Win Five Hundred Or A Million Dollars, By Recursion?
The Erdős discrepancy problem and more

|
| source — in memoriam |
Raymond Redheffer was an American mathematician. He worked for his PhD under Norman Levinson, who was famous for his work on the Riemann Hypothesis. Redheffer spent his whole career at UCLA and was a great teacher—see this for more details. Redheffer wrote the mathematical content for the IBM-sponsored 50-foot poster “Men of Modern Mathematics,” which IBM last year released as a free I-Pad app.
Today Ken and I wish to talk about a problem that Gil Kalai spoke last month at Tech, and suggest an approach to solving the problem that draws on a matrix studied by Redheffer.
Unfortunately I was not able to hear Gil’s talk since I was at the RSA annual conference on security—see here. But the talk featured an old problem of Paul Erdős that is one of those terrible problems: easy to state, easy to think about, impossible to make progress on.
I have two things to say about this classic problem. First, it has a nice statement as a question about matrices. Second, it may be related to the Riemann Hypothesis. Erdős was known for offering monetary rewards up to $1,000 for problems he liked, and EDP itself carried a reward of $500. The Riemann Hypothesis, however, is one of the million-dollar Clay Millennium Prize Problems.
The Problem
The Erdős Discrepancy Problem (EDP) is ultimately about how strongly the class of arithmetical progressions suffices as a lens for viewing random behaviors in infinite sequences. Let 

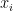





Of course this is true for any “random” sequence with 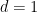
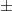


but then taking 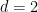
There do exist sequences that keep all the sums lower than what happens for random sequences. An elementary way is to define

where 




A Linear Algebra Approach
We offer another way to view the famous EDP, and wonder how widely it is known. Define the 
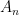
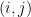




Then we have the following observation:
Theorem 1 The EDP is true—i.e., for every
and infinite vector
of
there are
and
so that
(where we call the sum
)—if and only if for every such
and
so that
Here
is the vector of
.


The key to the proof of this is quite simple. Note that the 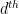


The sup-norm, 
The proof itself requires just some care with bounds and indexing. For the forward direction, given 









Hence the norm assertion is exactly the same as the EDP. What Ken and I find interesting is that the matrix
Some Ideas
The above connection may be well known, but it is new to me. In any event it suggests a number of possible approaches to proving EDP. Linear algebra has solved many problems in the past that did not immediately seem to be about linear algebra. This is the hope—that we may be able to exploit linear algebra to solve the EDP. Or at least make some small progress.
The matrix 



The matrices 
![{[1,\dots,n/2]}](https://s0.wp.com/latex.php?latex=%7B%5B1%2C%5Cdots%2Cn%2F2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
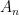
EDP And The Riemann Hypothesis
Ray Redheffer seems to have understood this, because his matrix is the same as 

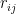



Actually what Redheffer did, in his source paper published in 1977, was fill the first column with variables 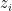


-
if
-
if
-
if
Two years ago, we covered the relationship between 

In particular, the determinant of the Redheffer matrix—with all 

Does
grow as if it were a “random” sum, for instance as
for any
?

This is equivalent to the Riemann Hypothesis. This connection is noted in terms of the related Liouville lambda function on the EDP PolyMath page at the end of this section. We wonder how far it can be widened.
A Further Idea
Let 

The difference from 
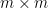


and 


We note that 



This is of the form 

Putting this all together yields that

But this means that

provided 
The key question is, can we use this to get a bound on the Mertens function, or to get some congruence results? The obvious idea that 

Open Problems
Does the linear algebra approach to EDP seem useful? Also the Redheffer matrix is “almost” what we need to understand to solve EDP. Does this suggest a connection between EDP and the Riemann Hypothesis? Could that explain the reason EDP is so hard?
[fixed base-3 sequence to make it multiplicative rather than “anti”]


We used a linear algebra approach in this recent paper: http://www.tandfonline.com/doi/abs/10.1080/10586458.2013.746616 .
Typo: the multiplicative sequence example should be $x_i = (-1)^{b_3(i)-1}$.
True for conformance to the source, but does it matter?
Without the -1 in the exponent the math doesn’t work to me: take x_{10}. The lowest order digit of 10 in base 3 is 1, so according to your definition x_{10} is (-1)^1 = -1. But still according to you definition x_{5} is (-1)^2 = 1 and x_{2} is (-1)^2 = 1.
What you suggest is actually a linear _programming_ approach, right? Maybe it would be more eye-catching if you called it like that. 🙂 Is the stronger version of EDP where m and d must be a powers of 2 disproved?
As the first impression your version of EDP seems like a question about (right) eigenvector of with largest eigenvalue. In particular, whether it can be partitioned (I mean classical NP-complete partition problem). If it cannot than EDP is true, otherwise it may be a bit more complicated. As usual I can be mistaken.
with largest eigenvalue. In particular, whether it can be partitioned (I mean classical NP-complete partition problem). If it cannot than EDP is true, otherwise it may be a bit more complicated. As usual I can be mistaken.
other typo? in your 1st formula dont you mean and not
and not 
Not a typo, it’s
also, bernard chazelle has a great online book on the discrepancy method, ~500p, 1999
This is an interesting post, I was not aware of the Redheffer matrix and the connection to the Mertens function.
Some notes:
Your observation (Thm 1) is very well known in combinatorial discrepancy theory. The strongest tools we have in giving discrepancy lower bounds do rely on linear algebra. For example an easy lower bound on discrepancy is to :
:  . However, this method is hopeless for EDP, because it would also work against
. However, this method is hopeless for EDP, because it would also work against  which are zero on a constant fraction of coordinates, and there exist such x that have discrepancy a constant. This starts to give an intuition why EDP is so hard!
which are zero on a constant fraction of coordinates, and there exist such x that have discrepancy a constant. This starts to give an intuition why EDP is so hard!
On the other hand, a famous theorem of Klaus Roth asserts that the discrepancy for arbitrary arithmetic progressions (i.e. ones that do not need to start at 0) is . One proof (I think the original one, but there is a nice presentation both in Chazelle’s and Matousek’s books on discrepancy) does use the smallest singular value observation. However, when we have arbitrary APs, we can reduce the problem to evaluating the eigenvalues of circulant matrices, and that’s relatively easy with a bit of elementary Fourier analysis.
. One proof (I think the original one, but there is a nice presentation both in Chazelle’s and Matousek’s books on discrepancy) does use the smallest singular value observation. However, when we have arbitrary APs, we can reduce the problem to evaluating the eigenvalues of circulant matrices, and that’s relatively easy with a bit of elementary Fourier analysis.
Another proof of Roth’s theorem is due to Lovasz, and it lower bounds the value of the natural SDP relaxation of discrepancy. The SDP relaxation is stronger than the singular value relaxation, and there is hope it might be strong enough to bypass the nasty issue of the existence of x that are 0 on a constant fraction of coordinates. I.e., unlike the singular value relaxation, it might have super constant value for EDP. I would conjecture that the value of the SDP relaxation for EDP is , with very little evidence to show for it. A lot of effort in the final parts of polymath 5 went towards finding a suitable relaxation of the SDP relaxation that is amenable to analysis. In particular, there are several threads that explore the approach: look at the SDP dual, assume special properties of a dual solution, look for a dual solution with such properties. Of course, by (weak) convex duality, a dual solution certifies a lower bound.
, with very little evidence to show for it. A lot of effort in the final parts of polymath 5 went towards finding a suitable relaxation of the SDP relaxation that is amenable to analysis. In particular, there are several threads that explore the approach: look at the SDP dual, assume special properties of a dual solution, look for a dual solution with such properties. Of course, by (weak) convex duality, a dual solution certifies a lower bound.
Finally, let me get back briefly to determinants. If we strengthen discrepancy to hereditary discrepancy (for EDP this means first fix a subset S of the integers and then look at the discrepancy of arithmetic progressions intersected with S), then lower bounds hereditary discrepancy (this is a beautiful theorem of Lovasz, Spencer, and Vesztergombi). But it seems that this is too weak again:
lower bounds hereditary discrepancy (this is a beautiful theorem of Lovasz, Spencer, and Vesztergombi). But it seems that this is too weak again:  is basically 1. However, there is a way to cleverly take submatrices of
is basically 1. However, there is a way to cleverly take submatrices of  and successfully use the determinant lower bound to give very strong lower for hereditary discrepancy in the EDP setting: see this writeup by myself and Kunal Talwar (sorry for the shameless plug): http://paul.rutgers.edu/~anikolov/Files/EDP.pdf
and successfully use the determinant lower bound to give very strong lower for hereditary discrepancy in the EDP setting: see this writeup by myself and Kunal Talwar (sorry for the shameless plug): http://paul.rutgers.edu/~anikolov/Files/EDP.pdf
Thanks for great comment.
The plug is cool…I was not aware of this work and it looks quite interesting.
dick lipton
PS: The EDP can work with the Redheffer matrix and not the divisor matrix. Can we exploit this?
Thank you, Dick!
I think you are right that for EDP it’s enough to look at the Redheffer matrix.
Let me define to be the matrix that consists of the Redheffer matrices
to be the matrix that consists of the Redheffer matrices  stacked on top of each other (the smaller matrices are filled with zeros so that the dimensions match). I think the way to go is to give a lower bound by exhibiting a dual SDP solution for
stacked on top of each other (the smaller matrices are filled with zeros so that the dimensions match). I think the way to go is to give a lower bound by exhibiting a dual SDP solution for  . That amounts to finding positive diagonal matrices
. That amounts to finding positive diagonal matrices  and
and  such that
such that  and
and  is a PSD matrix, where $d$ is the discrepancy lower bound. We’d like $d = \omega(1)$, but I think even $d = 3$ would be a new result.
is a PSD matrix, where $d$ is the discrepancy lower bound. We’d like $d = \omega(1)$, but I think even $d = 3$ would be a new result.
Regarding the Riemann hypothesis, one thing that I would be happy to see is a blog detailed post and discussion of the state of the art and various approaches similar to Tao’s post and subsequent discussion on the Navier Stokes equation.
I heard recently an interesting talk on Redheffer matrix by John Thompson based on this paper
http://arxiv.org/pdf/1101.0767v1.pdf that may interest you.
maybe a long shot but this reminds me a little of the hurst coefficient