The More Variables, the Better?
Ideas from algebraic geometry and arithmetic complexity

Hyman Bass is a professor of both mathematics and mathematics education at the University of Michigan, after a long and storied career at Columbia University. He was one of the first generation of mathematicians to investigate K-theory, and gave what is now the recognized definition of the first generation of K-groups, that is 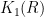

Today Ken and I wish to discuss an idea used in a paper on the Jacobian Conjecture by Bass with Edwin Connell and David Wright.
One of the most powerful methods we use in theory is often the reduction of the dimension of a problem. The famous JL theorem and its relatives show us that often problems in high-dimensional Euclidean spaces can be reduced to much lower dimensional problems, with little error. This method can and has been used in many areas of theory to solve a variety of problems.
The idea used by Bass and many others is the opposite. Now we are interested in lifting a problem from a space to a much higher space. The critical intuition is that by moving your problem to a higher space there is more “room” to navigate, and this extra “space” allows operations to be performed that would not have been possible in the original lower-dimensional space. An easily quoted example is that the Poincaré property was proved relatively easily for spaces of dimension 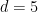
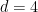

Adding Variables
Let 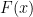


The Jacobian Conjecture (JC), which we have covered several times before, indeed recently, studies when such maps are injective. The trouble with the JC is quite simply that such maps can be very complex in their structure, which explains the reason JC remains open after over 70 years.
A very simple idea, almost trivial idea, is to replace 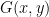
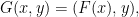
for new variables 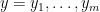
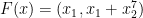


The new variables 

Why is this of any use? Clearly
Using The Extra Variables
The answer is that we can use the extra variables to modify the polynomial 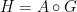


Here is a famous result from the Bass-Connell-Wright paper:
Theorem 1 Given
there is an automorphism
so that
has degree at most three. Moreover
is injective if and only if
is.
This allows the JC question to be reduced to the study of cubic maps. Of course such low degree maps still are complex in their behavior, but the hope is that while they are on many more variables the restrict on their degree many make their structure easier to understand. This has yet to be fruitful—the JC remains open. The following quotation from the paper explains the idea:

General Use In Theory?
One idea is to try and use this stabilization philosophy to attack problems about polynomials that arise in complexity theory. For example can we use the addition of extra variables to attack the power of polynomial modulo composite numbers? Suppose that 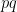
Two simple examples from arithmetical complexity are aliasing variables in a formula to make it read-once, and the Derivative Lemma proved by Walter Baur and Volker Strassen. In the latter, the idea is to take a certain gate 


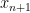

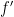


In the Derivative Lemma the gate 

Open Problems
Are there general rules of thumb on when you should increase versus decrease the dimension? Or when to induct on the output gate(s) of a circuit, on the number of variables going down, or on the number of variables going up?


One example is extended formulations of polytopes. Sometimes optimizing over a complicated polytope Q can be done efficiently if one finds a higher dimensional polytope R that has few facets, but projects down to Q. Examples of such polytopes are the spanning tree polytope, or the permutahedron.
This brings up once again the problem of finding the proper form of derivatives (differentials, Jacobians, tangent functors, Taylor series, etc.) in Boolean spaces. A few wools of bit along these lines are gathered in this bag:
☞ Differential Logic and Dynamic Systems
Increasing variables could help in the study of random processes-processes that are highly memory dependent and non-Markovian could potentially be simplified by increasing dimensionality.
A similar idea is used in cryptography. Take a function f(x) and define a function F(x;r), where r denotes some extra variables. Then F is a *randomized encoding* of f if (1) you can efficiently “decode” f(x) from F(x,r) for any r, and (2) the distribution F(x,r) induced by random choice of r can be simulated given only f(x) — so this distribution carries no more information than f(x).
Then F inherits many of the cryptographic properties of f (for example, if f is one-way, then so is F; if f is pseudorandom, then so is F). But F can have much lower computational complexity. So often it suffices to just design something that works for a low complexity class, then via randomized encodings you get some higher classes for free. For example, every poly-size circuit has a (computationally secure) randomized encoding with constant depth.
There is a nice series of papers by Benny Applebaum, Yuval Ishai & Eyal Kushilevitz that develops randomized encoding and gives some very interesting applications.
IMHO similar approach we can see in graph theory. To represent a graph we need adjacency list only, but adjacency matrix is more useful for many algorithms and more over distance matrix may be much more useful. I.e. very often redundant representation is very helpful.