We Believe A Lot, But Can Prove Little
The gap between what we believe and what we can prove

Stan Eisenstat is a numerical analyst who works on various aspects of real computing, and is one of the top experts in solving sparse linear systems. He is a faculty member at Yale in Computer Science now, and was there when I was at Yale in the 1970’s.
Today I want to discuss what we believe and what we know about complexity classes.
This is something I have commented on before: beliefs vs knowing. But I feel that it is worth discussing further, and I hope that you agree.
I had the pleasure, when I was at Yale, to work with Stan on a variety of projects. Stan combines a deep understanding of the mathematics of algorithms with a great feel for what is practical and what is important. He is also a master programmer—a great deal of his early work was on actual implementation of algorithms for numerical computing. He is a wizard at solving recurrences; I believe this ability is related to his understanding of differential equations.
Stan used to tell me, more than once, two statements:
- The function
is bounded.
- The function
is
.
He would tell me these when I ran into his office excited that I had improved some algorithm by some small amount—perhaps by a log. If the new bound was 
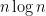

Both his statements are technically false, but both have a grain of truth to them, especially back in the 70’s when Stan told me his insights. They are related to our notion of galactic algorithms that Ken Regan and I discussed before here. Even today
goes to infinity with great dignity.
—Dan Shanks
Please keep these insights in mind as we examine what we know about complexity classes and what we believe.
Time vs Space
One of the oldest, one of the best, and one of the most beautiful results we know concerns the relationship between time and space. The best theorem to date is the classic theorem due to John Hopcroft, Wolfgang Paul, and Leslie Valiant:
Theorem: For any function
,

This is a wonderful result—one of my all time favorite theorems in complexity theory. Most of us believe more should be true, but it is unlikely that we can prove much more soon—their result is over 30 years old. There is a technical reason to believe that the term 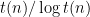
The proof is very clever and if you do not know it take a look at the famous paper. I will not go into any details of the proof, but will discuss the pebble game that the proof rests on, among other tricks and ideas. The pebble game is a solitaire game that is played on an acyclic graph 
- A pebble can be placed on any vertex
provided there are pebbles on all the vertices
with incoming arcs to
- A pebble can be removed from any vertex at any time.
- The goal of the game is to get a pebble on a particular vertex
—the target.
It should be clear the game can always be won: just place pebbles on all sources. Then on all vertices that have all their incoming vertices pebbled and so on. What makes the game interesting is the number of pebbles is limited. Thus pebbles must be placed and removed in a strategic manner. The key result is that any bounded degree acyclic graph can be pebbled with
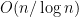
pebbles: the constant is only a function of the degree of the graph.
The rationale behind the game is that you should think of placing a pebble on a vertex as a step of the computation. A step is only possible if all the inputs to the vertex are known, corresponding to those which are already pebbled. The removal rule allows computations to be forgotten. Essentially this rule corresponds to the ability of memory to be reused, since once a pebble is removed it can be used elsewhere on the graph.
Bob Tarjan and Thomas Lengauer in 1982 proved lower bounds on the number of pebbles need to win on a bounded degree graph. Their paper is titled, “Asymptotically tight bounds on time-space trade-offs in a pebble game.”
Stan had an early practical result around when the time-space separation theorem was proved. He had an algorithm that “threw” away information it had computed, and re-computed that information later on—again. His algorithm, which was joint with Martin Schultz, essentially played the pebbling game.
I recall talking to them about their result and telling them it was related to a recent major theory result. The reason they needed to throw away information was that the limiting resource for their algorithm was space not time. They discovered that the algorithm ran faster if rather than writing to disk and storing the information, they simply threw it away and re-computed as needed.
Deterministic vs Nondeterministic
The belief that 

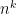

The best theorem to date is the classic theorem due to Wolfgang Paul, Nick Pippenger, Endre Szemerédi and William Trotter:
Theorem:
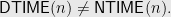
Rahul Santhanam, more recently, showed an improvement to their classic result:
Theorem:
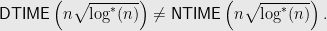
Recall Stan’s comments about the growth of functions. Forget the square root, the function 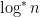
One of the strange properties of both these theorems is they do not extend to arbitrary running times. One of fundamental tricks in complexity theory is the notion of padding, which often allows a result of the form
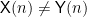
to yield

for example. Here 

Quantum vs Nondeterministic
Atri Rudra, Ken, and I have been looking at what is provable about quantum complexity, mainly the class 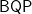
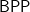
Most believe that quantum is much stronger than classic computation. There is ample evidence of its power; perhaps the main one is Peter Shor’s famous result that factoring is in
Theorem: At least one of the following is true:
- The class
is not contained in
.
- The class
is not contained in circuits of polynomial size.
It is weak because it is a disjunction of two possible results—both are probably true. But who knows. A long-time friend, Forbes Lewis, called this type of result: “truth or consequences.” The point is that we can also view this theorem as saying: If 
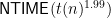

Open Problems
There are several interesting open questions. Of course the fundamental one is to improve any of these or related results about complexity classes.

Trackbacks
- Tweets that mention We Believe A Lot, But Can Prove Little « Gödel’s Lost Letter and P=NP -- Topsy.com
- WJP and Complexity Theory « The Phlegmatic Programmer
- Yogi Berra and Complexity Theory « Gödel’s Lost Letter and P=NP
- Yogi Berra and Complexity Theory « Gödel’s Lost Letter and P=NP
- Getting On Base With P=NP « Gödel’s Lost Letter and P=NP
- Can We Prove Better Independence Theorems? | Gödel's Lost Letter and P=NP
- Do natural generalizations of P versus NP exist? | Question and Answer
- Could We Have Felt Evidence For SDP ≠ P? | Gödel's Lost Letter and P=NP
- Do natural generalizations of P versus NP exist? - FAQs System
- Backurs, Indyk connect strong exponential time hypothesis to edit distance; other CS time/ space hiearchy/ continuum news | Turing Machine


What is the common belief about BQP being contained in NP? I thought that we don’t believe BQP is that strong, and, hence, the direction nondetermenistic time has subexp circuits => quantum is contained in nondetermenistic seems like the interesting one. I don’t know much about quantum, so am I getting it all wrong?
Sasho: I believe that most people (for some definition of “most”…) who have thought about it would conjecture that BQP is not in NP. Indeed, there is some evidence (e.g. see this paper by Scott Aaronson) that BQP is not even in the polynomial hierarchy.
Ashley,
We prove what we can. BQP may not be in NP, but we tried to start proving something.
As Ashley said, the growing belief (largely due to Scott’s work) is that BQP and the polynomial hierarchy are incomparable.
I’ve heard it as “log log n can be proved to grow to infinity, but has not been observed doing so…”
On the separation result – is it possible that there’s some function f(n) for which we could prove that DTIME(f(n)) != NTIME(f(n)) implies P != NP? That would offer a natural ‘upper bound’ on how far we could push the linear-time result using known methods and even go a ways toward explaining why these sorts of results are so hard to get!
In response to the “log n isn’t that bad”, actually log n starts getting annoying even when n is “only” in the gigabyte range. It’s almost impossible to sort “galactic” data sets, and this is part of the motivation for streaming algorithms. the difference between n and n log n is a factor of 30, and is a big deal.
Of course, when n gets larger, even linear is bad. that’s a different story….
I tend to assume that log n is a moderate-sized constant. Usually in the range of 20 to 40, and always less than 100. It’s certainly something that must be taken into account, but still less than some constants that are hidden by the O-notation.
On real systems with large data sets, cache misses can be more important than computation. The difference between O(n) time and O(n log n) time with similar hidden constants is often just a factor of 2 or 3, if both algorithms cause O(n) cache misses. On the other hand, O(n log n) time with relatively large hidden constants and O(n) cache misses can be much faster than with small constants and O(n log n) cache misses.
I have to ask… can you say anything about the proof technique?
Yes—we’re in the stage of “we’ve convinced ourselves by e-mail, not yet had time to view it in a full paper.” I realize actually we need to clarify the quantifier over the t(n) time bound and say whether upward-padding for containments holds. It requires some knowledge of Ryan Williams’ technique. Here it goes:
Assume for sake of contradiction that both 1. and 2. are false, i.e. that BQTIME[t(n)] is in NTIME[t(n)^1.99] and NE is in P/poly, for natural constructible time bounds t(n) we will quantify later. The goal is given an arbitrary 2^n-time NTM N, to simulate it on any x in NTIME 2^n/poly(n), violating the NTIME hierarchy theorem. Define:
(1) D_x stands for a succinct representation of clauses C_1 ^ … ^ C_m that are satisfiable iff N accepts x. D_x is a circuit that on input j outputs the three indices i1,i2,i3 of variables in C_j, with their signs.
(2) W_x stand for a poly-sized witness circuit that takes the index i of a variable, and for some satisfying assignment independent of i, outputs the value of x_i. Under NE in P/poly, Williams’ adaptation of Impagliazzo-Kabanets-Wigderson’s easy-witness construction shows that whenever x \in L(N), such a W_x exists.
(3) WIT = {[x, D_x, W_x]: For each j, D_x(j) = {i1,i2,i3} is such that one of W_x(i1), W_x(i2), or W_x(i3) satisfies C_j}. (Note the condition entails W_x is a witness circuit and puts WIT into co-NP.)
Take c such that D_x and W_x have encoding size n^c —Williams takes c = 10 in his paper but says it can be smaller—and put r ~= n^c as the size of instances of WIT. [Update: Ryan says that applies to D_x but for W_x only “some c” is implied, as I see clearly now—and with permission to note that other things look OK so far…] Now we have WIT \in co-NTIME[O(r)] by Williams’ construction (this implies WIT \in co-NTIME[r] sharply by the Book-Greibach theorem, not sure if this is relevant). Moreover, his construction (if we understand right) does this with only n+O(log n) = O(r^{1/c}) bits of nondeterminism.
This means that the exhaustive search is over a domain of size poly(n)2^n sharply. Thus applying Grover’s algorithm,
WIT needs a poly(n)2^n search ==> WIT is in uniform BQTIME[poly(n)2^{n/2}].
Now assume BQTIME[t(n)] is in NTIME[t(n)^1.99]. Specifically we are applying this with t(n) = poly(n)2^{n/2}, or more precisely in terms of the actual input length r to WIT, with t(r) = poly(r)2^{r^{1/c}/2}. However, presuming that padding translates upward for quantum just as well as classical, we could start with any lower natural t(n) or t(r). Thus we get:
==> WIT is in NTIME[poly(n)2^{(1.99/2)n} = NTIME[poly(n)2^n/2^{0.005n} ]
This is OK—the terms in r and the fact that the input to WIT has length r not n get absorbed into the poly(n). Now we finally get the algorithm:
1. On input x, construct the circuit D_x. (poly-time)
2. Using the hypothesis NE <= P/poly, construct the "easy witness" circuit W_x. (subexp time)
3. Build the uniform Grover circuits for WIT.
4. Since we are treating the circuits as uniform, there is a *fixed* NTM N' that runs in time 2^{n – 0.005n}*poly and accepts WIT.
5. So run N' on input [x, D_x, W_x], and accept iff it accepts.
(In step 4., it may-or-may-not be important that the runtime of N' comes out as a function of n not r.)
This gives NTIME[2^n} in NTIME[2^{n – 0.005n}*poly], a contradiction.
So we have: BQTIME[t(n)] is not in NTIME[t(n)^1.999] ==> NE is not in P/poly.
Are any snares lurking when we try to refine the details?
Thanks very much! Looks very nice – I like the way that a simple use of Grover is enough to lead to a non-trivial complexity-theoretic result.
I must be totally confused, but don’t separation results normally propagate downwards thanks to padding? (As for example here in Sec 2.7)
Hi Amir—
If you’re referring to my proof sketch a few comments above, the point where padding could be used in the proof is for propagating a containment, not a separation.
Hi Ken – I was referring to RJLs statement about the “strange property” of the DTIME/NTIME separation.
Ah, you mean in particular the statement “X(n) != Y(n) implies X(n^2) != Y(n^2)”—you’re right on the surface. But maybe we can find an example where a lot of supporting work makes it progress like hat…
Speaking of Complexity Classes, we have a new Internet proof candidate for NP=P.
The author, Vladimir Romanov, has even released source code.
Shall we crowdsource its debunking? Or is everyone still tired from the HP guy?
http://romvf.wordpress.com/2011/01/19/open-letter/
Yes I have the paper. I have not looked at it yet, but unless someone steps up with some insights why it may work perhaps we should wait. But I will start to look at it.
I briefly glanced at the paper.
A big red flag for me is that he tests his algorithm on Random SAT. I think it is almost a universal experience for aspiring complexity theorists to devise a potential SAT algorithm, test it on Random SAT, and think they are going to be famous. Hard instances of SAT produced by polynomial reduction from things like factoring or theorem proving are a completely different ball game, and alleged polynomial SAT algorithms do not survive them.
My other concern is that his algorithm seems to construct a solution by seeing what does not lead to an obvious contradition with small sets of variables, and laminating those small sets into larger sets. With hard SAT instances, the number of combinations of m literals which cannot be excluded by looking for a contradiction by asserting the literals with unit clause propagation grows exponentially with increasing m. So attempts to solve genuinely hard SAT instances by solving locally and merging the small candidate solutions into larger ones always blow up on memory.
I’ll probably wait until tomorrow morning to see if the Slashdotters have ripped it to shreds before expending printer ink and brainpower on it.
But I’m not holding out much hope.
It’s morning.
There has been some discussion of the paper at http://news.ycombinator.com/item?id=2121727
So far, several people have reported trying the code on hard SAT instances, and having it blow up. No one has reported trying a hard SAT instance and having it work.
Several people have commented that parts of the paper are unclear, and one person used the term “handwaving.”
No one can find anything else the author has published, at least in the English language.
So unless there is some startling new development yet to be revealed, I’m not going to look at the paper further.
The Paul-Pippenger-Szemeredi-Trotter result has another amusing aspect. The main Theorem 2.1 about finding segregators is trivially true if 15rN/log*N is greater than N. (At one point I convinced myself that this should be 20rN/log*n to correct a small error on the same page, but it doesn’t much matter.) Here r is a constant that is eventually going to come from the number of tapes in the TM, but even if r = 1 the theorem is only non-trivial for N at least exp*(15), a rather large number. I sometimes bring this result up when introducing the “sufficiently large N” part of the definition of big-O…
An interesting crowdsourcing approach to ranking computer science departments: http://www.allourideas.org/computersciencerankings
Very interesting.
Typo:
many -> may