Testing Galactic Algorithms
How to get others to take a galactic algorithm seriously

Fred Sayward is not a theorist, but is an expert on software engineering, and in particular on testing programs for correctness.
Today I want to talk about the problem of getting someone to read a complex proof of a famous conjecture in complexity theory.
Often a claimed proof of such of conjecture consists of an algorithm that can be quite complex, and even worse have a terrible running time—the algorithm is galactic. Recall this means that the algorithm runs in a time bound that is huge, that the algorithm is unlikely to be usable in practice, and that it only runs in 
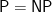
The puzzle that I have thought about is can we test a galactic algorithm, or must we only rely on the claimed proof that the algorithm is correct. Since often these claims are complex, messy arguments that could be wrong, what happens is that people refuse to read them. This means that the algorithms are not checked at all. They may be wrong, but it seems to me that there should be some way to test the algorithms. Testing cannot prove an algorithm correct, but it can show that an algorithm is incorrect; even better, it can show the author of the algorithm that the work is incorrect. As I pointed out before, Roger Brockett once said:
It’s hard to argue with a counter-example.
I have several ideas from software engineering that could help here. It may be possible at least to do limited testing of many galactic algorithms, by using some methods from software testing. I must add that I have had many interests over the years, and one was—is?—in the theory and practice of testing programs.
Testing
Years ago I was interested in program testing—not the theory of program testing—but actual methods for testing real programs. One method that I worked on, with Rich DeMillo and Tim Budd and others, was called program mutation. This method is based on a thesis of how people actually program and how they make mistakes—perhaps I will discuss it another day.
Fred Sayward worked for me when I was just staring out, in the mid 1970’s, when I was an assistant professor at Yale University. Alan Perlis was then the chair of the Computer Science Department at Yale, and Roger Schank was also on the faculty. Roger was more senior to me, and he had a well deserved reputation as a strong leader of the Yale AI group—I am being polite here. His word in that group was law, which was probably fair, since he created the group from nothing. He put Yale “on the map” in AI.
I had no money at the time to hire a full-time post-doc, but I did anyway. One day at a faculty meeting Perlis casually remarked that the department had enough money to hire a two-year post-doc. There was no further discussion, and we moved on to other matters.
I instantly began looking for a possible post-doc candidate for my project on program mutation. I quickly found Sayward, who was finishing his Ph.D. at Brown University. I had him visit, got letters of recommendation, and then approached Perlis with the suggestion that we hire Fred. Perlis had been to his talk, liked the letters, and quickly we had an offical letter off to Sayward offering him the job. He accepted. Done deal.
A few months later, Schank walked into Perlis’s office and told Alan that he had thought about the post-doc position. Schank began to explain to Perlis that he, Roger, had a couple of ideas of who he planned to hire to fill this position—of course the position was his. Perlis waved him off and said,
Lipton already has found a candidate and the position is gone.
I was not there, so all this is second-hand from Perlis, but I can imagine that Roger was not pleased—in his mind all resources of the department should have gone to build up the AI group.
There were two consequences of this: First, Fred turned out to be a great choice. For example, we together with DeMillo wrote a paper on program testing that has well over a thousand citations. The second was that while Roger was initially upset, after this event he acted differently toward me. He treated me with more respect—in general theory was not his type of research. I always thought that he respected someone who “beat” him at the resource game, since he was such a strong player. I probably should not do it again, but doing it once was cool.
Years later, after Roger had moved to Northwestern University, he tried hard to hire me. Perhaps I should have gone. Oh well.
Galactic Algorithms
Often new algorithms, as I stated, that claim to solve a hard open problem can run in “polynomial time,” but not really in feasible time. If an algorithm runs in worst-case time

then for any reasonable problem the algorithm is unlikely to be runnable.
Especially for claims of new factoring algorithms, new Graph Isomorphism (GI) algorithms, or new SAT algorithms, the inability to implement the algorithm is a serious problem. Simply said, if you claim a new factoring algorithm and break one of the open RSA challenge problems, there is no doubt that people will take you seriously. The same goes for GI and SAT.
I often hear from those who claim to have say a new factoring algorithm: “but my algorithm cannot run on real examples, so you must read my proof.” I claim this is too narrow a view, that there are ways to use testing to check even galactic algorithms.
Approaches
You have a galactic algorithm 



For example, a proof that some procedure eventually converges in 
Even if the convergence is slow, running the algorithm could still show that it seems to be converging. This can help us gain insights into the behavior of the algorithm.
If the procedure does not improve the metric the way you claim it does, that is a problem. However, if for all the examples you try the procedure improves the metric a tiny amount, then you have gained some real credibility.
Open Problems
Can these ideas be applied? Would you take a galactic algorithm more seriously if it was shown to work on non-trivial examples? Even in the partial way that we outline above?


Galactic polynomial time algorithms are *extremely* practical. The key observation is that polynomial time algorithms can be scaled horizontally in a cost-effective fashion. It’s expensive, but doable. Exponential algorithms are quite literally impossible to scale in any sense. This is what saves RSA right now, since it’s not possible for *anyone* to build a cluster big enough. However, if there were a polynomial-time factoring algorithm, even with a very high factor, that algorithm opens the door to building just such a cluster.
I think you are being overly optimistic, unless NC=P. Wikipedia page on P-completeness.
Exactly!
Scaling does not depend on polynomial or exponential. Theoretically even exponential time algporithms can be scaled if they allow parallelism, ie. extending NC classification where the sequential and parallel time complexities can differ only by a polymonial factor.
I meant the speed-up (or scaling) for the extended NC class would be near linear (within polylog factor) using polynomially many processors.
Dick, do you have in mind decision, function, search, or sampling problems? All of these arise frequently in practice. Frustratingly, in many branches of engineering the most common problems are sampling problems (e.g., simulating dynamical processes having a stochastic component, as in turbulent flow, finance, noisy quantum simulation, separative transport, game-playing, etc.), and yet the complexity theory literature relating to sampling problems can seem arcane to outsiders. Do technical terms like “NP witness” mean the same thing to complexity theorists as contrasted with engineers, when applied in the context of sampling problems as contrasted with decision and/or function problems? Don’t ask me! One reason I read weblogs like GLL is the hope someone will post meditations upon these topics that are thought-provoking and yet accessible to non-specialists.
The main reason for authors to do this is to save themselves from embarrassment, not to convince others. Counter-examples are convincing – but why stake any confidence in examples produced by the authors? Some NP-hard problems are notoriously easy on a large proportion of natural instances. TSP is one example that has been the basis for many claims of being able to solve NP-hard problems in polynomial time.
One example in particular comes to mind. Back in the mid-1980’s Swart claimed that a large lifted LP gave exact solutions for TSP. Because of the general easiness of the problem on typical instances, examples were not going to help. because this seemed to be a new idea people made serious efforts to disprove his claim – I recall that someone, maybe Bill Pulleyblank, found an error in the argument about the original lifted LP and Swart later added an extra subscript to his lifted LP (corresponding to something like a 4-lift ot 5-lift of the original TSP LP) by which point virtually all the people who had initially paid attention stopped bothering. However, Mihalis Yannakakis thought about things more deeply and in a STOC 88 paper showed that Swart’s entire approach was flawed. Yannakakis’ paper in turn was one inspiration for the Lovasz and Schrijver 1990 paper that introduced SDP lifting procedures.
Another class of special cases that would be interesting to try a proposed galactic algorithm on would be random examples, with various parameters. Some of these might be expected to be hard, but most of them should be easy. There is good reason to suppose that if your algorithm is correct, then it should work well on random examples with probabilities both higher and lower than some critical probability. If it does, that’s encouraging. If it doesn’t, then you’ll want to understand why not, and that should give considerable insight into the algorithm — perhaps even enough to understand why it is incorrect …
Dear Tim, there is no way people will look at your algorithm without perfect exposition, even, if it works on random examples, you understand all aspects of the solution you get, especially, if the essence of the proof takes one page for the problems like P=NP. I do not see how you, and company, can imagine the proof of P=NP in one page.
Thank you very much for constructive replies!!! Out of 12 people, wandering who is this crazy guy, only one opened page with the subject!!! Although, I’m a crackpot trisector (since I’m not amateur mathematician, since I’m not mathematician by soul), I do not want to fight windmills. I did my job, it is your turn to take your long hard way. Bruce Reznick is preparing “Equal sums of higher powers of quadratic forms”, which may shed some light onto the subject.
Having been associated with the programming world for a long time, I sense another (perhaps a not-so-important one) barrier; at least it is a pretty common occurrence in real life : the programming logic may not implement an algorithm very accurately.
If the algorithm is ‘relatively’ simple looking, say AKS Primality testing, it may not be an issue. But if the algorithm itself is monstrously complex, there’s no theoretical warranty that the corresponding computer program is really executing the algorithm to the dot. So in the occasion when some test of a galactic algorithm fails, it might be difficult to separate out an inherent flaw in the algorithm from an error in programming.
Arnab, to sharpen the point of your post, it commonly happens that urgent practical problems can be solved only via galactic algorithms. For example, given a gene sequence we might greatly desire to know the affinity of the protein specified by that gene sequence for some specified antigen/drug target. Unhappily, it is usually the case that this affinity can be calculated to high precision only at galactic computational cost (and even then, we worry that the algorithm lacks precision even at infinite run-time).
So what do people do in the real world? There are at least two commonly-used strategies. The first is to run 100 separate low-precision (hence low-cost) simulations on 100 candidate sequences, then clone/ express/ purify/ assay all 100 candidates, such that in effect, Nature runs the high-precision simulations. The second (parallel) strategy is to validate the simulation against known thermodynamical principles and/or conservation lows and/or validation suites, and then deliberately speed-up the calculation (thus degrading its accuracy by some unknown amount) until the thermodynamical/conservation laws/validation tests just barely hold … but at least the computation cost no longer is galactic.
Of these two approaches, complexity theory in particular (and dynamical theory in general) helps most with the second approach. A good review is Advances in methods and algorithms in a modern quantum chemistry program package (PCCP 2006), in particular the introductory sections “Context” and “Challenges.”
Yes, there *are* plenty of “galactic challenges” for complexity theory here, and plenty of good “yellow book” theorems that are waiting to be proved … and applied.
Also, these approaches work … and therefore have immense practical importance … exponential rates of progress have been sustained over many past decades, and (obviously) there are at present no known complexity-theoretic lower bounds to sustaining this rate-of-progress in future decades. This is good news for everyone, young researchers in particular.
Prof. Lipton already mentioned about the problem of software verification in the beginning of the post. It isn’t a new point I was trying to bring in – I realized.
Nevertheless, it is an intriguing fact that it is much easier to humanly validate if a computer program correctly computes – say Ackermann function, vs. the fact that is somewhat harder to check if a program can carry out quick-sort correctly.
People, you drive me crazy. Just tell me that someone with technical skills is working on it, or considering to work on it. I know only few groups, that are working on the intersection of algebraic geometry and sum-of-squares/semi-definite-program – Pablo Parrilo, Monique Laurent, Jiawang Nie. Murray Marshall has some interests in it, but as I know his interests has no connection to complexity. Sociologically, I see their position, there is no need to look at text, that is not rigorous enough. Moreover, they a strong believers of . I have no technical skills to bring it to their attention. Guys, Gals, I need your help, to translate it to the level, where they can be convinced to read it, or give to some students to read it. That is why I suggest it to be polymath project.
. I have no technical skills to bring it to their attention. Guys, Gals, I need your help, to translate it to the level, where they can be convinced to read it, or give to some students to read it. That is why I suggest it to be polymath project.
I’ll try to bring a bit more arguments, all of them are too small, to pass the barrier of prior. I’m still hoping, there are curios graduates, that would not take words of famous mathematicians as granted, and would ask questions themselves. I do not see any other way to go here. Remember learned helplessness, I can stand my idea wrong, I have PhD, but ignorance drives me crazy.
Aruments: , with degree of
, with degree of  , see section 5 (according to arxiv). See 5.5, where they say that
, see section 5 (according to arxiv). See 5.5, where they say that  in all examples.
in all examples.
1. Parrilo and Sturmfels “Minimizing polynomial functions” run simulations on
2. Murray Marshall in his book "Positive polynomials and sums of squares", (2008 last sentence on p. 157) “Positive Polynomials and sums of squares” – “Since is an interior point of the cone of sum of squares 10.7.1 explains why minus infinity was never obtained as an output in these computations (but it does not explain the high degree of accuracy that was observed, which is still a bit of a mystery)“.
is an interior point of the cone of sum of squares 10.7.1 explains why minus infinity was never obtained as an output in these computations (but it does not explain the high degree of accuracy that was observed, which is still a bit of a mystery)“.
3. "Sums of Squares, Satisfiability and Maximum Satisfiability" (2005) by Hans van Maaren, Linda van Norden write (pp 29-30, section 8.)
"Based on these experiments there is no reason to suppose that polynomials of degree 4 coming from
unsatisfiable 2-SAT formulae may yield the desired counterexamples. On the
other hand, due to the numerical imprecision the opposite cannot be concluded
either. Only much more accurate optimization methods, or much more accurate
implementations of SDP-algorithms, could result in a more final conclusion."
This does not say anything in general, but look at eigenvectors, and eigenvalues you obtain from the solutions, and ask few questions to your professor, if you have matlab take code from my blog, if you have python look for BQP on sourceforge.
The arguments I provided, also applicable to 3SAT. Here one needs to encode not of 3SAT instance as![\sum [(x_{k,1}-b_{k,1})(x_{k,2}-b_{k,2})(x_{k,2}-b_{k,2}) ]^2](https://s0.wp.com/latex.php?latex=%5Csum+%5B%28x_%7Bk%2C1%7D-b_%7Bk%2C1%7D%29%28x_%7Bk%2C2%7D-b_%7Bk%2C2%7D%29%28x_%7Bk%2C2%7D-b_%7Bk%2C2%7D%29+%5D%5E2&bg=ffffff&fg=333333&s=0&c=20201002) this lead to 6-order polynomial, and one needs 12-order polynomial, that fixes satisfiable solutions at
this lead to 6-order polynomial, and one needs 12-order polynomial, that fixes satisfiable solutions at  , that is
, that is  . By the same arguments
. By the same arguments  can be represented as a full rank positive definite matrix, and instance is a projection onto one of the axis. By Givens rotation this axis can be brought explicitly into representation of
can be represented as a full rank positive definite matrix, and instance is a projection onto one of the axis. By Givens rotation this axis can be brought explicitly into representation of  ! This leads to high degree in
! This leads to high degree in  semi-definite program that itself adds 3 orders to complexity.
semi-definite program that itself adds 3 orders to complexity.
The final argument.
1.![p \in \mathbb{R}[x_1,...,x_n]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5Cmathbb%7BR%7D%5Bx_1%2C...%2Cx_n%5D&bg=ffffff&fg=333333&s=0&c=20201002) – real polynomial.
– real polynomial.
2. The partition problem asks whether a given sequence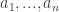 of positive integer numbers can be partitioned, i.e., whether
of positive integer numbers can be partitioned, i.e., whether  for some
for some 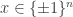 . Equivalently, the sequence can be partitioned if
. Equivalently, the sequence can be partitioned if 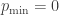 for the polynomial
for the polynomial 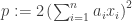
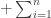
 . This version of partition problem is also an NP-complete problem.
. This version of partition problem is also an NP-complete problem.
3.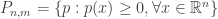 – a cone of positive definite forms in n variables of degree m.
– a cone of positive definite forms in n variables of degree m.
4. finding min p(x) is equivalent to finding minimum s.t.
s.t. 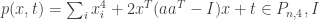 – identity matrix.
– identity matrix.
5.![\Sigma_{n,m} = \left\{ p: p(x)= \sum_{i=1}^m g_i(x)^2, g_i \in \mathbb{R}[x_1, ..., x_n] \right\}](https://s0.wp.com/latex.php?latex=%5CSigma_%7Bn%2Cm%7D+%3D+%5Cleft%5C%7B+p%3A+p%28x%29%3D+%5Csum_%7Bi%3D1%7D%5Em+g_i%28x%29%5E2%2C+g_i+%5Cin+%5Cmathbb%7BR%7D%5Bx_1%2C+...%2C+x_n%5D+%5Cright%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) – cone of sum of squares polynomials.
– cone of sum of squares polynomials.
6. Sums of squares program (SOS):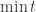 s.t.
s.t. 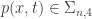 is solved in polynomial time to arbitrary precision (time is log of precision).
is solved in polynomial time to arbitrary precision (time is log of precision).
7. For polynomial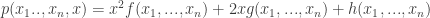 the expression
the expression ![D(p,x)= fg-h^2 \in R[x_1,..., x_n]](https://s0.wp.com/latex.php?latex=D%28p%2Cx%29%3D+fg-h%5E2+%5Cin+R%5Bx_1%2C...%2C+x_n%5D&bg=ffffff&fg=333333&s=0&c=20201002) is called the discriminant of
is called the discriminant of  with respect to
with respect to  .
.
8.
9. Discriminant of (4) with respect to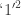 (homogenized 1) is
(homogenized 1) is  ,
, 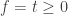 .
.
10. Since are positive numbers, all terms in quadratic form are nonegtive, and therefore,
are positive numbers, all terms in quadratic form are nonegtive, and therefore, 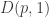 is a diagonal minus tail.
is a diagonal minus tail.
11. "POSITIVE SEMIDEFINITE DIAGONAL MINUS TAIL FORMS ARE SUMS OF SQUARES" by CARLA FIDALGO AND ALEXANDER KOVACEC. Therefore, SOS converges to global minimum of p.
12. The geometry of the problem is to find the closest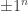 point to the hyperplane orthogonal to
point to the hyperplane orthogonal to  . For very small values of
. For very small values of  (limiting SOS/SDP performance) deviation is defined by the smallest and largest values of
(limiting SOS/SDP performance) deviation is defined by the smallest and largest values of  , moreover extreme problems are quadratic, therefore required precision is not exponentially small.
, moreover extreme problems are quadratic, therefore required precision is not exponentially small.
Don't belive 7-8., write Schur complement, that will bring you back to the form I wrote before.
This is based on published paper. The steps I take are primitive, and it is straightforward to find the wrong place. I may need some explanations, but readily accept the places that need more work. The evidence is the initial discussion with Noah in my earlier posts in the blog. I have impression we are playing religion, and not science.
I would like to ask a question. Whether a problem NP-comp x belongs to P, is equivalent to know whether x is simplified algorithm?
That is, Chaitin’s theorem concern the question P = NP?
Excellent blog, thank you.
Another common occurrence is that algorithms are widely and successfully deployed to solve practical problems, for many years and even many decades, before it is appreciated that the algorithms formally are galactic. An enjoyable discussion, with abundant examples, can be found in Christopher Hillar and Lek-Heng Lim’s arxiv preprint Most tensor problems are NP hard (and I’d like to credit the anonymous poster “Bart” for pointing to the Hillar-Lim preprint as an answer to Tyson Williams’ TCS StackExchange question “Complexity of Tensor Rank over an Infinite Field”). Thus “formally galactic” is by no means the same as “practically galactic.”
As an aside, it commonly happens that algorithms that formally are in EXP with respect to trajectories in optimization search-spaces and dynamical state-spaces having exponentially large dimension, are formally in P — but galactically so — when the trajectories are pulled back onto the tensor search-spaces and state-spaces of the Hillar/Lim preprint. Even then, it commonly happens that the often-brutal approximations necessary to reduce galactically-in-P to practically-in-P are tolerated surprisingly well in practice. As Dick and Ken often have noted here on Gödel’s Lost Letter, there is at present no very satisfactory explanation of the generic computational robustness of ad hoc computational order reductions.
The vast, vast majority of HPC problems are based on dense matrix operations (multiplication, LU decomposition, eigenvalues etc). Something like matrix multiplication seems about as algorithmically optimized, via Strassen and Coppersmith-Winograd, as it can get. The issue becomes one solely of FLOPS, data movement, and microarchitecture, loop unrolling and hardware parameterization..
On the other hand, there’s a burgeoning megagraph-analysis field, in which GT’s David Bader is an unquestioned star. Taking the tremendous body of graph theoretic literature and adapting it to graph problems — especially a non-heuristic approach to employ of multiple methods as one works through a data set, or perhaps by somehow relating microarchitectural capabilities to graph algorithmic properties — could yield big wins.
Hope you’re well, Professor.