How Powerful are Random Strings?
A study in collaboration

Eric Allender and Luke Friedman and William Gasarch have written a paper that shows why it is good for a student to be exposed to experts in various areas. Luke is Eric’s student. Both Eric and Bill can individually be called “experts in various areas,” but here the symmetric difference of their area clouds seems to have been more important than their intersection. Eric is particularly known as an expert in Kolmogorov complexity, and has led a longstanding project to relate various versions of it to computational randomness. Bill has training in logic and recursion theory, and is adept at proof techniques that work by meeting—and sometimes injuring—infinitely many requirements in some priority order. The paper features a new result in Kolmogorov complexity obtained by meeting such requirements.
In such cases, what is a student to do? I (Ken) say learn the symmetric difference—then you don’t have to worry about just keeping up with either advisor.
Bill has a paper published in the logic journal, the Journal of Symbolic Logic, which I (Dick) find extremely impressive. The paper is also impressive—it is joint with Stephen Fenner and Brian Postow, the latter when a student of the late and much-loved Carl Smith. (I, Ken, also have a paper with Smith and Postow, one well outside my areas.)
Bill of course also co-authors the famous blog Computational Complexity with Lance Fortnow. Blogging promotes his research by exposing him more to other areas, such as Eric’s. Eric has not written for any blogs—not even a guest post can we find. Non-blogging promotes his research by giving him more time to write papers that involve other areas, such as Bill’s.
Today I (Dick) wish to talk about their paper itself, which will appear at ICALP 2011. It has the interesting, but general, title, “Limits on the Computational Power of Random Strings.” While its title is general I believe it is a terrific, important, and potentially seminal paper. As usual see the paper for the full statements of the theorems, and for all the details. What I want to do is just give a flavor of their results—while Ken wants to take a larger view on the problems they are trying to solve. Hopefully the symmetric difference of what we brought to this post will still be clear enough to motivate you to read their paper carefully, and even write the next paper.
Random Strings
Recall the set 

As was common with him, Kolmogorov, published, in 1965, a short note that started a new line of research.
Very impressive. Perhaps we should all publish more short notes—alas probably only someone like Kolmogorov can create whole areas this way.
There now is a large body of results on Kolmogorov random strings. They have been used in many areas of theory, including lower bounds, proof theory, and protocols. There are two basic results from this area. First, a string chosen uniformly at random is likely to be in
The Main Problem
Bill, Eric, and Luke study the set of Kolmogorov random strings 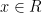
Previously results were known of the form:

The classes are 

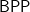



Since the right-hand sides have power beyond what is computable, however, are these inclusions really meaningful? What one would like are equalities, giving new characterizations of these classes, which would quantify the algorithmic power of the random strings.
A simple idea is to intersect the right-hand sides of these inclusions with the class 
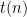
![{A \in \mathsf{DEC} \setminus \mathsf{DTIME}[t(n)]}](https://s0.wp.com/latex.php?latex=%7BA+%5Cin+%5Cmathsf%7BDEC%7D+%5Csetminus+%5Cmathsf%7BDTIME%7D%5Bt%28n%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
However, they observed that the manner of building such sets 
The “Postmodern Problem” of Information Theory
As described at the outset by Wikipedia, Postmodernism is characterized by the revelation that apparent absolutes are based on relative constructs, especially regarding the language by which they are conveyed.
Now if there is one quantity in Computer Science that we feel should be absolute, surely it is the measure of information. After all, in many human languages, computer science itself is called some word form of Informatics. In computational complexity theory, we have by-and-large agreed that the multitape Turing machine is the model that provides the “standard meter.” The maximum number of steps taken by a program on inputs of a given length 


It is ironic that the machine model is absolute for time complexity, but the machines are themselves the relative element for 

In this recent contest to find short universal Turing machines, the first concrete items under “Goals and Motivations” involve Kolmogorov complexity, next to a photo of Kolmogorov himself. They reference John Tromp’s “utterly simple computer model” and this paper by Jean-Paul Delahaye and Hector Zenil trying to find a “stable” definition. Delahaye and Zenil remark that the range of values of
For Eric, Luke, and Bill this is a problem because they don’t really have a single set

The particular point is that the constant 

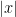

Here we note the technical issue elided above. Given a seed string 


Their Solution and New Results
Looking for a “best” 
One might think to define 

This is accomplished by turning the problem on its head: for every decidable language 
Enter Bill and inter Luke, in-between. Here is one sentence that shows the kind of intellectual proof complexity needed:
We break this requirement up into an infinite number of requirements.
Then each new requirement gives rise to a game, which is another tool of logicians. The games body-check the requirements in priority order and sometimes injure them—since Atlanta is about to lose its ice hockey team, this will have to substitute. As before, please see the paper for full details.
Even so, they are only able to give upper and lower bounds—not quite matching for a characterization. Here are their two main results:

The amazing thing about both the old and the new results is that they seem like they should not hold. Why should intersecting over machines
This last note about uniform classes speaks to possible larger significance. Any computable pseudo-random generator will have to have range disjoint from any
We also wonder, if the upper bound on the second main theorem can be improved to 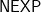
Open Problems
Eric, Luke, and Bill list as open questions whether one can remove the “

Of course their main open question is, can the 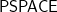


Is there a better way to judge the true power of random strings? Can this help for general lower bounds?
[changed “and” to “and/or” after Eric for three results; some format fixes.]


To be sure, Complexity Theory has its own “postmodern problems.” Only the running time of a program is well-defined, not that of an algorithm. By Blum’s Speed-Up Theorem, some problems are known to have no best program, hence no well-defined complexity. The theory is largely asymptotic anyway. Yet it has been one of the most scientifically important achievements of the last half-century, with P=?NP among the most important mathematical open problems.
“Postmodern problems” weren’t unknown to the ancient philosophers either. Heraclitus around 500 BC is the first known to argue that there ought to be a unique Logos underlying natural and human science the way logic serves for mathematics. But even granting one, Heraclitus himself wrote that man would be unlikely to understand it concretely.
I would define a small-ell logos as “a means by which truth and other quantities are determined.” In this sense, a particular choice of universal TM serves as a logos for the definition of Kolmogorov complexity—at least it is needed to define the value K(x), even though the value is almost always uncomputable. Thus the problem of finding a unique definition for information content is analogous to the classical philosophical problem of finding the unique Logos for the world, which Christianity and various traditions answer in one way, while science tries to answer in another.
Great post. Great (post-)comment.
There’s an assertion in the Allender/Friedman/Gasarch article that reads:
It would have been very helpful if the article had given examples of “decidable” versus “undecidable” sets.
E.g., is the set of even integers decidable? Is the set of random integers decidable? Is the set of Turing machines in decidable? For me, the answers are “yes”, “no”, and “it’s hard to say” … and yet the answers to this class of questions seemingly are of considerable importance in complexity theory …
decidable? For me, the answers are “yes”, “no”, and “it’s hard to say” … and yet the answers to this class of questions seemingly are of considerable importance in complexity theory …
… and that’s why this particular Gödel’s Lost Letter column (for me) would be substantially enhanced by a discussion (with examples?) of what complexity theorists mean by “decidable sets.”
Wow… although some spots are still obscure, I can say I grapsed the essense of both the problem and the proof.
Great proof technique and great job explaining it. I see great potential in this line of research, perhaps even answering the great one.
I have a question regarding the definition of what is a random string. To avoid choosing any particular universal Turing machine, coudn’t we simply define the complexity of a string as the smallest possible number of states, such that there exists a Turing machine with this number of states?
In my previous comment it should be “a Turing machine withthis number of states which outputs the string?|
@Lukasz: in your reasoning, equally valid definitions would be e.g. “number of states times 2” or “number of states + f(M)”, where f(M) is some function measuring the “complexity” (arbitrarily defined) of the machine’s transition graph. Freedom in this choice corresponds to the freedom of choice of Universal TM you get in the classical definition of Kolmogorov complexity. In the classical definition, this arbitrariness is “hidden” in the definition of the universal machine (i.e. how it translates binary strings into descriptions of transition graphs)..
@Marcin: thanks, that shed some light, but could you convince me why “number of states” alone is not a good complexity measure?
The problem is that the sole number of states isn’t very meaningful – for any Turing machine with m states, you can construct an equivalent TM with only 2 states, but with expanded tape alphabet. So the notion isn’t really robust against modifications. On the other hand, there is a notion of “state times symbols” complexity – see chapter 1.12 of Li and Vitanyi’s “An introduction to Kolmogorov complexity and its applications”.
I would also argue that the number of states doesn’t measure “full complexity” of a string, since it’s not a full description of the string (to fully specify the string, you need states + transitions) – and I may like my complexity measure to quanitfy the complexity of the full description of my object.