Teaching Helps Research
How teaching interacts with research

Tim Budd is a computer scientist who works mostly in programming theory and practice. He once was a graduate student of mine, and did his thesis work on an APL compiler. Ken recalls that when he asked a certain undergraduate classmate in 1980 whether anyone had written a compiler for APL, the friend replied “A compiler for APL? That would be worth a Nobel Prize!” Well, we have gone another year of missing on our recurring prediction that a person we recognize as a computer scientist will win a Nobel Prize, though the prize in chemistry this year came close.
Today I want to talk about the relationship between teaching basic material and doing research.
Budd comes to mind for several reasons: for one he is a dedicated and excellent teacher. He has written a large number of well received textbooks on many topics related to programming—see this. On his home page he has an amusing quote:
Whenever I teach a course there always comes a moment as I’m reading the textbook where I say “you know, I think I could write a better textbook than this”. The unfortunate thing is that this is true even when I am using my own book!

I am not such a great teacher, but I try to make the material special for my students. One interesting principle that I discovered years ago is the close relationship between teaching and research. In my experience, teaching even basic material can lead to interesting research results. I will cite one ancient example of mine, a recent one of mine, and one of Ken’s. For a wonderful example of this phenomena see this—the story how Rao Kosaraju discovered a new algorithm for finding strong connected components in directed graphs. It happen because he was teaching basic graph algorithms, and—I will not spoil the story, so read about it.
I think the connection between teaching and research is even more relevant these days because of the rise of on-line teaching, with the possibility that teaching could change radically in the future. One possible future, among many, is that we will no longer be teaching basic material. Our undergrads and perhaps even grad students will all be using some type of on-line system to gain the basic knowledge they need. This may or may not happen, but it did raise the issue of the connection between teaching and research. So let’s discuss some examples.
APL
Budd was a student of mine when I was at Yale. His PhD really came about because I happened to be teaching introductory programming based on APL. I have discussed this before in detail:
When I had to learn APL in order to teach the beginning class I decided to start a project on building a better implementation. The standard implementation of the language was as an interpreter, and one of my Yale Ph.D. students, Tim Budd, eventually wrote a compiler for APL. We also proved in modern terms a theorem about the one-liners of the language. Each one-liner could be implemented in logspace; this was not completely trivial, since the operators were so powerful. Perhaps another time I will discuss this work in more detail. For now see Tim’s book on his APL compiler.
Tim’s book has a simple title: An APL Compiler. There wasn’t one before. Today there is another prominent one, called APEX. There is also a translator to the C# programming language, whose intro page declares:
Code in APL – ship in C#: The Dream becomes a reality.
Is this a dream? Worthy of a Nobel Prize? Well what happens in computer science is that both machines and software methods change. On-the-fly compilation of segments of a program became often just as good as whole-program compilation on the pipelined machines of the 1990’s.
However, our other work on APL functions being in logspace might possibly be more useful now with the advent of streaming computing models and the MapReduce framework. If they can be run in log-many passes by memoryless finite-state automata according to Ken’s vector-machine model, then they would be in 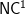
A Poor Person’s PCP
The following arose this last week as I tried to make up my complexity class midterm. Consider the following problem: 3SAT

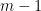
Theorem: The problem 3SAT
is NP-complete.
The proof is easy. Let’s allow arbitrary clauses—it is easy to fix them to be clauses in 3SAT format. Then add to the clauses 

Clearly if 
This is the solution my students found. I had in mind a different method, which none found. Take the clauses 



What I liked about this latter idea is that it really uses a repetition code to prove the problem: just state the problem twice and it became more error tolerant. This is the same as just repeating a message to make it tolerant to errors. Note, we could map 

where each is the same set of clauses on new variables. Then we would have either: (i) there is an assignment that makes all the clauses true, or (ii) there is no assignment that does not have at least
One interesting issue is: could we directly follow this path to get really high error tolerance based just on a use of error correcting codes? Of course the known proofs of the PCP Theorem use error correction ideas, but they do not use a direct link to an error correcting code. Can this be done? I once recall Sanjeev Arora saying to me that he believed that the PCP Theorem really was a result about error correction, and that it should have a “pure” coding theory proof.
Ken’s Example
Ken was lecturing once in an advanced graduate course on Leslie Valiant’s theorem on polynomial-time universality of the determinant. He followed a proof in a survey paper by Joachim von zur Gathen that given an arithmetic formula 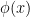



Open Problems
Do you have other stories of connecting teaching to research?


“A compiler for APL? That would be worth a Nobel Prize!” -Sorry, it is impossible to win a Nobel Prize for any compiler. Otherwise, Niklaus Wirth is the first person to win the Prize for his compilers. I think the situation is very-very strange, because today good compilers and good programming languages are the most necessary things for scientific and engineering progress. As for chemistry computer modeling of chemical reactions MUST be obligatory step for every chemist (unfortunately, today majority of chemists dislikes computer modeling). However, not only quantum chemistry, but also so-called math. (computer) chemistry, i.e. graph theory applications is very worth. In this way we have to call Haruo Hosoya, Milan Randić, Harry Wiener, Richard Sanderson and other well-known names. Anyhow, I am glad to see this Prize for chemical modeling! Congratulations!!!
The 1965 Nobel in Chemistry went to John Pople, Walter Kohn, and Lu Jeu Sham for algorithmic advances that (in the 1960s) were not considered to be “computer science,” but nowadays would find a home in many computer science departments. Other Nobels having a strong algorithmic component include: Lauterbur and Mansfield (Medicine 2003), Wilson (Physics 1982), Cormack and Hounsfield (Medicine 1979), and Gabor (Physics 1971).
Fred Sanger arguably deserves an algorithmic Nobel for “shotgun” gene sequencing methods, but since Sanger already has received two Nobels (and is 95 years old), the award committee had better hurry!
In 1965 Robert Burns Woodward was awarded the Nobel Prize in Chemistry. He was excellent chemist, but his approach was not algorithmic (in computer sci. sense). Sir John Anthony Pople was awarded the Nobel Prize in Chemistry with Walter Kohn in the year 1998 for Gaussian program. This program is quantum chemistry program, i.e. it is based on Schrödinger equation, but it does not use graph theory.
Mt2mt2, this comment motivated a fruitful keyword search for arxiv articles that link ‘quantum chemistry’ to ‘graph theory’ … there are plenty of them!
A story about Enrico Fermi illuminates the cognitive mechanisms at work:
Igor Carron’s fine weblog “Nuit Blanche” provides abundant week-by-week examples of the two-way creative flow between practical engineering applications (in quantum simulation and otherwise) and fundamental algorithmic understanding.
History teaches that this creative flow is facilitated, rather than hindered, by the communication difficulties that engineers and mathematicians commonly encounter. After all, marriages can be happy and fruitful even when coupled partners are mysteries to one another!
John Sidles, I said: Gaussian is based on Schrödinger equation, but it does not use graph theory. Sometime, quantum chemistry may be combined with molecular dynamics, catastrophe theory etc. Also, classical quantum chemistry approach may be combined with math.chemistry approach (i.e. graph theory, i.e. classical structural theory of chemical compounds).
“In chemical graph theory and in mathematical chemistry, a molecular graph or chemical graph is a representation of the structural formula of a chemical compound in terms of graph theory. A chemical graph is a labeled graph whose vertices correspond to the atoms of the compound and edges correspond to chemical bonds.” (wikipedia: molecular graph)
“The first step in solving a quantum chemical problem is usually solving the Schrödinger equation (or Dirac equation in relativistic quantum chemistry) with the electronic molecular Hamiltonian. This is called determining the electronic structure of the molecule. It can be said that the electronic structure of a molecule or crystal implies essentially its chemical properties. An exact solution for the Schrödinger equation can only be obtained for the hydrogen atom. Since all other atomic, or molecular systems, involve the motions of three or more “particles”, their Schrödinger equations cannot be solved exactly and so approximate solutions must be sought.” (wikipedia: Quantum chemistry)
From here we can see that in contrast to quantum chemistry the mathematical chemistry does not use electronic structure, Hamiltonian etc.
Mt2mt2, when we search the arxiv for “graph theory” and “quantum chemistry” and “tensor network”, we find that graph theory is accreting ever-deeper meanings in quantum chemistry (and many other simulation disciplines). This deepening understanding flows both ways, needless to say!
Sorry: classical quantum chemistry vs. chemical graph theory are different models. (About “tensor network” I have no to say, but I’m glad to see the progress 😉 ) I use arXiv for my preprints, but these are preprints only, aren’t these? BTW nobody yet found fatal error in my proof “GI is in P”: http://arxiv.org/abs/1004.1808 (version 6)
Can you find? 😉
My story pales in comparison to the legendary Kosaraju lecture, though here it is:
I had committed to teach both classic Lipton-Tarjan planar separators and cycle separators in a single lecture for a class on algorithms for planar graphs and beyond. I had too much false confidence, due to having used Miller’s cycle separator algorithm in my own research and due to having a chapter on said algorithm in Klein’s forthcoming book as a valuable teaching resource.
The lecture got closer and closer and I still could not wrap my head around the cycle separator algorithm to the extent necessary for class-room teaching (never mind uploading a video of that lecture to the Internet).
Until, finally, one of my attempts at simplifying the algorithm seemed to work out. As I was somewhat forced to present both algorithms in one lecture, I tried to make them as similar as possible, modulo lots of details of course. Unfortunately, the lecture was not quite as crisp as it could have been, but this new unified algorithm contributed to both a theory paper and an implementation paper.
APL interpreters can now be made very fast, so I doubt there’s much interest in building a compiler today. I think the object code would have to be quite large, embedding a fair part of an APL interpreter. Whatever you’d gain in speed, you’d lose it in space. In connection with a previous post: polynomial reductions are often feasible, but not always desirable.
This topic is reminiscent of the recurring subject of LISP compilers. In my opinion, the mathematical, neat and tiny computing models are meant to be interpreted rather than compiled. On the other hand, the languages that more or less mimic a physical machine – such as FORTRAN, C or ADA among so many others – are designed to be compiled but not interpreted.
Recall FORTRAN-4 (OS 360/370) and Q Basic (MS DOS) 🙂
Also Ada & LISP are not very used today… like turbo-Prolog, for example.
Yes, and there are also a few other functional languages – like Haskell and OCaml – that come out in both interpreted and compiled versions. But then again, I find that the Nobel Prize joke is still valid. 🙂
In 1990 I wrote in my letter to editor of BYTE magazine (this letter was printed under the title “The End of Pascal?”, BYTE, March, 1990, p. 36): “Turbo Pascal 2.0 comes one disk; version 5.0 comes on 20 (with toolboxes). In my nightmare I see version 8.0. It occupies 1 Gb of disk space […] Standard Wirth Pascal’s strength is its simplicity. What happened to the 30-page Pascal manuals? The new manuals are the largest ever. This new non-Pascal Pascals could result in the destruction of the language. We can lose the best Pascal properties and keep the bad ones.” Today we have the same problems for other programming languages, and so that my letter is still valid 🙁
I often wonder about the effectiveness and efficiency classes of teaching a given class of learners a given class of learnables.
The archetype of that problem is probably Meno’s question to Socrates:
Along these lines, if somewhat tangentially, are some questions that I’ve wondered about for many years.
How do research and teaching interact, and how might they serve to catalyze one another in the best of possible practices? What sort of role could information technology play in integrating the two missions of inquiry and instruction? What are the obstacles that inhibit the process of integration?
Here’s an early paper that made a beginning at addressing these questions:
An Architecture for Inquiry : Building Computer Platforms for Discovery
There’s a downloadable copy of the paper, along with the conference slides, here.
I remember vaguely a story about a Chicago physics professor who was giving a physics course in a far-away campus of the university to an audience of three students.Years laters two of these students won the Nobel prize and a few years afterwards also the teacher.
The professor was Subrahmanyan Chandrasekhar and his two students were Chen Ning Yang and Tsung-Dao (T.D.) Lee.
As Chandra tells it:
The first Nobel Prize that relied heavily on exploiting an algorithm was probably the 1915 Physics prize to the Braggs, father and son, for X-ray crystallography. It should be noted that Bragg fils, as head of the Cavendish Laboratory in his later years, encouraged X-ray crystallography research there in biology, and this famously led to the 1962 prizes to Kendrew, Perutz, Watson, Crick, and Wilkins, again, all reliant on algorithms.
Mullis’ invention of PCR of course was 90% algorithmic, 10% biological. (1993)
Numerous Economics prizes were to work that was explicitly algorithmic, including that of Herbert Simon. Is he the unique Nobel prize winning CS professor?