Move the Cheese
Report on the recent Coding, Complexity, and Sparsity Workshop

Martin Strauss and Anna Gilbert and Atri Rudra are the organizers of the just-held Coding, Complexity, and Sparsity Workshop. The theme of sparsity is working with objects that in their “vanilla” representation have many parts that are zero, redundant, or otherwise trivial. For instance, you might have an 

Today Ken and I want to thank them for having us attend this fun meeting.
The workshop was held this past Monday through Wednesday in Ann Arbor at the University of Michigan. The speakers, with perhaps one exception, were great, knowledgeable, and gave great talks. Okay the exception is me—I cannot comment on my talk.
There was another special talk, which was terrific; and one I can comment on without reservation. Ken helped fill in a gap in the program, since someone had to cancel. Even though his talk started at almost five o’clock, after a long day of talks, it was clearly one of the best. He spoke on his work on cheating in chess. There is something engaging about his area. It combines a game that many of us love, with human drama—cheating—and also includes lots of computing and math issues. See our recent discussion of chess cheating. Ken thanks the organizers for the opportunity.
Themes
In the famous motivational book by Spencer Johnson, Who Moved My Cheese?, the main topic is about change in the workplace. Well, we who do research face lots of change too.
The book is summarized as follows:
- Change Happens
- They Keep Moving The Cheese
- Anticipate Change
- Get Ready For The Cheese To Move
- Monitor Change
- Smell The Cheese Often So You Know When It Is Getting Old
- Adapt To Change Quickly
- The Quicker You Let Go Of Old Cheese, The Sooner You Can Enjoy New Cheese
- Change
- Move With The Cheese
- Enjoy Change!
- Savor The Adventure And Enjoy The Taste Of New Cheese!
- Be Ready To Change Quickly And Enjoy It Again
- They Keep Moving The Cheese.
Okay how does this connection to the workshop, and to research? Well the area you do research in is like the cheese. What I noticed during the workshop was that the cheese—I mean the research topics—were often old topics that had been moved. I think it is fine to keep working on the same problem, but often the research that is exciting is the result of moving the cheese.
Let me give three examples of this. Let me also in advance say that just about everyone could be used as examples of this idea: change the topic, or move the cheese. So please do not be upset if I do not use your favorite area as an example, and Ken and I hope to discuss others in the future.
Three Examples





Where to begin learning a field, given that it will move on you? The workshop has the great idea of giving tutorials in some selected areas at the beginning. Here are summaries of the three tutorials this year, with my comments after the speakers’ abstracts. The first two in fact were given by current graduate students.
The Tutorials
Mary Wootters: High dimensional probability in theoretical computer science
Recently, techniques from probability in Banach spaces and geometric functional analysis have found applications in compressed sensing, coding theory, and other areas of theoretical computer science. In this tutorial, I will go over some useful tricks and techniques, with examples.
At the start she said that she would “lie” during the tutorial—if this were a logic seminar we would have asked if she were lying about that statement. Her goal is to help improve the union bound. Recall this is the simple, but amazingly useful observation: The probability of the conjunction of events 
![\displaystyle \mathsf{Pr}[E_1] + \cdots + \mathsf{Pr}[E_m].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathsf%7BPr%7D%5BE_1%5D+%2B+%5Ccdots+%2B+%5Cmathsf%7BPr%7D%5BE_m%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
One method is called symmetrization. She showed how to replace a sum

by

for suitably-chosen 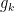
She then switched to union bounds over geometric objects. These have extra structure which is possible to exploit. One especially is their covering number. For a spatial set 

A key idea is that of closeness for a set. Say that 


Eric Price: A Faster Fourier Transform On Sparse Data
The goal of “stable sparse recovery” or “compressive sensing” is to recover a
-sparse approximation
of a vector
in
from
linear measurements of
time. In this talk I will survey the results in the area and describe general techniques used in solving them.
The cost of computing the Fourier Transform is the main topic. And it is possible to reduce it from 
There are lots of previous results when the signals are very sparse. New results for the case of exact 
To give an idea of how this works, let’s look at the case when the signal is 

Just take the first two terms 



is 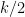

is linear.
The rest of talk was a survey at high level of compressed sensing—see the slides. One big difference here is that often the size of sample is more important than the speed of the algorithm. Think about MRIs: the samples require the huge machine to move, and given that computers are so fast, it is way more important to minimize the number of samples than the computing time.
A final problem was to consider some unknown sparse vector 

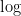


This was a fun and well-presented talk on results that combine great theory with potentially a variety of practical applications.
Swastik Kopparty: Polynomials and Complexity Theory
This tutorial will discuss some of the amazing and unexpected applications of polynomials in complexity theory.
This tutorial gave several applications of polynomials over a finite field. He first stated the basic properties of polynomials—for example, two polynomials of degree 
One application is the classic idea of secret sharing due to Adi Shamir. Example: I have a secret bit and want to give it to ten friends so that any two can reconstruct the secret, but no one can learn it alone. Let 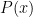



His last application was to lower bounds on constant depth circuits. The main class is 

This was a clear and neat talk. The only issue I take is that there are many many applications of polynomials that he did not even mention. Of course to do justice to even some 
Open Problems
The obvious suggestion is: when doing research, keep checking your problem, that is, your cheese. You may wish to move it and see if that leads to some new ideas.
Trackbacks
- From Proofs to Prime Numbers: Math Blogs on WordPress.com — Blog — WordPress.com
- From Proofs to Prime Numbers: Math Blogs on WordPress.com | Electrician Richardson
- math | electericity
- Math Blog Snippet | the Cyclic Grizzly
- Math Blog and how to write math equations using LaTeX $latex…$ | Adonis Diaries


“Who Moved My Cheese?” and the subsequent seminars were close to being the most stupid corporate concept to have passed through our world. Hopefully the books will all be burned along with the authors and enthusiasts, and replaced with your examples. Like building a church on the foundation of a pagan temple (ever been to Cuzco?)
I agree.
Unfortunately the whole world economy is run by exploiting the mediocres, by those who are in power.
Dear Dick and Ken,
1. Am I moving the cheese of community TCS with my papers (http://www.andrebarbosa.eti.br/The_Cook-Levin_Theorem_is_False.pdf, http://arxiv.org/ftp/arxiv/papers/0907/0907.3965.pdf, http://www.andrebarbosa.eti.br/P_different_RP_Proof_Eng.pdf, http://www.andrebarbosa.eti.br/NP_is_not_in_P-Poly_Proof_Eng.pdf)?
2. Should hidden assumptions within the TCS continue occult , as those consider that the exponents of the polynomials (upon traditional classes P and NP) are always known and given?
3. Why computer scientists are so resistant to ideas so simple, ingenious and effective?
Dick Lipton’s three examples of “cheese-moving problems” each are eminently practical; when we look for dual problems that reflect fundamental open problems, we are led (for example) to the Hodge Conjecture, in which
It’s terrific to see to many urgent practical problems in engineering that are intimately linked to open problems in fundamental mathematics.
There is a nice quotation by David Mumford to this effect, an article Curves and their Jacobians (1975, that regrettably I cannot find on-line):
That is an adventure in which every 21st century STEM researcher can participate!
Yet another cheese-moving essay is this week’s Huffington Post feature “The Coming Dark Age For Science In America.
Not much in the article will surprise any academic or industrial STEM researcher (the article’s subtitle is “Sequestration Ushers In A Dark Age For Science”). What *WAS* surprising (to me) was the
14,00015,00016,000++ comments. Those are numbers that every politician understands!It’s evident (to everyone) that the American STEM community’s “cheese” has moved, and it’s evident too that the recent budget sequestration is (as it seems to me) not the proximate cause, but rather an direct effect, of that cheese-move.
So Dick and Ken are asking a mighty topical, mighty broad, mighty urgent question (as it seems to me), which is: Where’s the new cheese?
In regard to cheese-moving, since yesterday we have:
• 6,000+ new comments on Huffingtonpost (22,530 total)
• 1 new comment on GLL (2 total)
As usual in science, this large dimensionless ratio (6000/1) requires explanation:
Conjectures
▸ Senior complexity theorists are satisfied with their cheese?
▸ Junior complexity theorists are shy to speak-up in regard to cheese?
▸ The STEM community perceives CT as irrelevant to cheese?
▸ Institutions are focused on protecting their present cheese?
▸ No-one has good ideas in regard to finding new cheese?
▸ Everyone’s worried that they may not like the taste of new cheese?
▸ All of the above, and more?
The distraction on my side is cheesy doings at what used to be spelled “chesse” :-(!
That, and their iceberg is melting!
The final tally: 24,317 comments on HuffPost’s The Coming Dark Age For Science In America.
It is striking (and dismaying?) that research-grade STEM weblogs typically attract a dozen or two (too-often snarky) comments. The 1000-fold greater out-pouring of heartfelt comments on HuffPost suggests that the public is vastly hungry for better STEM narratives.
Ken, as a chess-fan I appreciate what perhaps many GLL readers perhaps will be interested to know, namely that you serve on the FIDE anti-cheating committee.
Can we hope for a GLL column on this topic, following the Tromsø Knockout Chess Tournament (that is now underway)?
Please let me say that your research in this area is (as it seems to me) crucial to the future of chess, and is greatly admired by many (including me). A GLL column(s) on this topic would be very welcome!