Minor Insights Are Useful
Some examples of small insights that help

|
|
Cropped from src1, src2 |
Julia Chuzhoy and Chandra Chekuri are experts on approximation algorithms: both upper and lower bounds. Each is also interested in graph theory as it applies to algorithms.
Today Ken and I wish to talk about their recent papers on structural theorems for graphs.
The latest paper, by Chuzhoy, was just presented at STOC 2015 and is titled, “Excluded Grid Theorem: Improved and Simplified.” It builds on their joint papers, “Polynomial Bounds for the Grid-Minor Theorem” from STOC 2014 and “Degree-3 Treewidth Sparsifiers” from SODA 2015.
We note with amusement that the filename of the STOC 2014 paper on Chuzhoy’s website is improved-GMT.pdf while the new one is improved-improved-GMT-STOC.pdf. The versions of the GMT, for “Grid-Minor Theorem,” that they were improving had exponential bounds, notably one obtained in 1994 by Neil Robertson, Paul Seymour, and Robin Thomas. We concur with the authors that there must be an improved-improved-improved GMT out there. Perhaps we’ll see it at STOC 2016, but if the 3-2-1 progression keeps up, it will have zero authors.
The Result(s)
Here is the main theorem that was improved between the STOC papers:
Theorem 1 There is a universal constant
such that for every
, every graph
of treewidth
has a graph grid-minor of size
. Moreover the grid minor can be found by a randomized algorithm in time polynomial in the size of the graph.
This is a classic structural type graph theorem. It says that if a graph 
The 
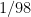

The Main Concepts
Both treewidth and minors involve kinds of embeddings of other graphs into subgraphs or set systems based on 



-
For every edge
of
.
-
For every vertex
of
forms a subtree of
The treewidth is the minimum 


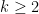
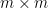


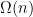
A graph 

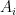

-
For every edge
in
and
.
-
For every
Together these conditions mean one can obtain 
In Praise Of Minor Results
Theorems of the above type often have quite complex proofs. As usual these proofs are broken down into pieces. The hierarchy is observation, claim, and lemma. Perhaps “claim” comes before “observation.” In any event the point is that we not only break long proofs into smaller chunks, we break down the conceptualization of their strategies. The sage Doron Zeilberger argues:
So blessed be the lemmas, for they shall inherit mathematics. Even more important than lemmas are observations, but that is another story.
I thought I would follow Doron’s suggestion and talk just about observations. They are used in their proofs and seem like they could be of independent interest.
Small Insights
One observation comes from the 1994 paper:
Lemma 2 There is a universal constant
such that every
-vertex planar graph is a minor of the
square grid.
This amounts to observing that all planar networks can be compactly implemented on grids. The significance for Chuzhoy and Chekuri is that Theorem 1 extends to all planar graphs. In contraposed form:
Theorem 3 There is a universal constant
such that for any planar
, all graphs
.
Note that the treewidth bound is independent of the size of
Two of the important little observations from the 2014 Chekuri-Chuzhoy paper are:
Claim 4 Let
be any set of non-negative integers, with
and
for all
. Then we can efficiently compute a partition
of
such that
and
.
Claim 5 Let
be a rooted tree such that
for some positive integers
and
. Then
The new paper takes its jumping-off point from this little observation: Treewidth can be approximately conserved while minorizing down to a bounded-degree graph. This may sound surprising but isn’t—think of the fact that expander graphs can have degree 3. Building on advances in a paper by Ken-ichi Kawarabayashi and Yusuke Kobayashi and an independent paper by Seymour with Alexander Leaf (both of which also improved the exponent from the 1994 result), the SODA paper shows how to keep the treewidth of the degree-3 graph above 
In graphs of degree 3, edge-disjoint path systems and node-disjoint path systems are the same on non-terminal nodes.
Well-Linked Observations
The plan and gadgets built for the proof come off well in slides for both Chekuri and Chuzhoy at a time when they had 


The disjoint path systems connect clusters of nodes that facilitate multiple switching and routing by obeying definitions like the following:
Definition 6 A node set
is well-linked if for all
with
,
, there are
-many node-disjoint paths connecting
and
. This allows paths of length
when
The maximum size 

Lemma 7 For graphs of treewidth
.
This concept and observation bridge between treewidth and problems of routing paths that build grid structures. Leaf and Seymour proved that having a path-of-clusters system of width 
Definition 8
is
-well-linked if for all
with
,
of congestion at most
.
The following result connects the bound 
Observation 9 If
into sides
and
.
The newest paper also uses versions where 
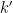


Open Problems
What are your favorite observations?


Dear Professor,
I have found a new complexity class that I called “equivalent-P” and I have showed it has a close relation with the P versus NP Problem. I have been making a paper that explain my ideas, and in the meantime, I decided to share them as a preprint in the web.
Here, I show you the abstract of the paper (so you can capture the idea):
“The P versus NP problem is one of the most important and unsolved problems in computer science. This consists in knowing the answer of the following question: Is P equal to NP? This incognita was first mentioned in a letter written by Kurt Gödel to John von Neumann in 1956. However, the precise statement of the P versus NP problem was introduced in 1971 by Stephen Cook in a seminal paper. We consider a new complexity class, called equivalent-P, which has a close relation with this problem. The class equivalent-P has those languages that contain ordered pairs of instances, where each one belongs to a specific problem in P, such that the two instances share a same solution, that is, the same certificate. We demonstrate that equivalent-P = NP and equivalent-P = P. In this way, we find the solution of P versus NP problem, that is, P = NP.”
In this preprint, I shall show that there is an NP-complete problem in equivalent-P and a P-complete problem in equivalent-P. Moreover, I shall show the complexity class equivalent-P is closed under reductions. Since P and NP are also closed under reductions, then we can conclude that P = NP.
You can read more on:
https://hal.archives-ouvertes.fr/hal-01161668/document
Kind regards,
Frank.
Frank, HORNSAT is a P-complete, so it is in P. As P is a subset of NP, HORNSAT is also in NP. If the “proof” of your “theorem 6.2” where correct you could get directly P=NP:
“Proof. If a P-complete is in NP, then NP = P, because NP is closed under reductions (see Theorem X) and P too [9]. Therefore, this is a direct consequence of the above.”
Which is obviously wrong.
You are certainly right. However, this can be fix if we find a problem that is P-complete and equivalent-P-complete at the same time. I was wondering if this exists, that is a P-complete problem that can be reduced any two problem in P and that reduction guarantees if the two instances can share a same solution, then they will keep this property after the reduction. Unfortunately, I don’t know if such P-complete problem exists and I suppose that will be too difficult to find.
The P versus NP problem is a logical fractal. It seems to be the proof-theoretic equivalent – in the sense of the Curry-Howard isomorphism – of a geometric fractal figure that’s actually the strange attractor of a chaotic process. Thus the two opposite opinions that P=NP and P!=NP both correspond respectively to the two lobes of a fractal Lorentz attractor. Therefore, any long-term attempt to solve the P versus NP problem is bound to exhibit the following characteristics:
1) The mental process is endless – that is, you can prove neither P=NP nor P!=NP. This parallels the fact that a chaotic process never comes to an end.
2) The more resources you put into trying to solve the problem, the harder it proves to be. This parallels the fact that a fractal figure exhibits new landscapes on whichever scale you try to explore it. By the way, it’s the only explanation I’ve found for why professionals and beginners feel equally competent on the P versus NP problem.
You and I, just like virtually every complexity theorist – whether professional or amateur – have been trapped into a mental chaotic fractal process. It’s a very interesting phenomenon, one that forces you to always imagine new theories, although approximate ones. Likewise, exploring a Mandelbrot set will force you to discover forever renewed and approximate fractal landscapes.
I don’t see how these comments are relevant to this post?
“What are your favorite observations?”, asked Pip. If you think my comparison of the P=NP issue with fractal behavior is not an observation, then what is? You might not share it, but you can’t say it’s not an observation. Now if you really think it’s wrong, I’ll be delighted to read your arguments.
Well, Serge, to me it appeared as if the other 2 responses were replies to Frank Vega’s comment, and which is certainly out of place.
The “location” of my comment somehow did not appear where I wanted to be- right after Frank’s..
So anyway, I was not referring to your comment in particular
The lack of moderation also has interesting side-effects. Beginner’s insights, questions and inspirations get spelled out publicly without scholar filters. It’s a genuine art to let the professional speak to the professional, the amateur to the amateur, so that sometimes – too rarely to my taste – some interferences may occur. After all, determinism and randomness are the two teats of complexity theory…
At the risk of drifting off-topic, I’d like to remark how very often it happens that well-conducted scientific debates are immensely enjoyable beneficial … no matter who’s right!
It was Scott Aaronson’s Shtetl Optimized discussion of climate-change that brought this reflection to mind … from which the following news-and-discussion is excerpted.
————
CONGRATULATIONS AND FELICITATIONS TO GIL KALAI
To speak in praise of Scott’s remark …
Non-CS readers of Shtetl Optimized may benefit from an instance in which Scott himself (and Greg Kuperberg too) commendably “walk their talk”.
Namely, Gil Kalai’s work on the fundamental infeasibility of scalable quantum computation receives an attentive and respectful hearing from the CS community — respectful even from researchers like Scott and Greg who hold opposing views — in large measure because Gil is a sufficiently accomplished mathematician to be (deservedly) honored as one of the ten plenary speakers at the upcoming quadrennial meeting of the European Mathematical Society at the 7th European Congress of Mathematics (7ECM) (Berlin, July 18–22, 2016).
It’s worth mentioning too, that later this week the Hebrew University of Jerusalem will host a two-day MathFest in Honor of Gil Kalai’s 60th Birthday.
Conclusion The reasoned and respectful, yet lively and marvelously simulating discourse among researchers like Gil, Scott, and Greg (and many more names need to mentioned too … John Preskill, Steve Flammia, Aram Harrow, etc.) is of tremendous benefit to engineering researchers (like me) … no matter who proves to be right.
Long may this discourse continue in its full respectful vigor, with Nature and Reason as the joint arbiters. Would that climate-change arch-skeptics appreciated the virtues of this ancient and enlightened scholarly tradition.
Appreciation, congratulations, felicitations, and thanks especially are extended to Gil Kalai!