Logarithms, Tables, and Babylonians
On pre-computation methods for speeding up algorithms

John Napier is the discoverer of logarithms, and was sometimes called the “Marvellous Merchiston,” which is a pretty neat name. His publication, in 1614, of his book entitled “Mirifici Logarithmorum Canonis Descriptio” was a milestone for science. This work changed science at the time—it made calculations possible that were previously impossible.
Today I want to talk about logarithms as an example of a more general principle: when can pre-computed tables be used to speed up computations?
Some credit Michael Stifel with discovering logarithms years before Napier, but Napier’s book included ninety pages of log tables that made them a practical tool. They were used by scientists of all kinds—including apparently astrologists.
Stifel did make important advances in mathematical notation: he was the first to use juxtaposition to denote multiplication, for example. I should have included his work in our recent discussion on notation. Stifel also tried his hand at predictions: he predicted the world would end at 8am on October 19, 1533. This points out a key rule for anyone who attempts to make predictions:
A prediction should be vague in effect or far in the future or both.
I ran across an interesting discussion of how log tables were used at Cambridge during math exams. Students were allowed to bring only basic tools such as a compass, a protractor and writing instruments to an exam. They were checked carefully as they entered the examination room to see if they might have any notes or other forbidden materials with them. They could also bring a special book of logarithms—it was often checked for illegal notes.

I learned how to use logarithms at Massapequa High School, not at Cambridge. In his first lecture on logarithms, our math teacher explained that we would each be supplied with a special printed sheet of paper whenever we were tested. These sheets contained a printed version of the log tables that were exactly the same as the tables in the back of our math books. This method avoided the need to check that we might have written some notes on the tables, since they were given out and collected for each test.
Our teacher also told us a story about the sheets that he claims really happened. In a class, years before, he had two students who were identical twins—very smart identical twins. They missed the first day of his class on logarithms.
After a while he gave his class their first exam on logarithms. As he was handing out the sheets he gave one to the first twin. The twin looked at the sheet and asked “what is this for?” Our teacher said they were the log tables they could use during the exam—they were copies of the tables from the math book. The twin handed the sheet back and said that he did not need it, since he and his brother had assumed they would need to know the tables. So they had memorized them.
The twins were smart, but they also had photographic memories. They assumed that part of learning logarithms was having to know the log tables. They were wrong: the whole point is that you do not have to remember the tables, and that is a main part of today’s discussion. They were impressive: I cannot imagine being able to remember even one page of the logarithm table.
Tables
The point of pre-computed tables is they can be used to speed up a computation. This idea is ancient, powerful, and probably not as widely used today as it could be. Perhaps the tremendous speed of our computers has made it less important to do pre-computation. Certainly logarithm tables are no longer needed—just use your calculator.
However, we do see tables used in a number of significant situations.
- Perhaps the best example is search—especially of the Web. All search engines have precomputed tables that allow the search of the countless pages of the Web in a fraction of a second. Okay there are only a finite number of pages, but the number is huge. It is claimed that the number of unique URL’s is above one trillion—as in 1,000,000,000,000. So fast search would be impossible without tables.
- Another important class of examples come from pervasive computing. Table lookup has been suggested as a way to save energy. The basic idea is to have the smart device pre-compute parts of a protocol, for example, when the device is being re-charged. Then the protocol will run faster when the device is running on batteries.
Napier’s logarithms reduce multiplication to additions and lookups. There are other ways to do this, to replace multiplication by “easier” operations. One dates from ancient times, perhaps thousands of years ago. Two clay tablets found at Senkerah on the Euphrates in 1854 show that the Babylonian’s seem to have used tables to reduce multiplication to squaring. The key equations are:

Both can be used to reduce multiplication to squaring.
What is the advantage of log tables over square tables? Let’s take a careful look at the cost of each of these methods.
The log method to multiply 

- Lookup and get
and
from the logarithm table.
- Add these to form
.
- Then look up
.
This takes: three lookups, one add, and two tables.
The square method to multiply
- Add to get
.
- Look up the squares of
in the table: let the values be respectively
.
- Form
, and then divide by two. This yields
This takes: three lookups, three add’s, one divide by two, and only one table. I grouped addition and subtraction together, since they have about the same complexity.
Clearly, the logarithm method uses less total operations. But it does require two tables. From an asymptotic point of view both the above methods are linear time plus the three lookups.
Issues
Several questions come to mind. Why did the squaring method not get wider practical application? It uses such basic mathematics that it could have been used years before Napier’s work. Preparing a squaring table is not to difficult.
One answer is based on a property that Subrahmanyam Kalyanasundaram pointed out that distinguishes the log method from the squaring method. Here are his comments:
An inherent feature of the log based multiplication is that we take the log over the “normalized” number. Basically
is multiplied as
I feel that this normalizing makes sure that we shift to the most significant digit and we spend our best efforts computing these digits. The log based method does it when we divide the number into characteristic and mantissa. Can the square method also do something like this?

Another question is what is the best that you can do with tables? I have never thought about this question. Given different costs on lookups and add’s what is the optimal method for reducing multiplication to table lookups? Of course multiplication is a very well studied problem. The current best is the beautiful algorithm of Martin Fürer that uses no tables and multiplies in time

Here 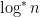
Open Problems
A more general question is what is the power of tables in computing a general function. Given a function 




Isn’t poly-time computation with pre-computed tables just P/poly?
A small but (I think) fascinating tidbit on the limits of lookup tables in web search: Google’s Udi Manber has stated that 20-25% of search queries are new queries, which limits Google’s ability to cache the results in a lookup table. Of course they use lookup tables for all kinds of things, but I think this is a surprising bottleneck in the problem of doing search. Ref: http://www.readwriteweb.com/archives/udi_manber_search_is_a_hard_problem.php
In practical computing, tables can be horribly expensive. If a table lookup misses in the processor cache, as it will for a large table, the time cost of the lookup can be hundreds of CPU cycles lost that could have been used to compute the value. The ratio of CPU speed to memory speed has changed dramatically in the last 15 years. In addition multiplication and addition are now pretty much the same speed (at the cost of many nearly free transistors!)
On an energy basis, the cost of a main memory cycle can also be greater than recomputing a result, due to all the wires that must change state to communicate between the CPU and the memory.
Even internalized truths like “FFT is better than DFT” need to be reevaluated because random access patterns are very much more expensive than sequential patterns of data access.
Pre-compiled and pre-computed tables may be very useful. But I think, common rules are not possible here – very often we need experiment to find optimal solution.
distance oracles come to mind when thinking about when pre-computed data structures can be used to speed up computations.
the database community is surely investigating these questions all the time
Tables are still taught at least briefly in integral calculus: find antiderivates, this week you can use these tables. Of course, freshman integral calculus is way over obsessed with antiderivatives and it’s blatantly stupid to teach people tables when we have the internet and widely available free symbolic integration tools. At least with the increasingly exotic “techniques” (trig substitution, partial fractions, …) you could make an argument that “someone’s gotta preserve the knowledge of how the packages work!” But tables…ugh…
Another good example is Andrew Goldberg (and other’s) work on computing shortest paths in continental-scale road networks: they precompute shortcuts and transit nodes to enable very fast source-sink shortest path queries, trading off memory for time.
I find this definition of pre-computation too narrow. Whenever space is traded for runtime I see it as a pre-computation. For me this starts with CPU caches and goes all the way to any datastructure that intentionally does not lay out its contents as compactly as possible.
first babylonian equation is more efficient:
c=a+b
d=a-b
lookup c’=c^2, d’=d^2
ab=(c’-d’)/4
three add equivalent, two table lookup one division by four, one table used.
I heard the following story and I think it is true, even if I cannot check for it.
In France, there is an engineering school (les Arts et Métiers) where logarithm tables where traditionally forbidden at exams, but the student where numerous enough to reconstruct the table with minimal individual effort during the exam. Each student knows “his” logarithm, so when someone needs log(534), he quickly shouts “534”, and the “knowing student” shouts the answer. If the shout quickly enough, it is difficult to know who shouted and they cannot punished ! Nowadays, the method is not used anymore, but the tradition for each student to know his logarithm survives.
Frédéric Grosshans
Great story.
Very interesting post.
The computation complexity of using tables seems to be model dependent. Using random access memory is not the same as using Turing machines, at least it seems to me.
How is computational complexity counted when one uses large tables? Suppose you form a table of size n log n, in time O(n log n), and then use it repeatedly by computing the address of the information to be retrieved from the table, say by retrieving log n consecutive bits at a time. Does the step of retrieving the value from the table count as number of consecutive bits plus the number of bits needed for address, or the product of the two?
This question seems to be important for studying complexity of problems like multiplication, which is sensitive to log n factors.
I would really appreciate if someone answered this question: Having a table of size O(n log n) which needs O(log n) bits to address, and being interested in chunks of O(log n) consecutive bits, does retrieving m blocks of log n consecutive bits count as O(m log n) or O(m log^2 n) in time cost?
For models like multi-tape Turing machines, retrieving from the table seems to be time consuming (perhaps I do not know how it is dealt with); random access memory seems to count time of retrieval differently. On realistic models for large memory storage, it seems plausible to assume that time for retrieval of B consecutive bits that need A bits to address in the table requires time O(A+B) rather than time O(A*B).
So, my question (once again, sorry) is the following: Having A address bits and retrieving B consecutive bits from the memory, what is the time cost of looking up the table? Is it O(A+B), O(A*B) or something else? How does this time depend on the computation model?
Yes, it is fact that Pentium 4 CPU (or multi-core processor) and Turing machines are different. This is open problem for computational complexity theory! V.N.Kasianov & V.A.Evstigneev offered new machine model in their book “Graphs in Programming…” , 2003, (1104 pages in Russian).
Sorry, this does not answer my question. Perhaps there is answer in this book?
It seems to me that squaring table would not offer any advantage if time consumed was O(log n ^2) to look up log(n) bits in a table addressed by log(n) bits, since multiplication is more efficient than looking up the table.
So, I assume that answer is O(A+B), but if one comes say with a new algorithm for multiplication using O(n log n) steps, that relies on such counting, would this result be worth anything if in fact looking up tables is O(A*B), i.e. expensive and hence useless (even example of squaring from the main post)
Sorry. Yes, this does not answer your question. I do not know the answer. I only noted this open problem.
Actually, despite repeating your question many times, it is still not quite clear to me what you’re asking. Surely, you could come up with arbitrary models in which table lookups have arbitrary time cost. The complexity really is very dependent on the model and your question does not really have a single answer.
If you’re asking about common models, it’s easy to see that:
1) A Turing machine with a constant number of tapes and sequential access could take time O(N) to find a bit in an array of N bits (imagine an adversary argument).
2) A RAM model will take O(1) time to look up an entry in a table that’s addressed by B bits, as long as B is less than the word size. I am not sure what’s the standard treatment of that case, but I would think that if a table can be addressed by B bits and the word size is W, then the table lookup would cost W/B.
As Larry Stewart pointed out above, it’s difficult to say what actually is the case on a real machine, i.e. what is the most appropriate model. You can safely say that the truth is somewhere betweeen 1) and 2) (due to cache and energy issues, etc.), and there are models studied in CS that stand between 1) and 2). An interesting example is the cache oblivious model which does put the cache into the model but does not “tell” the algorithm the cache parameters. Algorithms that work well in the cache oblivious model seem to use the complicated memory hierarchy of real machines quite well,too. Here is a link: http://courses.csail.mit.edu/6.897/spring03/scribe_notes/L15/lecture15.pdf.
For a synchronous logic (i.e., CMOS VLSI) circuit model, which is what I think you’re asking about, the answer is… it depends. 🙂
For this circuit model, there is a global signal, the clock, that every gate within the circuit is relatively synchronized to. As a very rough general rule, a “table look up” circuit will be able to perform a new look up every clock period, and provide a result every clock period. One thing that is pervasive in synchronous logic circuit models but is rarely mentioned in complexity theory models is the concept of “latency”, which is the number of clock cycles it takes for the lookup request that began in t_0 to appear at the output, which is usually ≥ 1.
The trick is to try to have enough work to do where you can have as many things “in-flight” as possible so that this latency is “hidden”. If you can do this, then the operation has an effective cost of O(1). Programming languages and algorithms tend to have a “left to right, top to bottom” model of time. This concept does not exist in synchronous logic- everything is happening all the time. It takes some getting used to.
Available for free (via Google Books) is the complete text of Nathaniel Bowditch’s 1807 masterwork of applied mathematics, The new American practical navigator: being an epitome of navigation, containing all the tables necessary. This classic text remains in-print today, 203 years later, and is known globally by the simple eponym “Bowditch“.
From a computational point-of-view, Bowditch is the fulfillment in every detail of John Napier’s vision. As the Preface asserts:
Moreover, in service of this ambitious educational goal, Bowditch corrected many thousands of errors in the tables of logarithms (and other functions) of the eighteenth century.
Furthermore, beginning on page 100, Bowditch asserts a startlingly modern view of differential geometry as being (essentially) the study of integral curves of tangent spaces … thus anticipating Gauss (for example) by about two decades.
Fans of computation … fans of geometry … fans of history … fans of technology … and especially, fans of Patrick O’Brian’s novels, all can hardly go wrong by consulting Bowditch.
Let’s not forget prosthaphaeresis…
Sniffnoy, thank you for introducing us to the wonderful word “prosthaphaeresis” Surely, it is only a matter of time until a SteamPunk novel appears having this title! 🙂
With the help of Google Books, we find many highly entertaining articles by the prolific nineteenth century mathematician J. W. L. Glaisher on the history and practice of pre-computer computation; both logarithms and prosthaphaeresis feature prominently.
No doubt, in a another century or two, our present mathematical conceptions of computation and complexity will seem similarly quaint … and (hopefully) similarly seminal.
The table-of-squares method of multiplication can be improved somewhat from (lookups, adds, shifts) = (3,3,1) to (2,3,0) by using the formula
ab = ((a+b)² div 4) – ((a-b)² div 4)
and precomputing the squares div 4. Here we only need two lookups instead of three, and no shifts are required.
Iconjack, by your method the triple product abc requires 2*(2,3,0) = (4,6,0) shifts. Is it possible to do better?
In passing, I noticed a 19th century article by the redoubtable J. W. L. Glaisher that treated the triple product (to advantage) by prosthaphaeretic methods (but to my regret, I did not write down the specific reference). In any event, the computation of triple and higher-order products is a natural line of inquiry.
With enormous luck, perhaps these multiple-product algorithms might generalize even to multiple matrix-products … in which event, the Victorian era of prosthaphaeretic computation may not yet be over! 🙂
MR,
Thanks a lot.