Complexity as Enabler
How to be a good cop on the problem-solving beat

Guy Blelloch is best known for his seminal work on parallel computing; if you need advice on parallelism he is the one to ask. Not surprisingly, he is a strong advocate of parallel programming. See his essay, “Is Parallel Programming Hard?” Spoiler alert: he argues that it is not.
Today we wish to talk about complexity theory as an enabler of problem solving, rather than a disabler when a problem is proved hard for 
Blelloch’s approach emphasizes how parallel structure emerges from specific problems, rather than focusing on control in parallel machine systems. The algorithms realizing this structure are informed by computational complexity theory. For instance, the “scan programs” in the book of his Ph.D. thesis are influenced by theorems relating vector machine models to the circuit classes of the NC hierarchy.
Blelloch has taught a course at Carnegie Mellon titled “Algorithms in the Real World” for many years. This covers classic algorithms in text compression, string searching, computational biology, high-dimensional geometry, linear versus integer programming, cryptography, and others. Some of these areas are informed by complexity, such as
However, even with immediately practical tasks like computing Nash equilibria of games, which as we noted in the last post is complete for a class called 
An Early Example
The earliest example I, Atri, know is the now famous pattern matching algorithm by Donald Knuth, James Morris, and Vaughan Pratt, which is included in Blelloch’s course. The point is that automata theory was used to design a linear time pattern matching algorithm. The following is quote is from the “Historical Remarks” section of the original paper:
“This was the first time in Knuth’s experience that automata theory had taught him how to solve a real programming problem better than he could solve it before.”
This whole section is worth reading to see how Knuth’s version of the algorithm was implicit in Stephen Cook’s linear time simulation of deterministic two-way pushdown automata (see this reference), which is clearly a complexity result. What could a “deterministic two-way pushdown automaton” have to do with a practical algorithm? Plenty.
Automata theory in itself is a treasure-trove of practical applications. For instance, the ubiquitous regular expressions and parsers in compilers, as they exist today, would not be around without automata theory.
Making Lower Bounds Your Friend
Probably the best known use of complexity as an enabler is to change the rules of the game: use the hardness results to foil the adversary. Cryptography has done this with great effect. There are other similar works, e.g, recently there has been work on designing elections that cannot be manipulated under complexity assumptions: see the survey by Piotr Faliszewski, Edith Hemaspaandra and Lane Hemaspaandra.
For the rest of the post, I’ll go back to the good cop role of complexity. A small bit of warning though: when I talk about practical applications below, I will not be talking about results that can find themselves in the complexity equivalent of the Algorithms in The Field Workshop—rather I will be content to talk about applications where one uses complexity to solve problems that have a clear and direct practical motivation. Given that I have ruled out cryptography, I hope you will allow me this luxury.
Applications of Complexity-Based Tools
Complexity theory has developed many tools that can and should find applications in practical areas where on the surface the two do not seem to have anything in common. Below the surface are beautiful connections that are being exploited can be developed further. Let me try to substantiate this with the following examples:

The particular version of the compressed sensing problem is to design a matrix 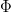




Here 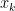




List decoding has also been applied to IP traceback of denial-of-service attacks, to games of guessing secrets, and to verifying truthful storage of client data. The last paper also applies Kolmogorov complexity—disclaimer: this paper is joint work with (my colleague Ram Sridhar’s student) Mohammad “Ifte” Husain, my colleague Steve Ko, and my student Steve Uurtamo.
Models
Complexity theory studies computation through the lens of various machine and program models. I believe that these models themselves can be a valuable export to practice. Probably the most widely exported model is that of communication complexity, which has found applications in diverse areas such as data stream algorithms and game theory. However, these are again used to prove lower bounds, on the bad-cop’s beat. Below are some examples I am aware of that prove positive results:
We created a model in which collisions become a cost akin to decision-tree queries as wireless devices detect them, thus measuring the efficiency of computing certain functions of data distributed over sensor nodes. Our first paper characterized the complexity of different functions in this new model. Then we ran experiments and showed in a follow-up paper that our algorithms improve over existing ones. So collisions are bad, but not always; sometimes you can make “collision-ade” out of them.
There is some encouraging recent news on this front. Eli-Ben Sasson and Eran Tomer are leading a project with Ohad Barta, Alessandro Chiesa, Daniel Genkin and Arnon Yogev funded by the European Community that is aimed at implementing PCPs for practical applications in security and verifiable computation. The project is still in its early stages, but hopefully it will allow us to think of PCPs as the fish that almost got away.
Open Problems
What other categories of complexity as an enabler can we collect? What are other applications of the above examples?
Ken and I (Dick) also wonder whether complexity theory got carried away with emphasis on classes—per our last post—and did not give enough to problems. Note that this parallels Guy Blelloch’s point insofar as most complexity classes were originally defined in terms of machines, rather than emerging directly from features of problems. Can complexity profit from such a shift in focus?
Ken and I, finally, thank Atri for this contribution. We invite others who have something they wish to say to contact us for a potential “guest” post. We do not pay much to the author of the post—actually about $2.56 less than Knuth would—but we hope that some of you may wish to do one.


Parallel computing turns out to be a natural way of constructing fast serial algorithms for parametric search algorithms, as was discovered by Megiddo. (In parametric search you take a problem like shortest path but instead of constant lengths you have lengths which are affine in some parameter T.) Somehow each parallel step enables the serial algorithm to make a “batch” out of several steps.Here is a link to a more detailed description: http://daveagp.wordpress.com/2011/07/01/parametric-search/
Didn’t complexity theory give us SAT, the queen of NP-complete problems? While NP-completeness seems like a “bad cop” aspect of complexity at first, today many NP problems are solved in practice by reducing them to SAT. Integer Linear Programming plays a similar role.
Hi Amir,
Great examples.
When I listed the examples, I was thinking about my planned seminar with Hung, where we’re looking for specific applications, preferably with theorems, so I’m probably missing other relevant example like yours.
BTW integer linear programming is cover in the Algorithms in the real world course.
When we view thermal noise as algorithmically-incompressible complexity, then we appreciate one of the many great lessons owed quantum information theory is the intuition that thermal noise is an enabler of efficient dynamical simulation.
That thermal noise (and its accompanying dissipation) makes simulation exponentially easier is true both classically (e.g. von Neumann viscosity for example) and quantum mechanically (see e.g. Plenio and Virmani’s arXiv:0810.4340). Moreover this principle is robust, in the sense that it is both formally provably for idealized dynamical systems and works well empirically for dynamical systems having real-world complexity.
Systems engineers especially are exceedingly fond of this ubiquitous complexity-enabling principle, since real-world systems invariably are bathed in thermal noise. As David Deutsch writes entertainingly in his new book The Beginning of Infinity: Explanations That Transform the World:
Broadly conceived, systems engineering seeks to predict and control the noisy universe that is outside of the physicists’ ultra-cold ultra-dark refrigerators … and recent advances in QIT now have given us fundamental reason to hope that the predictive aspect of this goal is efficiently achievable.
A key point is that the complexity-theoretic noise-enabling principle can be exploited both forwards and backwards, in the sense that separative transport mechanisms that increase entropy gobally can be reversed to create separative transport engines that diminish entropy locally; a classic textbook book that entertainingly surveys this key branch of engineering is J. Calvin Giddings’ Unified Separation Science (1991).