Do Gaps Between Primes Affect RSA Keys?
A possible contributing factor to the recent discovery of weaknesses in RSA keys en-masse

Arjen Lenstra is one of the top computational number theorists in the world, especially on the state-of-the-art in integer factoring. For example, he helped create the best general factorization method known to date—the number field sieve—see here for a previous discussion. Also he was one of the authors of the great paper that introduced the LLL lattice algorithm, which was joint work with one of his brothers, Hendrik Lenstra, and also with László Lovász.
Today we wish to add some potential considerations to the discussion of Lenstra’s recent paper on why RSA public keys deployed in practice are sometimes breakable. Ken and I do not know whether they actually apply, but there are some reasonable questions to ask, and a tie-in to general problems in number theory.
The paper is joint work with James Hughes, Maxime Augie, Joppe Bos, Thorsten Kleinjung, and Christophe Wachter, and bears the title, “Ron was wrong, Whit was right.” Here Ron refers to Ron Rivest and Whit refers to Whitfield Diffie. Rivest is the ‘R’ in RSA, of course, and Diffie is the Diffie in the Diffie-Hellman protocol. The former uses two primes and the latter uses one prime. The message is that crypto-systems that use one prime may be better than ones that use two primes—because the latter allow two users unwittingly to share one prime in a way that endangers both their systems. Here is how.
The Factoring Idea
Perhaps there is one fundamental idea in factoring, an idea that goes back at least to Pierre de Fermat. Suppose that 
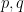




The good news is if you can find such an 
The bad news is, where does 


and then use 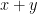
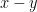
In any event, the search for values of
Attacks on RSA
Let’s turn to the recent attack on RSA. Recall RSA relies on having an
Lenstra’s paper used a clever idea, an idea that probably has been around, but still a clever idea: instead of working hard to try and find an 

The empirical result found in the paper is that using these
Factoring one 1024-bit RSA modulus would be historic. Factoring 12,720 such moduli is a statistic.
The original quotation is, “When one person dies, it is a tragedy. When a million die, it is a statistic.” According to this wiki the quotation came from a 1981 Russian biography of Stalin that was used by an American historian, but it probably originates in a 1932 essay on the nature of jokes in France.
Attacks on Lenstra
Lenstra put two extra charges into his broadside: having the story appear in the New York Times on the same Valentine’s Day as the paper’s e-print date, and the title “Ron was wrong, Whit was right.” A great title to get noticed, but not the best for search engines in the future—jump forward ten years and imagine saying, “I recall a paper that showed a problem with RSA, I forget the title.” Right afterward there were attacks not on the results, but on their meaning and on the bearer of the news—Lenstra. I personally find this pushback to be unscientific and unwarranted.
The paper shows that a small fraction of the RSA keys are easy to break, 0.2%, while 99.8% are okay. But Lenstra and his team have been attacked that this observation is picayune—if only a small percent fail, what is the concern? This line strikes me as unfair, unreasonable, and wrong: cryptography here is predicated on the chance of total failure being negligible. I regard the following statement as wrongheaded insofar as it is seen to disclaim responsibility for considerations that should be on RSA’s watch as a security firm:
RSA said Thursday in a statement. “Our analysis confirms to us that the data does not point to a flaw in the algorithm, but instead points to the importance of proper implementation, especially regarding the exploding number of embedded devices that are connected to the Internet today.”
One Prime vs. Two Primes
The nub of the argument is whether Lenstra’s contention that relying on two primes is innately more dangerous than one is fair. There is no obvious counterpart to the GCD trick for systems that use one prime. Note that two primes are required for RSA, and this is why the GCD method could even work.
Clearly the facts speak for themselves: many RSA keys were broken. I do not accept that “only” a small percent were compromised. This reminds of the scene in Dr. Strangelove where a US bomber has ignored orders to return to base and is on the way to attack the USSR and likely start WW III:
President Merkin Muffley: General Turgidson! When you instituted the human reliability tests, you *assured* me there was *no* possibility of such a thing *ever* occurring!General "Buck" Turgidson: Well, I, uh, don't think it's quite fair to condemn a whole program because of a single slip-up, sir.
In the RSA case, how about tens of thousands of “slip-ups”?
The argument then moves on to ask, what is the root cause, and what can be done to avoid these problems? The paper does not identify a main culprit, and the answers might truly emerge only from sifting how millions of RSA certificates were created—acts of checking that the authors disclaim for reasons of both security and time-intensiveness. We don’t have a main culprit either, but rather an observation about the landscape.
One Way (Not) to Pick Primes
We wish to draw attention to one aspect of generating primes, and ask whether it may be interacting with more-salient problems found in the generation of keys, especially by smaller “consumer” devices. For more on the salient problems, see this excellent post by Nadia Heninger pointing to another in-depth study, this Y-Combinator thread, and this Secret Blogging Seminar note, among many good sources.
We make an educated guess that many implementers start with 



This strategy of picking a random place and then starting a search from that place yields extremely biased primes. Whether this matters may depend on implementation details discussed below, but potentially it could have three ramifications:
- It could explain some, if not all, the lost entropy in the key generation that Lenstra found.
- It could suggest a method that could break many more keys.
- Searching for primes with “extra” security properties, such as so-called safe primes and/or strong primes, could make the bias problem worse not better.
Why This Could Be Bad
To understand the bias, let’s recall an old problem from Martin Gardner’s first book of mathematical recreations from his Scientific American columns.
A young man reaches a subway platform at a random moment each Saturday afternoon. Brooklyn and Bronx trains arrive equally often—[each regularly] every 10 minutes. Yet on the average he goes to Brooklyn nine times out of ten. Why?
The answer is that while uptown trains to the Bronx may dutifully arrive on the :00, :10, thru :50 every hour, downtown trains to Brooklyn could be coming at :09, :19, …, :59. The downtown trains have a lead interval that is nine times as great, and hence captures nine times as many random moments of arrival.
The distribution of primes is much more uneven than that of the trains, and some primes may have lead intervals that are vastly larger than average. Call such primes leaders. By the Prime Number Theorem, the average density of primes between a given 


If the first prime 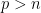
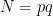
Of course saying “one-fifth” is a huge exaggeration. For sufficiently large 





Do Gaps in Primes Show Up?
We can do one quick calculation to argue the gap issue should not matter, even with the bigger gap values 




Of course such a pool is not observed in the Lenstra and Heninger-et-al. studies. Ironically, using more randomness, say 512 bits of randomness, with the above simple search strategy puts bias from multiple selection of leader primes on the table. However, as opined by numerous commenters on the above studies, we are evidently dealing with a problem of insufficient randomness and systematic bias, such as tending to use the same pseudo-random generators and seeds. Then does the bias toward leader primes show up?
In one sense, of course it should—completely apart from the issue of multiple selection, leader primes are more likely to be chosen by any form of the above loop with 
Are the distances to the nearest neighbors of the primes
caught in the studies significantly greater than the expectation of
? Same question for gaps to the nearest “strong” and/or “safe” prime.
As we said a positive answer may not mean much—we would expect it anyway—but perhaps the magnitude of the gaps may shed light on why certain 
One way to evade the literal problem of gaps is to use 



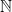

In any event, a safer solution that avoids the gap problem is easy to describe: generate a new random seed 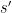


Open Problems
Does our question about gaps neighboring the primes
What happens to gaps between prime numbers under low-complexity re-orderings of 

Trackbacks
- Links 3 Mar « Pink Iguana
- Factoring RSA Moduli. Part II. « Windows On Theory
- Beyond Las Vegas And Monte Carlo Algorithms « Gödel’s Lost Letter and P=NP
- Short and Tweet « Gödel’s Lost Letter and P=NP
- Generating Random Primes | CL-UAT
- Leprechauns Will Find You | Gödel's Lost Letter and P=NP
- John and Alicia Nash, 1928,1933–2015 | Gödel's Lost Letter and P=NP
- Bletchley Park | Gödel's Lost Letter and P=NP
- Timing Leaks Everything | Gödel's Lost Letter and P=NP
- More Spectre and Meltdown « Pink Iguana
- Finding Coprime Pairs | Gödel's Lost Letter and P=NP
- P=NP: A Story | Gödel's Lost Letter and P=NP


Why is it the RSA company’s fault if other people implemented their algorithm improperly?
And why was Ron (not to mention his coauthors) “wrong” to define an algorithm for which incorrect implementation gives bad results? By this standard, every computer scientist is wrong. The paper is certainly interesting, but its title is exceedingly unscientific and unfair — much moreso than the critiques of the paper itself.
Agreed (Ken not “Pip” speaking) about the title, which Dick did criticize in the terms given.
On the matter of “fault” and “wrong” in both comments above, the phrase “on one’s watch” which we used does not entail either. As used in the US, it means the responsibility of oversight that a department head has for policies and subordinates—the ones who might be doing the actual wrong. We are saying that RSA Inc. has such responsibility for the mass deployment of its product, and should not make statements perceived as washing hands of it. In general manufacturing there is the related concept of total productive maintenance, where the assumed responsibility is treated not as burden but as opportunity.
Can you explain why your observation is related to one prime vs. two? It seems like any such weakness would show up just as readily in a protocol requiring a single prime, the only difference being that the problem would be much more obvious.
The problem is that the security of RSA relies on the difficulty of factoring the modulus. If two RSA moduli share a prime, then factoring them is trivial via computing the GCD. If an attacker can factor the modulus, the attacker wins.
Single prime based systems tend to be based on the difficulty of computing discrete logarithms (or some relaxation like the Diffie-Hellman problem). If two people happen to choose the same prime for a modulus, no harm is done since this does not make the presumed hard problem any easier. For poor random choices to make such systems insecure, the two people would need to choose the exact same modulus *and* private exponent. This is much much less likely, both because it involves two ‘collision’ instead of one, and because the exponent is typically chosen uniformly at random from some large range, and therefore should not suffer from any kind of selection bias of the sort suggested in this blog post.
This is a bit offtopic, but Lamé’s 1844 complexity analysis of Euclide’s algorithm is available here:
http://gallica.bnf.fr/ark:/12148/bpt6k2978z/f867
Witness how he begins his paper by deploring that standard textbooks on arithmetic give bounds linear in the numbers for which the gcd is computed, rather than their logarithm…
I think this is a very interesting paper, but the there are some misunderstanding about the results. The underlying issue the paper discovers is not really specific to RSA but applies to other cryptosystens as well. Second, 0.2% is not a very informative number.
Let me start with the second, more minor issue. The statistic of 0.2% is somewhat meaningless. I can create and post online tomorrow a billion certificates using 15 as a my RSA modulus. Would that make 99% of the RSA keys insecure?
The main issue is that a such a collision between a key produced by user A and a key produced by user B, whether of one factor or (as was even more likely) by both factors, could never happen unless both users were using a source of randomness with very low entropy. Now, if you use low entropy to generate your cryptographic keys then they will never be secure, no matter if you use RSA, Diffie-Hellman, or even private key systems such AES. It’s true that if you use the other systems, then although your key is not secure, an attacker might actually need to do some work to break it (i.e., he would possibly need to examine the code of the embedded device that generated the key, and the distribution of inputs to the entropy injection method). With a shared factor in an RSA modulus, two insecure users actually help an attacker to break both their keys without such efforts, and so they open themselves to a “drive by” attack. But the solution is *not* for these users to switch from RSA to a different cryptosystem, but to make sure they generate their keys with sufficient entropy.
Reminiscent of Benford’s law
http://en.wikipedia.org/wiki/Benford%27s_law
I tried to prove that the complexity classes P and UP are different, showing as final conclusion that it would be possible that the RSA algorithm might be secure. See the post “P versus UP” at:
http://the-point-of-view-of-frank.blogspot.com/
This is the best idea about integer factorization, written here is to let more people know and participate.
A New Way of the integer factorization
1+2+3+4+……+k=Ny,(k<N/2),"k" and "y" are unknown integer,"N" is known integer.
How do I know "k" and "y"?
"P" is a factor of "N",GCD(k,N)=P.
Two Special Presentation:
N=5287
1+2+3+…k=Ny
Using the dichotomy
1+2+3+…k=Nrm
"r" are parameter(1;1.25;1.5;1.75;2;2.25;2.5;2.75;3;3.25;3.5;3.75)
"m" is Square
(K^2+k)/(2*4)=5287*1.75 k=271.5629(Error)
(K^2+k)/(2*16)=5287*1.75 k=543.6252(Error)
(K^2+k)/(2*64)=5287*1.75 k=1087.7500(Error)
(K^2+k)/(2*256)=5287*1.75 k=2176(OK)
K=2176,y=448
GCD(2176,5287)=17
5287=17*311
N=13717421
1+2+3+…+k=13717421y
K=4689099,y=801450
GCD(4689099,13717421)=3803
13717421=3803*3607
The idea may be a more simple way faster than Fermat's factorization method(x^2-N=y^2)!
True gold fears fire, you can test 1+2+3+…+k=Ny(k<N/2).
More details of the process in my G+ and BLOG.
Reblogged this on HAk23 and commented:
Very Interesting…