Cynthia Dwork and a Brilliant Idea
Differential Privacy

|
|
Taekwondo source |
Cynthia Dwork is a computer scientist who is a Distinguished Scientist at Microsoft Research. She has done great work in many areas of theory, including security and privacy.
Today Ken and I wish to talk about the notion of differential privacy and Dwork’s untiring advocacy of it.
This concept is brilliant. It is, in our opinions, one of the greatest definitions of this century. Okay the century is just fifteen years old, but it is a terrific notion. The formulation was introduced in her paper with Frank McSherry, Kobbi Nissim, and Adam Smith at the 2006 Theory of Cryptography Conference. The name “differential privacy” was suggested by Michael Schroeder also with Dwork and McSherry at Microsoft, and appears first in her ICALP 2006 invited paper. Her expositions of the concept’s motivations and significance in that paper are a breath of fresh air and also animate her 2014 book joint with Aaron Roth. (Corrected—note also our followup.)
Dwork’s late father, Bernard Dwork, proved the first part of the famous Weil conjectures: the rationality of the zeta-function of a variety over a finite field. Ken had the rare privilege of doing an undergraduate seminar with him at Princeton in 1980 on ‘the’ zeta function—through Norman Levinson’s 1974 theorem placing at least one-third of the zeroes on the critical line—without being aware of the generalizations. Later Alexander Grothendieck and Pierre Deligne completed the rest of André Weil’s conjectures. The last part, due to Deligne, is usually considered the most difficult—of course the last step is always the hardest, an old saying I first heard from Ron Graham.
It is interesting to note that the actual proof by Deligne was not to Grothendieck’s liking. There are some who say that Grothendieck never even read it, since it did not use the deep tools he had developed to attack the conjectures. The last part of Deligne’s proof uses an estimation trick that Grothendieck certainly would not have liked: actually one that we use often in theory.
Roughly the argument goes like this: First one proves that
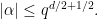
Then by a tensor-like trick one gets that

As this is true for arbitrarily large even 

Finally Poincaré duality then implies that
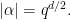
What Makes a Paper Important?
Clearly Bernard Dwork’s paper was important. It used deep methods to prove the first leg of the three parts of the Weil conjectures. Even if the later steps were harder, this step was still very deep, very hard, and very important. For this beautiful work, Dwork senior received, together with Kenkichi Iwasawa, the Cole Prize in 1962. This prize is given for outstanding work in number theory, and is one of the top prizes in the world.
This is one way to make a paper important: solve an open problem using whatever methods are available. Certainly a paper that solves an outstanding open problem is a likely candidate for being an important paper. For example, Andrew Wiles won the Cole Prize in 1997 for his essential finishing leg on Fermat’s Last Theorem.
Yet there is another way to write an important paper. Write a paper that changes mathematics or theory without solving an open problem. In many ways this is sometimes harder. It is hard to create a new concept in mathematics. We just talked about Carl Gauss’s beautiful introduction of the notion of congruence into number theory. One could argue, I believe, that this definition alone would have justified awarding Gauss a Cole Prize had one existed years ago. His definition changed number theory.
We would like to argue that the twin papers on Differential Privacy are among those great papers that may not have solved a deep open problem but that introduced a new and powerful notion.
One Door Closes…
The first half of her paper does not define the new notion. Instead, it puts a kabosh on a privacy notion that had been articulated as a chief desire as far back as 1977. This notion sought to assure that no breach of privacy—or at worst a negligible chance of breach of privacy—would result from permitted interactions with a statistical database such as getting means and percentiles. It was the analogue of semantic security in cryptosystems: any personal information gained by an adversary as a result of interaction with the database could be gained without it.
This might be achievable in a closed system where there is no information besides what is communicated via queries that the database allows. However, in the real world there are leaks of auxiliary information. The leak plus the database answers can cause a compromise that would not occur from either alone.
Here is a different example from the one involving Terry Gross in her paper—I am Ken writing this and the next section. Say my metro area has two charity drives, “Green Hearts” and “Blue Angels.” Suppose a metro official, thinking to praise me, leaks to someone else that I gave twice as much as the average donor to Blue Angels. That alone is not enough to determine my donation. However, the someone can then interact with Blue Angels to learn its number of participants and total gift. Indeed, charities often publish both figures afterward. Then my exact amount becomes known.
The ICALP paper’s impossibility proof, which was joint work with Moni Naor, shows that for any computationally formalized scheme attempting to achieve semantic security there is an “auxiliary information generator” that can break it by injecting leaks into the environment. Theory mavens can enjoy her proof if only to see how Turing machines that always halt are combined with a new definition of “fuzzy extractor.” If it doesn’t shut the door on the old objective, at least it changes the onus on anyone trying to revive it to find a weakness in her model. Exactly because her formulation is so general, this would be hard to envision.
Stepping Through Another Door
The punch line to the charity example is that I didn’t give anything to Blue Angels. I gave to Green Hearts. I wasn’t in the Blue Angels database at all, and yet I was compromised when its most basic statistics became known. Or maybe I gave equal amounts to both. Whatever.
Next year comes around, and the drives are on again. Once bitten, twice shy. Should I avoid Blue Angels? Well, Green Hearts publishes the same figures. I could sue the leaker, but that’s beside the main point:
What responsibilities and liabilities can the organizations managing the databases reasonably be expected to bear?
The insight, born of long work in the area and collaboration with the above-mentioned co-authors and others, is to focus on differences that can be isolated to one’s participation in the database. Hence the term differential privacy (DP).
In my example, the compromise did not depend on whether I gave to Blue Angels. Had I done so—had I split my gift between the charities—it would have made only a tiny difference to the Blue Angels’ average (in this case none, in fact).
The 2006 papers prove that the common idea of adding a random amount up to 

The formula in her definition has an interesting technical point. She formulates it in terms that the probability of a damaging disclosure can increase by only a small multiplicative factor. It is natural to say, “a 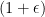


The other terms have powers 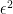
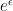

which makes other estimates easier to do. Her full definition is that a randomized query-return function 



![\displaystyle \Pr[{\cal K}(D) \in S] \leq e^{\epsilon}\Pr[{\cal K}(D') \in S].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5CPr%5B%7B%5Ccal+K%7D%28D%29+%5Cin+S%5D+%5Cleq+e%5E%7B%5Cepsilon%7D%5CPr%5B%7B%5Ccal+K%7D%28D%27%29+%5Cin+S%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
This definition is completely local to the database mechanism. It is also achieved by schemes in the last part of her paper, which she and her co-workers had already been developing. The wider point on the practical side is that this reinforces the legal view that a database provider should be liable for outcomes that result squarely from a person or persons stepping through their door.
Applications
On the theoretical side, the test of a new definition, a new notion, is simple. If the notion generates lots of interesting theorems about it then that is okay—indicative of a good notion. But it really is not indicative of a great notion. The acid test, in our opinion, is if the notion helps prove theorems from outside its own domain.
Translated to DP it means: all the theorems in the world using DP to prove theorems about DP are not sufficient. What is critical is if the DP notion can be used to prove theorems about topics that are not really about privacy. This is the acid test.
Happily DP passes this test. There are now results that use it to prove theorems about topics that seem to be distanced from any obvious connection to privacy. Let’s look at one due to Sampath Kannan, Jamie Morgenstern, Aaron Roth, and Zhiwei Wu—their paper just appeared in SODA 2015 as Approximately Stable, School Optimal, and Student-Truthful Many-to-One Matchings (via Differential Privacy).
We quote their abstract:
We present a mechanism for computing asymptotically stable school optimal matchings, while guaranteeing that it is an asymptotic dominant strategy for every student to report their true preferences to the mechanism. Our main tool in this endeavor is differential privacy: we give an algorithm that coordinates a stable matching using differentially private signals, which lead to our truthfulness guarantee. This is the first setting in which it is known how to achieve nontrivial truthfulness guarantees for students when computing school optimal matchings, assuming worst-case preferences (for schools and students) in large markets.
Open Problems
What other applications are there of this notion? Also are there simple definitions lurking out there that like differential privacy will change the entire field? Try to prove hard theorems, but also look for new definitions. They may—if you are “lucky”—be immensely important.
[Rewrote intro including link to followup correction post; changed ascriptions in later sections; changed possessive to “and a” in title]


” since it did not use the deep tools he had developed to attack the conjectures”…. what you state is wrong. Grothendieck did care about standard conjectures which are still unsolved. From what I heard, when D mentioned he found proof of Weil conjectures, G asked D whether he solved the Std conjectures. When D mentioned he found another route, he did not care about D’s result (probably G already knew this route since it is only a tensor product trick).
http://en.wikipedia.org/wiki/Standard_conjectures_on_algebraic_cycles
Reblogged this on Pathological Handwaving.