Galactic Sorting Networks
An improved sorting network to appear at STOC 2014

|
|
Teaching page source |
Michael Goodrich is a Chancellor’s Professor at the University of California at Irvine, and recently served a year as Chair of the UCI Computer Science Department. He has designed algorithms that cover all of the area spanned by axes of cleverness and high performance. This includes attention to algorithms that we have called (clever but) galactic for having enormous constant factors and/or high exponents that forestall practical implementation. An example is his paper last year with his colleague Pawel Pszona, “Cole’s Parametric Search Technique Made Practical,” which greatly tunes up an algorithm-improvement technique of Richard Cole. Now he has a new paper taking a notorious behemoth head-on.
Today Ken and I wish to talk about Michael’s recent work improving on the size of the famous AKS sorting network.
The initials AKS have become legion twice over in complexity. They are engraved on Wikipedia for the deterministic polynomial-time primality test of Manindra Agrawal, Neeraj Kayal, and Nitin Saxena proved in 2002. Two decades earlier, however, they designated the sorting network devised by Miklós Ajtai, János Komlós, and Endre Szemerédi. For sorting 
…[they have] little or no practical application because of the large linear constants hidden by the Big-O notation.
Michael begs to differ, and will explain during his talk at the STOC conference being organized May 31—June 3 by Columbia University, with workshops there and the main conference on 34th Street. His paper is one of the few that is single authored, one of the few that is on sorting, and is titled “Zig-zag Sort: A Simple Deterministic Data-Oblivious Sorting Algorithm Running in 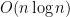
Sorting Networks
A sorting network is one that sorts in an oblivious manner, meaning that the comparisons done at each step are the same for all inputs. The following diagram is used to represent a small such network: the comparisons are the vertical lines, the inputs enter on the left, and each vertical line forms a swap with the larger value moving up and the lower going down.

Usually “oblivious” is not a great thing to be. But for sorting algorithms it is quite a useful property: it makes the algorithm simpler to describe, it makes it easier to implement in hardware and even software, and makes it useful in many security applications. The latter follows since the operations at each step are the same independent of the input; thus, someone watching the comparison operations, not their values, can learn nothing from the algorithm’s execution. Of course there is an interesting cost to being oblivious: the algorithm runs in the same time even if the original input is already sorted. I find the latter an interesting issue, since in practice the input may be in sorted order or at least close to this. But that is another question.
AKS
The best sorting network for many years was due to Kenneth Batcher and has size 



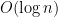
Batcher’s method is much better, unless
exceeds the total memory capacity of all computers on earth!
As we say here at GLL, the AKS sorting network is galactic: it needs that 
I must add that before 1983 the search for a better method than Batcher was a “hot” research problem. I worked on it trying to use random networks, but could not make any progress. Even in 1971, David Van Voorhis could beat Batcher when 


The Amazing 0-1 Law
One of the coolest results in sorting theory is the 0-1 Law. This principle shows that a sorting network is valid if it can sort all 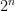


It is interesting to note that the 0-1 law has been generalized to networks that sort most vectors, rather than all of them. This is contained in a 2005 paper by Sanguthevar Rajasekaran and Sandeep Sen. I thought also about this years ago, but never got a result that seemed interesting. Theirs does.
Again the 0-1 law is one of those few results that we have in theory that say that an algorithm works for all inputs from a large universe provided it works correctly for a small subset of the universe. It would be interesting to see if such theorems could be proved for other classes of algorithms, even if we have to restrict the type of algorithm greatly. Such theorems could be extremely useful, but they seem to be hard to find.
Zig-Zag Sorting
Here is Michael’s new algorithm in pseudocode:

There are some comments that I want to make, besides the usual invitation to see the paper for the details. One is that the code is quite short, and that while the code is short, the main issue is proving that the code works—we sketch some details in a moment. The fact that the proof of correctness is much harder than the algorithm is a recurrent theme in modern algorithms. The classic quicksort algorithm is even shorter:

This phenomenon suggests to me a possible conjecture:
Could there be very short algorithms for SAT or other hard problems, factoring for example, that are short as programs, but have long complex proofs?
A related conjecture is: can we somehow prove that there is no very short program for SAT that runs fast? I think one of my first statements on GLL was that we could not rule out a polynomial time algorithm for SAT that fits on a single page. Is there any way to make this into a serious conjecture? How would we formalize it?
The last comment is that Michael does have to sacrifice the 

Some Ingredients
The name “zig-zag” comes from places where the algorithm does a shellsort-type percolation going up rather than down, and more simply, flips upside down some sequences of elements that were nearly sorted from a previous step. This seems “counter-intuitive” as he says, but such steps are allowed also in Batcher’s bitonic sort, since flipping a bitonic sequence upside-down still leaves it bitonic. Such flips can ultimately be eliminated in Batcher’s network, as noted here, whereas they seem more integral to Michael’s networks.
The 




-
For any
, at most
of the largest
elements in
wind up in
-
For any
, the above holds with
replaced by the somewhat smaller value
.
-
For any
, whenever
is the number of the largest
of those
is the count of elements in
of the smallest
In the third clause, it is not mandated that the 
There remains the task of coming up with
Open Problems
Is there a really practical sorting network that is asymptotically optimal? Can it have


If there is a polytime algorithm for SAT, there is also one with a very short code. It just has to run all possible algorithms of length at most C for n^C steps and try the solution given by them (it is easy to make an algorithm also give a solution if you have one that decides existence). If none of the solutions work, then return unsatisfiable. Hm, since this is also an algorithm for SAT, did I just prove that there is an algorithm whose size is at most O(log C) where C is the best possible constant of the running time? In fact we can make it even “shorter” by running algs for 2^C steps and so on. Couldn’t we just try all such algorithms and thus prove for any C that there is no alg for SAT running in n^C? I must be wrong somewhere…
I see that I have treated the constant of the running time a little too liberally, so the D from Dn^C should not be ignored.
In fact here is another approach that even works for sorting networks: Start to generate all possible sorting networks along with a proof that they run in time O(nlogn). If a valid proof is found, then run that algorithm. This is correct, as we know that AKS exists. Of course our hidden constant might be much worse but we can also include that in the algorithm, we only have to describe it (or a slightly bigger number), this would of course take very small space.
While it’s a great paper, I don’t think it’s fair to give that pseudo code as evidence of the code being short when the pseudo code isn’t given for the “Reduce” subroutine! That seems to be where a lot of the action is.
yeah sorting networks seem to yet contain some deep mysteries. once wondered if other key algorithmic problems can be reduced to sorting somehow, it seems to be the case. also it seems you didnt cover this recent paper on optimal sorting networks by Bundala/Zavodny… right down your alley? any opinions? similar to the erdos discrepancy problem results (found via SAT solvers) which you did cover in much detail. more musings great moments in empirical/experimental math/TCS reseach
(arg) last link fixed is here
Sorting is complete for TC^0. See http://en.wikipedia.org/wiki/TC0
Are badpoor computer scientists common?
Can every one be goodrich?
Sorting networks are certainly interesting things. The data-blind aspect always intrigued me as well and led me to a different consideration: is it possible to sort an integer array without doing any compares at all? I worked on this a while – basically I swapped out the compare between two integers with a few math operations that had the same effect. Thus, the network becomes truly blind – it is a series of operations which never depend on the data, but ends up sorting the data. Unfortunately I couldn’t figure out if I actually had a compare-less sort.
In particular, let’s say I’m trying to sort the pair (a,b). Then the ordered pair is:
[(a+b) – abs(a-b) , (a+b) + abs(a-b)]. This pair is ordered smallest to largest.
However, how do I calculate abs(a-b) without using a compare at some point? I could calculate ((a-b)^2)^0.5 which would do the trick – but how do you actually do a square root without using a compare in the algorithm? I also tried bit-twiddling with the 2’s complement representation of integers, but couldn’t do that without a compare at some point.
But, if you figure out that trick, then the sorting network will scale it up and allow compare-less sorting of arbitrary sized lists of integers. Neat!
oops – missing a division by two in the formula above to make it work. FYI.
For the win!
http://graphics.stanford.edu/~seander/bithacks.html#IntegerAbs
Are you sure it isn’t “snorting”?
Why join the navy when you can be a pirate?
– Steve Jobs
On 4/24/14, 11:46 PM, “Gödels Lost Letter and P=NP” wrote:
WordPress.com Pip posted: ” An improved sorting network to appear at STOC 2014 Teaching page source Michael Goodrich is a Chancellor’s Professor at the University of California at Irvine, and recently served a year as Chair of th”