A Little More on the Graph Isomorphism Algorithm
Looking at some of its components
 |
| From source, our congrats too |
Laci Babai’s first talk a week ago Tuesday is now a webcast here. There is also a great detailed description of his talk by Jeremy Kun, including background on the problem and how the proof builds on Eugene Luks’s approach.
Today we talk some more about ingredients of Laci’s algorithm.
He has one more scheduled talk this coming Tuesday on its key vehicle of progress: Either the current graph (and associated groups) in the recursion can be split up for divide-and-conquer, or it embeds a special kind of graph named for Selmer Johnson that can be handled specially. This strikes us as following another Chicago idea—the Geometric Complexity Theory programme of Ketan Mulmuley and Milind Sohoni—of looking for objects that obstruct the progress of algorithms; this post by Joshua Grochow discusses an example for matrix multiplication.
Rather than try to anticipate these further details and Laci’s forthcoming preprint, we thought we might give more high-level discussion of some more ideas and elements we recognize that make the algorithm work. We could be way off, but these ideas we believe are key to his breakthrough result. In any event they are useful insights that we hope you enjoy.
All Aboard
Laci’s talk is old style, a chalk talk. Most talks these days are powerpoint-style, but for details and complex mathematics, there is nothing like seeing a master at work using chalk. The virtues of such a talk are many. It slows down the information rate to the audience. This is good. Slow is good. Flipping powerpoint slides rapidly can be hard to follow. Watching Laci write out in his handwriting:
Graph Isomorphism GI
is wonderful. You can follow it, internalize it, and perhaps understand it.
The second is the use of many boards. This is wonderful. It gives a larger state for the audience, so they are more likely to understand.

Overview
The key ideas of the algorithm for GI are really classic ones from design of algorithms. The genius is getting them all to work together. The ideas break into two types: those that are general methods from computer science and those that are special to the GI problem.
Domain-General Points

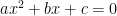

Of course there are no such formulas for high degree polynomials nor for non-polynomial equations. Enter the Newton method.
The idea of building the answer in small steps is the cornerstone of most important algorithms. Linear programming uses simplex or interior point methods, matching uses path-augmentation, and so on.
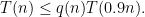
where 

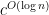

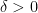


Either
has at least
triangles, or one can remove
edges to leave no triangles.
This enables a randomized algorithm to distinguish graphs that are triangle-free from those that are 
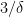
Domain-Specific Elements
But there is an expensive way to change this. We simply pick a set of vertices of
There is a cost. If we pick 




The worst case is when the factor is 
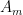




Unless
is tiny, the restriction of a giant homomorphism to the intersection of
over all unaffected elements
is still giant.
This looks like it should be either easily true or easily false, but Babai’s precise statement depends on the classification of finite simple groups.
The key inner point of the algorithm is to try subsets 
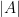
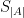
Open Problems
What is the full pattern of progress in the algorithm, with “split-or-Johnson” evidently directing the outermost loop and the above the inner loops? This may need more details to unfold.
Trackbacks
- A Quasipolynomial Time Algorithm for Graph Isomorphism: The Details | Math ∩ Programming
- 1 – A Little More on the Graph Isomorphism Algorithm - Exploding Ads
- Babai dice que el isomorfismo de grafos es un problema cuasipolinómico | Ciencia | La Ciencia de la Mula Francis
- Babai breakthru: graph isomorphism in quasipolynomial time | Turing Machine
- Blasts From the Past | Gödel's Lost Letter and P=NP
- A Quasipolynomial Time Algorithm for Graph Isomorphism: The Details | TRIFORCE STUDIO
- Babai’s Result: Still a Breakthrough | Gödel's Lost Letter and P=NP
- Laci Babai Visits Israel! | Combinatorics and more


There are some issues with this post and the LaTeX: I’m seeing your formulae replaced with “latex path not specified”.
“latex path not specified” for every equation in the post.
Ahh, seems to be a WordPress bug. http://lingpipe-blog.com/2010/07/14/latex-problems-not-ou-fault/
This is a recent wordpress bug, it seems that for some computers, all recent latex rendered by wordpress is giving this (except for equations that have previously been rendered before the bug happened). On the other hand, some other computers render everything just fine. The bug has been reported but still not fixed, see https://en.forums.wordpress.com/topic/latex-path-not-specified-errors-1?replies=72 . But presumably it is just a matter of time before a fix emerges.
Reblogged this on Pink Iguana.
Thanks, everyone! I noticed this for the first time on Wednesday in San Francisco with some of the older posts including “Lint for Math” which was relevant to a discussion there. The bug showed on my Windows 8.1 laptop then but not now; it never showed yesterday on my Windows 7 office machine or home Macintosh (Firefox on all three machines) nor on Safari or Chrome or Internet Explorer now. The displayed equations in this post are (a) the quadratic formula; (b) T(n) = q(n)T(0.9n); (c) Either G has at least \delta*n^3 triangles or you can remove \epsilon n^2 edges to leave no triangles, and (d) Unless m is tiny, the restriction of a giant homomorphism to the intersection of G_u over all unaffected elements u is still giant. Haven’t had time to be proactive, so will let this resolve itself.
Everything is fine. I’m using a PC with Windows 10 installed and updated versions of Chrome and Firefox.
WHAT IF P = NP?
We define an interesting problem called $MAS$. We show $MAS$ is actually a succinct version of the well known $\textit{NP–complete}$ problem $\textit{SUBSET–PRODUCT}$. When we accept or reject the succinct instances of $MAS$, then we are accepting or rejecting the equivalent and large instances of $\textit{SUBSET–PRODUCT}$. Moreover, we show $MAS \in \textit{NP–complete}$.
In our proof we start assuming that $P = NP$. But, if $P = NP$, then $MAS$ and $\textit{SUBSET–PRODUCT}$ would be in $\textit{P–complete}$, because they are $\textit{NP–complete}$. A succinct version of a problem that is complete for $P$ can be shown not to lie in $P$, because it will be complete for $EXP$. Indeed, in Papadimitriou’s book is proved the following statement: “$NEXP$ and $EXP$ are nothing else but $P$ and $NP$ on exponentially more succinct input”. Since $MAS$ is a succinct version of $\textit{SUBSET–PRODUCT}$ and $\textit{SUBSET–PRODUCT}$ would be in $\textit{P–complete}$, then we obtain that $MAS$ should be also in $\textit{EXP–complete}$.
Since the classes $P$ and $EXP$ are closed under reductions, and $MAS$ is complete for both $P$ and $EXP$, then we could state that $P = EXP$. However, as result of Hierarchy Theorem the class $P$ cannot be equal to $EXP$. To sum up, we obtain a contradiction under the assumption that $P = NP$, and thus, we can claim that $P \neq NP$ as a direct consequence of the Reductio ad absurdum rule.
You could see more on…
https://hal.archives-ouvertes.fr/hal-01233924/document
Best Regards,
Frank.
http://www.dharwadker.org/tevet/isomorphism/
I happen to stumble upon this 5-year old blog:
“The virtues of such a talk are many. It slows down the information rate to the audience. This is good. Slow is good.”
Had missed these valuable lines. Wonder how many people recognize this wisdom?!