Organic Separations
A whole-earth catalog of separation notions, including “fooling”

Jack Lutz of Iowa State is a complexity theorist who is an extremely original thinker. He is most famous for his creative notions that make concepts from continuous spaces make sense in discrete settings. Foremost is his work on a generalization of Lebesgue measure to complexity classes.
Today Ken and I want to talk about a recent paper on fooling formulas.
I still recall first hearing about Lutz’s work. It seemed amazing that notions like measure could be extend in a meaningful manner to complexity classes, to make precise statements like
Almost all sets in complexity class X have property Y.
Jack’s work has branched from measure into fractal-dimension theory, and continues as an active area that is especially useful in core complexity theory. Here we see how it furnished one seedbed for issues of de-randomization, and suggests how to plow the adjacent field of “fooling” lower-complexity objects.
The Farm
The central problem in complexity theory is comparing our imagination with reality. On the imagination end we can invent an almost endless supply of complexity classes. A class is often, but not always, defined by limiting some resource: time, space, random bits, and so on. These can be used individually to define 

Things are even more involved. Some classes are defined by a protocol that can be as “simple” as 


Defining complexity classes is fun: take a little of this, some of that, and add a pinch of this, and you have a complexity class. New ones are still being defined.
Christos Papadimitriou once defined a class of functions called PPAD that is quite interesting, but it came to great prominence when Xi Chen and Xiaoti Deng proved that computing a Nash equilibrium for a 2-player game is complete for it.
The ability to define classes and be limited only by our imagination is cool. Of course there are two constraints. First, some classes are more important than others. The classes 

The second is that classes must be grounded in reality. As they are defined and created the obvious question arises: Is this class the same as a previously defined class? This is the essence of the 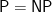
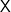

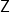
-
.
-
.
-
, where the latter is more obviously closed under union and intersection than the former.
To paraphrase George Orwell’s Animal Farm, the trouble is that “some classes are more equal than others”—or at least pretend to be equal to others. Separating out the pretence is needed to tell them apart. A word on “pretence:” no pretense is meant, this is based on Ken’s British training—you can replace “pretence” by “pretense” if you wish. Or not.
Extrinsic and Organic Separation
There seem to be two fundamental ways to tell whether two differently-defined mathematical objects 

When 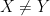
With the second way we learn something in terms of properties that speak directly to the idea of difference, generally without involving any kind of recursion. When the properties involve the ideas behind how
An Example From Mathematics
Parts of mathematics also struggle with proving that one object is not the same as another object. It is “obvious” that Euclidean space 


Here is a simple organic way of proving that 

The best proof for
To see that dimension is organic, note that the covering dimension of a topological space 


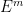
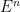
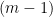
Examples for Complexity Classes
In complexity theory there are classes that we can prove different by both intrinsic and extrinsic methods. For example, suppose that you wish to prove that regular languages are not the same as context free languages (CFL’s). The classic extrinsic proof is to show that a language such as

is a CFL but not regular. An organic proof is to note that the regular languages are closed under intersection and CFLs are not. One way to show the latter is that if CFL’s were they closed under intersection, then the emptiness problem for CFLs would be undecidable. The point is that one can encode any computation into the intersection of two CFLs.
We think at some level these proofs are fundamentally different:
- One shows that regular languages are too weak to contain all CFLs.
- The other shows that CFLs are too powerful to equal the regular languages.
Does this suggest any ideas on how possibly to separate 


The technical-minded may note that every organic proof can be re-phrased as equality leading to a contradiction, which we allowed as “extrinsic,” and may prefer the issue be framed as whether or not a class separation is constructive in the sense of showing an explicit language in one class and not the other. However, this misses the emphasis on properties—ones that may not be obvious but that deepen understanding once their connection to the definitions is perceived.
Lutz’s Methods
The impact of Jack Lutz’s work is that he provided several new farms for organic properties of complexity classes. The main one is his original notion of resource-bounded measure, and its later companion is, yes, a resource-bounded notion of dimension. For example, he defined the following property:
Class
has poly-time measure zero in class
.
Note that if 

However, the point is that the property comes first. Lutz and his co-authors showed that his hypothesis that 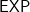

Note that the hypothesis being false—i.e., 
The point is that the organic hypothesis perhaps provides a more interesting dichotomy than the extrinsic ideas of 
Fooling
Another organic way to tell two complexity classes apart is to show that one can be “fooled” more easier than the other. By fool we mean that there is a pseudo-random source that one class thinks is essentially uniformly random and another thinks is not.
Andrej Bogdanov, Periklis Papakonstantinou, and Andrew Wan (BPW), in their paper to appear at FOCS 2011, give an explicit construction of a pseudorandom generator for read-once formulas whose inputs can be read in arbitrary order. For formulas in 

See their paper for details—it is a clever use of error correcting codes. It is not yet available to the public; they have sent me, Dick, a copy, and I hope they will post a version soon.
Fooling via Nisan?
BPW say in their paper:
So why shouldn’t Noam Nisan’s pseudorandom generator for logarithmic space also apply to read-once formulas? The answer has to do with the ordering of the inputs. Nisan’s pseudorandom generator fools branching programs that read their inputs obliviously and in a fixed order. It is not known whether Nisan’s pseudorandom generator fools read-once formulas.
We believe that for restricted formulas this is possible.
Let 
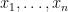





Then we claim—we think we can prove—that Nisan’s logspace generator generates 
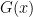
Open Problems
Does the above logspace method work? Are there ways to use the fact that Noam Nisan’s generator fools logspace, but ostensibly not polynomial time, to get some separation result?
What other properties besides resource-bounded measure, dimension, and fooling might make for better dichotomies?
[fixed name typo]


I’m not entirely sure, but I think this might follow (for l = polylog n) from the results in the paper: “How strong is nisan’s pseudorandom generator” (http://www.cs.toronto.edu/~papakons/pdfs/nisan_RNC.pdf)?
(they prove the result for non-uniform logspace with polylog-many swipes over the random bits, I’m not sure this can be used on the formulas you describe, as it would required balancing the formula)
Is there a class of problems that can be done in a polynomial number of steps without any limitation to the memory involved?
If so, what is known about this class of problems?
If at most a constant number of bits can be written per step, as on all flavors of Turing machines, then polynomial time entails polynomial space, so the class P already is what you say.
A random-access machine model, however, can be “permitted” to consider any arithmetic operation as a single step, even if the numbers involved have become very big, and to store arbitrarily big numbers in its registers. Such a machine is called an “MRAM” for “Multiplication RAM”. A classic result of Juris Hartmanis and Janos Simon is that polynomial time in this model equals polynomial space on a Turing machine, i.e. PSPACE.
Thus your question about “what can be done in polynomial time without any limitation to memory” turns out to have the answer, “whatever can be done in polynomial memory without any limitation to time”.
“Xi Chen”, not “Xi Cheng”
Fixed—thanks.
I have an algorithm that solves the Hamiltonian Problem in a polynomial number of steps. However, the amount of memory required is exponential.
Is this of any interest or value? Or are there many such algorithms known? If so, where can I can I find them?
[Superseded by next comment. FYI, moderation occurs only one’s first comment, except in circumstances we do not understand. I Quick-Edited this one rather than delete it, to avoid said circumstances. KWR]
Moderator, please replace my prior comments by these:
Mr. Kohn, the amount of time (number of steps) required by a standard DTM (program computer or algorithm) couldn’t be less than the amount of memory (space) required by it, since read/write a new tape cell (or position into memory, register, etc.) take at least one step. The converse can occur because the space can be reutilized, whereas the time not.
“Polynomial number of steps” with “exponential memory” – that’s not possible.
Dear Dick and Ken. Dear Ladies and Gentlemen. Would anyone care explaining the ignorance to my approach? I’m trying to follow Dick advise, and make it as simple as possible, no one reads it. I cannot believe that either one of you, or Tim Gowers, or many others could not understand what I’m saying. It would take half hour for you sitting with paper and pencil to figure it out. The only hypothesis I have is that my writing is connected to P=NP problem, and is written in not acceptable technical form. The another half hour (+ technical details) of thinking gives you the algorithm for max-cut and partition problems with space, and
space, and  time requirements. I’m implementing this algorithm, but have feeling that it is going to get the same amount of attention, may be because of its simplicity. It does not even need semi-definite program. The same can be done for 3-SAT (without reduction to NAE-SAT and max-cut) with complexity
time requirements. I’m implementing this algorithm, but have feeling that it is going to get the same amount of attention, may be because of its simplicity. It does not even need semi-definite program. The same can be done for 3-SAT (without reduction to NAE-SAT and max-cut) with complexity  in space, and
in space, and  in time (that is more complicated and requires more thinking).
in time (that is more complicated and requires more thinking).
To put all point on i, I understand that I’m not the target audience for Clay prize, and admit it. I just do not see how to break the “wall of refusal”. I’m ready to follow any advice, except for “learn math and make it technically correct” – it will take galactic polynomial time, there should be shorter solution. The polymath approach does not work here, unless Gowers, Tao or Kalai are running the project.
Sincerely yours,
Crackpot Trisector
(the person going against common believes)
“I’m ready to follow any advice, except for ‘learn math and make it technically correct'”. Then my advice is to offer money, because you can’t expect someone to read for free your unfinished work that even you don’t seem confident in. Also, as to style, please see #6, 8 here: http://www.scottaaronson.com/blog/?p=304
Apologies, I posted before I saw your 6:36 post below. That comment is actually much better written.
I would be skeptical that this approach is powerful enough to show P=NP. If you want to pursue it, I would start by feeding it some known difficult instances of an NP problem. If the algorithm seems to scale, maybe there is something to it… though like I said, I would be skeptical that this will scale up.
OK, we can give it a try. Given, the contradiction of #6 and #8 in Scott blog, and the requirements that for P=NP there is should be no details left, and also, that covering standard material was commented as much better written, the paper would need detailed account for standard material as well. Concentrating on the issue of P=NP, it will consist of 2 or 3 parts – (1) the reduction of max-cut and partition problem into unconstrained quartic optimization problem, showing polynomial gap between partitioned and non-partitioned multisets for partition problem, and polynomial gap between the optimal value for max-cut, and the next sub-optimal cut, along the line presented in my arxive writings (see P vs NP page entry 63) (2) real algebraic geometry overview for sum-of-squares representation of polynomial (It sufficient here go give it in the scope of NZ Shor (1987) and Parrilo thesis (2000) ), followed by the proof that resulting quartic polynomial is a sum of squares when non-negative. (see my blog) (3) Presenting optimized algorithm that does not require semi-definite program to find the global minimum of quartic polynomial of interest.
Given the different nature of the math in 3 parts, how much money you would take to formalize each part to publication level? I see it unfair, but that seems to be the shortest way to convey the message. Also, please, be realistic, I’m not a reach man.
I know, my blog is a mess. May be historical overview will help a bit. I apologize for long post. In no means this validate or invalidate the approach, but can give some context and navigation.
I was solving some quartic optimization problem related to principal component analysis, but much more complicated. It was non-linear with many local minima. I almost lost the hope, but suddenly found NZ Shor (1987) paper, and Parrilo thesis (2000), showing the approach to solve some polynomial optimization problems using semi-definite programming. It was applicable to my problem, and was solving low-dimensional instances. Due to memory limitation it could not solve the full range problem. But then, we had unrelated discussion for P vs NP, and I made an attempt to try this method on max-cut problem numerically. By the magic it was always finding correct value, and moreover was able to find the maximal cut.
The basic approach was to use the global minimum of polynomial , where
, where  is a connectivity matrix. It is weird way to write Lagrange multipliers. The first term is attracting minima to
is a connectivity matrix. It is weird way to write Lagrange multipliers. The first term is attracting minima to  , and the second term have correct order statistic in
, and the second term have correct order statistic in ![x_0= [\pm 1]^n](https://s0.wp.com/latex.php?latex=x_0%3D+%5B%5Cpm+1%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) . Local minima for small
. Local minima for small  should have deviation from
should have deviation from  proportional to
proportional to  , and the values proportional to
, and the values proportional to  which was what I observed in simulations.
which was what I observed in simulations.
I was exited, and wrote some text to archive.org (the short version is here), sent e-mails to you know whom. To my surprise I got responses. Moreover, some of the responses were deeper than my writing, with actually what I discovered later was correct objection. I did not understand the objections, and started blog on wordpress. With the help of Noah Stein (boring for him) from Parrilo group I understood the objection for the proof.
Brief version goes like this (with much better explanation accessible to non-experts in Parrilo thesis (2000) ). To find the global minimum of polynomial is equivalent to find the maximal
is equivalent to find the maximal  where
where  is still non-negative. This is hard problem. On the other hand, testing that the real polynomial is a sum of squares of other real polynomials (which is non-negative by construction) is easy. Suppose, that
is still non-negative. This is hard problem. On the other hand, testing that the real polynomial is a sum of squares of other real polynomials (which is non-negative by construction) is easy. Suppose, that  than we can write all monomials up to maximal degree of
than we can write all monomials up to maximal degree of  , which is
, which is  half of degree of
half of degree of  , as a column vector
, as a column vector  , and coefficients in front of monomials as a matrix
, and coefficients in front of monomials as a matrix  , with columns representing coefficients for
, with columns representing coefficients for  , then
, then  . Now,
. Now,  is positive semi-definite, and one have to find semi-definite matrix
is positive semi-definite, and one have to find semi-definite matrix  with a set of linear constraints, that this matrix is representing
with a set of linear constraints, that this matrix is representing  . To give an example on this constrains consider polynomial
. To give an example on this constrains consider polynomial  , then we need a set of monomials
, then we need a set of monomials ![[x^2, x, 1]](https://s0.wp.com/latex.php?latex=%5Bx%5E2%2C+x%2C+1%5D&bg=ffffff&fg=333333&s=0&c=20201002) , and matrix
, and matrix  has the following from
has the following from
The explicit counterexamples appeared much later with Motzkin and Robinson polynomials. In my writings there was no explicit proof that
On the other hand, my simulations, presented here and here (with matlab code), in all of many instances in low dimensions gave correct result. I was wondering why, and started to look at the literature. Almost immediately, I found Parrilo and Sturmfels work, where they did similar simulations with polynomials with degree of
with degree of  . They found that an all cases the minimum found by semidefinite program was within machine precision with the global minimum (I leave technical details here). Later, I found Murray Marshal book "Positive polynomials and sums of squares" (2008), where he stated that "Since
. They found that an all cases the minimum found by semidefinite program was within machine precision with the global minimum (I leave technical details here). Later, I found Murray Marshal book "Positive polynomials and sums of squares" (2008), where he stated that "Since  is an interior point of the cone of sum of squares 10.7.1 explains why minus infinity was never obtained as an output in these computations (but it does not explain the high degree of accuracy that was observed, which is still a bit of a mystery)", so the problem was open as of 2008. Then I found two more papers (here and here) stating explicit sufficient condition for the polynomial to be sum of squares in terms of its coefficients. Neither one was true for the polynomial
is an interior point of the cone of sum of squares 10.7.1 explains why minus infinity was never obtained as an output in these computations (but it does not explain the high degree of accuracy that was observed, which is still a bit of a mystery)", so the problem was open as of 2008. Then I found two more papers (here and here) stating explicit sufficient condition for the polynomial to be sum of squares in terms of its coefficients. Neither one was true for the polynomial  .
.
I started to look at eigenvectors of optimal in my simulations. They all had strange consistent structure. Namely, one of the eigenvector was very close to
in my simulations. They all had strange consistent structure. Namely, one of the eigenvector was very close to  , and the rest were orthogonal to it and had very small free constant. That was bothering me for a long time, until I came up with 2 simple tricks to show it. The core of the idea is in the following.
, and the rest were orthogonal to it and had very small free constant. That was bothering me for a long time, until I came up with 2 simple tricks to show it. The core of the idea is in the following.  can be represented by the full rank positive definite matrix
can be represented by the full rank positive definite matrix  in terms of quadratic monomials. The Cholesky decomposition of this matrix lead to full space basis. The second trick is Givens rotations preserve polynomial
in terms of quadratic monomials. The Cholesky decomposition of this matrix lead to full space basis. The second trick is Givens rotations preserve polynomial  . Then by using Givens rotations it is always possible to rotate basis that one of the axis is aligned with
. Then by using Givens rotations it is always possible to rotate basis that one of the axis is aligned with  represented in the same monomials.
represented in the same monomials.
Moreover, I have feeling that the full basis representation of highest degree terms in polynomial can give more precise tool at understanding what kind of polynomials can be represented as a sum of squares, and extension of this technique can settle down the mystery of Parrilo and Sturmfels simulations. One probably should add completion of squares, and discriminant of polynomial for resulting negative squared terms. I cannot tell anything here, and leave this topic for experts.
Also, I do not remember Dick posting about this line of research. Although, it seems remote from complexity, this is in my feeling the most powerful computation technique (I mean sum of squares).
Opps! Links are missing here. I made a copy of the post with links on my blog.