” approaches also.
also, random walks and connections to fractals is some kind of key area of research for the future, it unites several fields such as CS, math, physics; it could be some kind of rosetta stone.
💡 ok half inspired by you, just wrote all this up myyself:
number theory news/ highlights/ headlines/ topnotch links: prime bias discovery, Diffie-Hellman Turing prize, Zhang-Tao twin primes, Wiles Abel prize, Riemann / tmachine blog
lots of complexity theory angles. at the end, am proposing an open problem of proving Euclids thm for infinitude of primes via the halting problem. think few mathematicians computer scientists will understand it because its crosscutting in a “not invented here, neither here nor there” sense.