A World Without Randomness
What if there were no coin flips?

|
|
By permission of Hector Zenil, artist. |
Leonid Levin has originated many great ideas in our field. Indeed he had a share with Stephen Cook in the idea of 

Today Ken and I want to use Levin’s ideas to talk about what the world would be like if there were no randomness, no coin flipping, not even with slightly biased flips.
Persi Diaconis has famously showed that actual coin flipping by people has bias. The bias is small, but it is non-zero. He has said,
[C]oin tossing is fair to two decimals but not to three. That is, typical flips show biases such as .495 or .503.
This kind of bias, however, still allows one efficiently to extract truly-random bits. We are talking about something more extreme.
Heads
One day when my daughter Jennifer Lipton-O’Oconnor, whom I’ve mentioned for a unique diagonal argument, was quite young, I thought I would talk to her about randomness. I recall we were in our basement area, and I started to explain how quarters, that is American twenty-five cent pieces, could be used to create randomness. She listened a bit and said,
But they always come up heads.
I immediately said no and found a quarter and started to flip it. The first was indeed heads, then the next, and then the next… Finally, after five straight flips in a row of heads, Jen said, “see I told you,” and walked away.
I sat there thinking that this was somehow a failed lesson. I also thought of multiverse ideas. I wondered why I happened to be in the universe where the dad—me—came out looking foolish.
The play “Rosencrantz and Guildenstern are Dead” opens with 157 heads in a row. By multiverse theory there exists a world where that really happened. Playwright Tom Stoppard could have been more subtle and had the coin flips trace out the sequence of prime numbers, in the manner of the novel Contact, or the binary expansion of π. Since the latter are low-complexity deterministic sequences, by Levin’s measures they are scarcely different from all-heads as outcomes. In an unrestricted multiverse, there are worlds where those sequences occur too, for as long as is relevant. Any of those worlds could be our world.
So let’s look at a world of potentially no coins that are random.
SAT Is Not Too Hard
In this world we discover that SAT is relatively easy to solve. Consider our old friends Alice and Bob. Bob’s job is to create an algorithm that generates hard instances of SAT. More formally, Bob is given the input 





The question is: Can Alice solve these generated problems in polynomial time? The answer of course is still open. But Alice can solve them with a budget of slightly more than polynomial time.
Here is how she does it. She uses Levin’s idea. Alice does not look at the clauses 

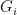
Roughly speaking, what Alice does is run them all, in a staggered fashion. The 
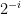


Deterministic Adaptation
Alice’s algorithm is fixed, and its only variable factor is the interaction with Bob’s
It can, however, be coded to abide by any explicitly given constructible time bound 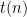



When Alice arrives at the correct
To the outside world, it looks like Alice becomes a smart solver. In reality she is “cheating” by having stumbled upon the right helper to give her cribbed answers. The answers look like they are coming naturally, but they really only exploit Bob’s being a fixed target. Bob is not allowed randomness so as to change the fixed pattern that Alice eventually emulates, nor adaptiveness to Alice’s actions apart from formula requests and incrementing
Jürgen Schmidhuber, whom Ken just met at the CIG 2013 conference in Niagara Falls, Ontario, has drawn some practical learning aspects of Levin’s universal search. This also underlies his proposal that cosmological processes are pseudorandom. He has itemized several more predictions and possible telltales of a highly deterministic universe. But first let us look at a world that is easier for complexity theorists to imagine, which I (Dick) have said I believe in.
A Similar World
Levin’s original paper with his idea showed that if 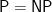


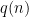

Thus Alice settles down to 
This gives our sense in which a world without randomness is like a world where 
The analogy also makes it less farfetched to ask, is our world Bob? Instead of asking metaphysical questions about determinism and mechanism, all we are asking is:
Is it true in our world that every source of SAT instances is eventually 100% solved by
?
Well we can also flip this around to say what this means for the idea of SAT being hard.
What Does This Mean?
Of course most of us believe there are truly-random coin flips, and most believe 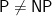
Thus a solver of SAT, it seems, must inherently be an extractor or randomness. Not, perhaps, in the formal sense of a randomness extractor as we mentioned before, but some kind of extractor nevertheless. The solver must be able to find the solution, which seemingly must contain lots of entropy. I cannot make this precise, but it seems right.
The instance-generation problem has of course been addressed by Levin in numerous papers, in the larger context of distributional complexity. We note especially his 1990 FOCS paper with Russell Impagliazzo, whose title announces that there are “no better ways to generate hard NP instances than picking uniformly at random.” The details require much more attention than we are giving here, since there are even simpler senses in which randomly-generated instances of SAT are almost trivially easy to solve.
Dr. Hector Zenil of Sweden’s Karolinska Institute, who has kindly allowed us to use his low-complexity artwork of Levin above, has written many papers on related subjects. These include a paper on Turing simulation related to lengths of proofs, this essay for the Foundational Questions Institute (FQXi) titled, “The World is Either Algorithmic or Mostly Random,” and an edited book. He also writes a blog on computational life processes, in which these subjects are also covered.
Open Problems
How could one possibly tell one is in a world with no randomness? Well there is almost a way to prove it: flip a coin a million times—perhaps quantumly or noisily—and hit upon a much shorter
Short of being in it, what more can we say about a world with no randomness?
[changed Levin pic and added material from Hector Zenil]
Trackbacks
- “Who are you today, Doc? Einstein?” Lord John Whorfin: “Lord John Whorfin. If there’s one thing I hate, it’s to be mistaken for somebody else.” « Pink Iguana
- Stealing Strategies | Gödel's Lost Letter and P=NP
- 512 | Gödel's Lost Letter and P=NP
- Could We Have Felt Evidence For SDP ≠ P? | Gödel's Lost Letter and P=NP
- Does Program Size Matter? | Gödel's Lost Letter and P=NP
- Leprechauns Will Find You | Gödel's Lost Letter and P=NP
- Kinds of Continuity | Gödel's Lost Letter and P=NP
- Transcomputational Problems | Gödel's Lost Letter and P=NP
- Our Trip To Monte Carlo | Gödel's Lost Letter and P=NP
- Leprechauns Stay Home | Gödel's Lost Letter and P=NP


As Leibniz observed, <i<Randomness is Relative to POV.
→ The Present Is Big With The Future
If you live in a world without a normal source of randomness, how many truly random bits do you need to simulate a world like ours for 20 billion years so that the possibility of detecting the lack of randomness from the inside is 10^-100? Wouldn’t a few thousand random bits be enough, assuming standard cryptographic conjectures?
If P=NP then comedic possibilities become near-certainties…
Einstein was right: the world isn’t random in the least. But he refused to admit what seems obvious now – that it will forever look random to us living beings… because we’re part of it!
There are concepts that we have invented for ourselves that appear to be pure abstractions, that do not manifest themselves in our universe. To me ‘random’ seems to be one of those. Another is ‘perfect’, and I still have deep suspicions about ‘infinite’. But I certainly agree that my own POV is in itself neither universal nor objective.
In some ways a world with no randomness — essentially a fully deterministic world — is a lot less interesting than a world full of magic. But it still can be chaotic enough that our species could reach the end of time without fully understanding even a fraction of it, and given the limitations of our species, even if we iterated everything no single person would ever be able to keep it all in there head at anytime. That still leaves plenty of room to keep things interesting…
Paul.
Okay, no one else is doing the calculation, so I should. The universe so far could have performed about 10^120 operations (http://arxiv.org/abs/quant-ph/0110141). Say we want to simulate a universe for much longer that than, say out to 10^200 operations, using a strong n-bit cryptographic hash function in counter mode as a pseudorandom number generator. If the simulated universe folk know the generator but not the key, they need around sqrt(2^n) operations to detect nonrandomness. Thus, we need n = log_2 10^400 = 1329 bits. So a deterministic universe is fewer than 2000 bits away from a random universe.
Another idea worth recalling here is Peirce’s notion that the balance of randomness versus ruliness in the universe as a whole might change over time, perhaps even exhibiting growing lawfulness as time goes on, as I mentioned in an earlier discussion.
→ Wherefore Aught?
This rather echoes the Epicurean/Lucretian concept of the Clinamen, or “Swerve”.
So if there is no randomness then P=NP or is close. But if P=NP that doesn’t mean there can’t also be randomness, did I get that right?
It is know that the data which is most likely to be output by computers – brains included – has the characteristic property of having low Kolmogorov complexity. Or course, that applies to proofs and algorithms as well.
On the other hand, experience tells us that an efficient solution to a given “hard” problem is more likely to be complex than a slow one. For example, the fastest known algorithms for integer factoring all require a rather solid background in algebra to understand their proofs, whereas the naive algorithm is straightforward. Therefore, it’s quite reasonable to call a problem “hard” whenever all of its efficient solutions have a high Kolmogorov complexity. This new definition of problem complexity has at least two advantages: first, it provides a nice explanation of the apparent undecidability of problem complexity – since the Kolmogorov complexity of arbitrary data is known to be undecidable in general. Second, it also explains why we have a hard time trying to solve hard problems, since their efficient solutions are unlikely to be output by our brain or by any intelligent program! That being said, a reasonable measure of the hardness of a problem would be the behavior of the Kolmogorov complexity of its algorithms when their desired efficiency tends to a given polynomial… but this also is probably undecidable, unfortunately.
An interesting consequence of the discussion we had about “perfect proofs” was there’s no such thing as absolute certainty. However numerous the different proofs of a hard theorem, however often they’ve been checked, their error probability will never equal zero. In view of the foregoing, this fact seems to admit a more precise wording: given any candidate algorithm A for a problem P, the harder P is, the less certain you can be that A is both correct and efficient. For, efficient algorithms for hard problems being unenlightening – hard to understand and to prove correct – they’re unlikely to come out of a mathematician’s brain or of an intelligent program. Consequently, the only algorithms that are likely to get found are either the inefficient solutions to hard problems or the efficient solutions to easy problems.
This conjecture may be compared with the uncertainty principle of quantum mechanics – that is, the smallest a particle is, the less certain you can be at the same time about its position and its momentum. Another related analogy with quantum mechanics is the proof-program duality, which looks very much like the wave-particle duality. I believe those striking similarities might one day give rise to a unifying theory of computer science and quantum mechanics.