Stating P=NP Without Turing Machines
A statement of P=NP that uses only linear equations and their generalizations

George Dantzig is famous for the invention of the simplex method for solving linear programming problems.
Today I plan on presenting a definition and explanation of P=NP, but avoid the usual technical details that seem to be needed to explain the problem. The approach will depend greatly on the famous linear programming problem and its generalizations.
Dantzig is a source of the “legend” that a student once solved an open problem that he thought was just a hard homework problem. I heard various versions over the years, but his story is apparently genuine. I quote his own words:
During my first year at Berkeley I arrived late one day to one of Neyman’s (Jerzy Neyman) classes. On the blackboard were two problems which I assumed had been assigned for homework. I copied them down. A few days later I apologized to Neyman for taking so long to do the homework – the problems seemed to be a little harder to do than usual. I asked him if he still wanted the work. He told me to throw it on his desk. I did so reluctantly because his desk was covered with such a heap of papers that I feared my homework would be lost there forever.
About six weeks later, one Sunday morning about eight o’clock, Anne and I were awakened by someone banging on our front door. It was Neyman. He rushed in with papers in hand, all excited: “I’ve just written an introduction to one of your papers. Read it so I can send it out right away for publication.” For a minute I had no idea what he was talking about. To make a long story short, the problems on the blackboard which I had solved thinking they were homework were in fact two famous unsolved problems in statistics. That was the first inkling I had that there was anything special about them.
I do wonder sometimes if P=NP will be solved this way. Not knowing that a problem is “impossible” must have some psychological advantage. Can we forget that P=NP is hard and take a fresh look at the problem? I wish.
Let’s turn to the explanation. If you know what a linear equation is, then I believe you will be able to follow my explanation of what “P” is, what “NP” is, and what “P=NP?” means. There will be no Turing machines mentioned anywhere—except here. This mention does not count. Even if you are an expert on P=NP, I hope you will like the approach I take here.
Linear Equations
In high school we all learned how to solve linear equations—at least we were “taught” how to solve such equations. No doubt given the equations
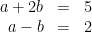
we could all solve the linear equations and get that 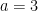

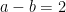
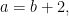
which implies
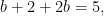
by substitution. This shows that 

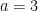
There is a systematic method of eliminating one variable at a time that was known to Carl Gauss over 200 years ago, and today we call his method Gaussian Elimination (GE). This algorithm (GE) is used everywhere, it is one of those fundamental algorithms that are central to computations of many kinds. If Gauss were alive today between royalties on GE and the Fast Fourier Transform, he would be very wealthy.
One of the central questions we need to understand the P=NP question is how to measure the efficiency of algorithms. One way to calculate the time GE requires is to count only the major operations of addition and multiplication that are performed. Let’s say we have 


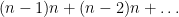
which adds up to order 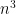
Linear Equations Over Non-Negative Numbers
In the above example of equations we did not say it explicitly, but we allowed rationals for the solution. The solutions for 

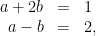
now has the solution 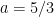
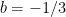
Many linear systems that arise in practice require that the solutions be non-negative. Suppose a company is trying to calculate how many trucks will be needed to haul their products, it is highly likely that that the values of the variables must be non-negative. It does not make any sense to use 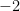
There is a fundamental difference and a fundamental similarity between plain linear equations (LE) and LP. You probably did not learn in school how to solve such systems. Even with a few variables the task of solving such a problem can be a challenge.
The surprise is we know something the great Gauss did not know. We have a method for solving LP instances that is fast—almost as fast as GE—for solving linear equations. The result is quite beautiful, was discovered after many doubted it existed, and is used today to solve huge systems. Just as GE has changed the world and allows the solution of linear systems, the ability to solve LP has revolutionized much of science and technology. The method is called the simplex method, and was discovered by George Dantzig in 1947.
One measure of the importance of the LP is it is one of the few mathematical results whose inventors were awarded a Nobel Prize. In 1975 Tjalling Koopmans and Leonid Kantorovich received this great honor. You might note that Dantzig did not win, and the reason for that is another story—see here for some insights. Another measure is the dozens of implementations of the algorithm that are available on the web—see this.
The computational cost of the simplex algorithm is surprisingly not much more than GE’s cost. In practice the running time is close to 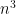
- The simplex algorithm is really a family of algorithms. The algorithms all move from vertex to vertex of a certain geometric object: usually there is a choice for the next step, and the running time is sensitive to this choice. For some choices it is known to be slow, and for other choices it works well in practice. Even more complex there are choices that are open whether they always run fast.
- The simplex algorithm is not the only way to solve LP’s in practice or in theory. I will not get into a discussion of the algorithms that have provable fast running times.
Linear Equations Over Natural Numbers
Linear systems can model even more interesting problems if we allow the solutions to only be natural numbers. Now the variables must take on values from
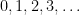
The reason this is so useful is one of the great insights of complexity theory. It was discovered by Gödel, Cook, Karp, and Levin. These problems are called Integer Programming Problems (IP). They can express almost any practical or theoretical problem. In many linear problems you can only allocate a whole number of something: try assigning 

We know more than Gauss, since we can solve LP’s. But we are not that smart. We are stuck at IP’s. We do not know how to solve these problems. The central point of the P = NP question is, does there exist an algorithm for these problems like there does for rational linear systems?
Put another way, does there exist an algorithm for IP’s that is like those for Gaussian Elimination and LP? This is the central question. A solution would have to take polynomial time—recall LE uses order 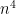
This fundamental question goes by the name of the “P=NP” question. The name is easy to say, “the P equal N P question,” and you can write it down quickly. Often we typeset it as
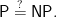
There are T-shirts for sale, in men’s and women’s sizes, that have this on their front. Alan Selman, a complexity theorist, has the license plate
P NE NP
Where I used to be a faculty member at Princeton, the Computer Science building has encoded in the bricks of the back of the building “P=NP?” in ASCII code. A flush brick stands for a 


You might want to know why the problem is called “P=NP?” and not the “Is there a fast way to solve integer programs problem?” Okay that would an awful name, but why not something better?
In mathematics there are several ways that problems get named. Sometimes the first person who states the problem gets it named after them; sometimes the second person. Sometimes problems are named in other ways.
Programming IP
We call LP, linear programming, and we call IP, integer programming. Both are real programming languages, even if they are different from standard programming languages.
A programming language allows one to express computational problems. The difference with LP and IP is that they are not universal languages, which means they cannot express all computations. They are not universal in the sense of Church—there are computations they cannot express.
Languages like C, C++, Perl, Python, and Java are universal languages. Anything can be expressed in them. This is both their advantage and their disadvantage. A universal language is great since it can do anything, but it also is subject to what Alan Perlis used to call the “Turing tar-pit.” Beware of the Turing tar-pit in which everything is possible but nothing of interest is easy.
The dilemma is that if a language is more powerful, then many more problems are expressible in the language, but fewer properties can be efficiently checked. If a problem can be written as a LP problem, than we know we can determine efficiently if it has a solution. If, on the other hand, a problem can only be written as an IP problem, then we cannot in general determine if the problem has a solution. This is the dilemma: one trades power of expression for ease of solution. But both LP and IP are much more powerful then you might think.
LP can solve many important problems exactly, and even more problems can solved approximately. IP can do just about anything that arises in practice. For example IP can be programmed to do all of the following:
- Break the AES encryption standard.
- Factor an integer, and thus break the RSA public key system.
- Find a 3-edge coloring of a graph, if one exists.
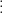
Programming Tricks
Just like any other programming language there are “tricks” in programming IP. To be a master IP programmer is not trivial, and I would like to present just a few simple tricks, and then show how to use them to solve 3-edge coloring on a cubic graph.
As an IP programmer one trick is to be able use inequalities. This is really simple: if we want the inequality
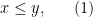
then we add a new variable 

Clearly, (1) is true if and only if (2) is true. A common use of this is to force variable 
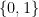
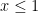
Here is another cool trick. Suppose we want to constrain 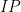

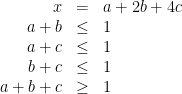
where 
Now suppose 



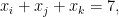
where 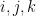
Suppose there is a solution 


Limits on the Power of IP
I have said that IP can handle just about any problem you can imagine. There are some limits on its power. For example, there is no way to add constraints so that variables 
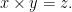
This is a curious result that seems “obvious,” but I do not know a simple proof. I would be interested in a simple proof, but for now let’s just say that there is no way to define multiplication.
Complexity Theory
For those who know some complexity theory, the approach I have taken to explain P=NP may seem a bit strange. I hope even if you are well versed in complexity theory you will still enjoy the approach I have taken here.
In complexity theory the class of problems solved by LP is essentially all of P, and the class of problems solved by IP is all of NP. The advantage of the approach here is that P=NP can be viewed as asking the question: Can all IP problems be programmed as LP problems? Note, to make this a precise question does require the notion of reduction. I will not define that precisely here, but imagine that the changing an IP problem to an LP problem must be a reasonable type of transformation.
Conventional Wisdom
Most theorists seem to be sure that IP cannot be solved efficiently. One of the many reasons for this is the power of IP as a programming language. There is just too much power, which means that if it were easy to solve, then too many problems would be easy.
I wonder before GE was discovered would many have thought that LE’s are hard to solve, or before simplex was discovered would many have thought that LP’s were impossible to solve?
One approach that many have tried to resolve P=NP is to encode IP problems into LP problems. The obvious difficulty is that a solution to a set of equations may have some of its variables set to proper rationals. The idea many have tried is to make the linear equations so “clever” that there is no way that solutions can be fractional. No one has yet shown a general method for doing this, which does not mean it is impossible, but it does mean it is hard.
Open Problems
Does this discussion help? Or is it better to present P=NP in the normal way? What do you think?
Here is what we know,
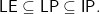
Most believe that all these subset relationships are strict, but it is possible that they all are equal. This is one of the great mysteries of complexity theory.
[fixed typo]
Trackbacks
- Top Posts — WordPress.com
- links for 2010-06-27 « Blarney Fellow
- Politopos. « US Patent Appl. 12213303: Comentarios.
- கேள்வியின் நாயகனே… « ப்ளீஸ், ஒரு நிமிஷம் வெயிட் பண்ணுங்க…
- George Dantzig e o Algoritmo Simplex « Blog do Guilherme Kunigami
- Polynomials Are Easier Than Integers « Gödel’s Lost Letter and P=NP
- George Dantzig e o Algoritmo Simplex « Blog do Kunigami
- Quora
- Gödel’s Lost Letter and P=NP - erichansander.com
- Barriers to P=NP Proofs « Gödel’s Lost Letter and P=NP
- Elementary P v. NP | edmx
- Elementary P v. NP – Regeneracy
- Elementary P v. NP – Panicking
- Elementary P v. NP – Excitations


This is fantastic, and coincidentally I formulated this myself independently just the other day! You have a duplicate sentence “Put another way, does there exist an algorithm for IP’s that is like those for Gaussian Elimination and LP?”
Another open question is to find other mappings of complexity classes to LP-type problems. Also, where do Complex Number Programming problems lie computationally?
Ross,
Great question. Can we identify many complexity classes as simple types of equation system? I think so.
#P is well described by the permanent.
Unfortunately the LP characterization of NP-completeness suffers in that it does not present NP as a decision problem. Still, it’s a rather neat way of looking at it.
Well I’m a layman at all this, but that sounds to me like something that algebraic geometers would be interested in. Any comments on that?
* “Unfortunately the IP characterization…”
[typo]
“Great question. Can we identify many complexity classes as simple types of equation system? I think so.”
The most obvious one is the famous MRDP theorem that says that all Turing machines can be encoded as Diophantine equations.
Indeed, P ?= NP is widely believed to be the only Clay Millennium Prize problem solvable by an amateur.
*widely* believed? Don’t think so. 🙂
The computational cost of the simplex algorithm is surprisingly not much more than GE’s cost.
Uh…really? The simplex algorithm runs in polynomial time? Do you know something the rest of us don’t?
Of course that is open. Tried to avoid getting too technical on LP solving methods.
a + b ≤ 1
a + c ≤ 1
b + c ≤ 1
a + b + c ≥ 1
If a, b, and c are natural numbers, isn’t this equivalent to saying exactly one of them equals 1? And isn’t that the same as the single constraint:
a + b + c = 1
?
Thanks, I missed that. Does make the point is programming, and easy to make simple errors. Although here just extra complex way to do something.
thanks again
“extra complex way to do something”
Actually, this is a key point, and something that happens in computer programming all the time. When we have several different ways to express a goal, the programmer may freely select from among them. But often that representation allows for cases the programmer knows will not occur; the programmer has additional knowledge that is not perfectly expressed.
The compiler has to worry about aliasing, overlapping memory regions and other “correctness” issues even if the programmer knows none of these apply to the code in question. The expression of the program often creates barriers to optimization.
I’m not a complexity theory expert, but perhaps cost-equivalence is the corresponding concept. Are there systems of IP equations that express equivalent “programs” but the transformation between members of an equivalence class isn’t polynomial-time?
Great article! Nice approach to P =? NP.
1. I’m surprised that most of your post is designed to be understood by laymen but you then introduce “3-edge coloring on a cubic graph” without defining any of those terms. In particular “cubic graph” is pretty obscure terminology. At the very least why not use the slightly less obscure “3-regular graph”?
2. As Nemo said the way you represent the constraint that x is in {1,2,4} is really weird.
3. Your statement that “there is no way to define multiplication” is a bit misleading. In particular your post seems to suggest that factoring is an easier task than multiplication! One can of course define multiplication of k-bit numbers using a number of constraints polynomial in k.
There seems to be a contradiction of the cost of LP.
1. “The computational cost of the simplex algorithm is surprisingly not much more than GE’s cost. In practice the running time is close to n^3.”
2. “A solution would have to take polynomial time—recall LE uses order n^3 time and LP uses order n^4 time.”
So is LP (simplex algorithm) n^3 or n^4?
Neither; it’s exponential. There are algorithms that solve linear programs in polynomial time, but simplex isn’t one of them (as far as we know).
It was not mentioned Kuhn-Tucker conditions, so the problem itself is that SIMPLEX is not a complete algorithm, like the rest of polinomial one… More especificaly:
X+Y+2Z+T-4K = 0
X, Y, Z, T Booleans
It solves Z=X and Y, T= X XOR Y, easy to demonstrate.
And it is not solvable in ever linear method, even being in the correct format.
If you want to know if P == NP I solved it in my article:
http://rekpub.com/American%20Open%20Computer%20Science%20Journal/Current%20Issue.php
The problem is Science Comunity is very very slow.
In fact, I have technology that solves SAT in O(n3):
https://archive.org/details/alternancias
Very nice post!
Two comments:
1. You say IP is unsolvable. But you meant not efficiently solvable.
2. Jeffe claims the simplex is not known to be in P. Probably this is true. So I don’t understand what is the formal state of knowledge now? What is the name of the known PTIME algorithm for solving LP? And what exactly is known about the complexity of the simplex method?
IP is hard but not impossible.
Simplex seems in practice to be between n^3 and n^4.
The last question is provable methods are based on a different approach—will discuss soon. See http://en.wikipedia.org/wiki/Interior_point_method for a pointer.
The difference in hardness between fractional and integral solutions is horrible in nonlinear arithmetic as well: arithmetic over the reals is decidable, arithmetic over the integers is as undecidable as can be.
I like this approach. To me it sort of “explains” why there is so few natural problems that seem to fall between P and NP-HARD.
For that matter, is there any nice way to fit the graph isomorphism problem into this framework.
Let’s take an engineering point-of-view.
We suppose that Bob comes to Alice with a code (written in Python, let us say) that solves IP problems using PTIME resources; that is, Bob provides Alice with a code of short length, running in limited memory, and finishing in a small amount of time, that he *CLAIMS* solves general IP problems.
Alice tests the code on some IP problems that reduce to NP-complete problems. The code always works as Bob claims.
Alice picks one of those problems, and executes Bob’s code in debug mode, that is, examining the code and all its variables, step-by-step (using pdb, let us say).
What informatically natural questions will the code-trace answer for Alice?
We have the intuition, that the information content that this one code-trace provides, times the number of NP-complete questions that Alice might have asked, has to be (in some sense) exponentially larger than bit-length of the code that Bob provided. And so (by a Chaitin/Kolmogorov counting argument), the IP code cannot accomplish what Bob claims.
Of course, I have NO clear idea how to formalize the notion of “informatically natural questions that the code-trace answers” … I only know, as an engineer, that whenever I code-trace an algorithm, I learn a lot!
But it is very hard to say, precisely what this knowledge comprises.
So perhaps that is part of the reason why P != NP is hard to prove. We know how to validate the informatic correctness of answers that the codes provide … but we don’t know how to gauge the informatic content of the code-traces that (in principle) tell us how the code obtained its answers.
To put it another way, when we code-trace (in PTIME) a Gaussian elimination algorithm, or an LP algorithm, or any other algorithm, we learn quite a bit about how that algorithm works. And if we code-traced a (hypothetical) IP algorithm, we have the informatic intuition that the code-trace would teach us much more … that it would teach us how all algorithms work … that it would convey so much information, that no PTIME code-trace could ever carry that much information …
What we lack (at present) is concrete mathematical answers to the Ferengi questions: “How does that work, exactly?. What does that mean, exactly?”
One possible dimly-imagined outcome—which would be consistent with Dick’s view that P=NP,—would be a IP code that worked similarly to Alex Selby and Oliver Riordan’s celebrated solution of the Eternity puzzle, that is, a set of heuristics that worked unexpectedly well, for the classes of problems that humans care about.
Then what the IP code-trace would teach us, would be simply the mysteriously effective heuristics that we humans use to create theorems and solve hard problems. And these heuristics would be well-worth knowing.
It will be nice to discuss Hirsch’s Conjecture (or the recently found counter example) and its implication (of any) on the complexity of Simplex Algorithm (more to educate persons like me)
Hello.
What if, in a general theory of everything kind of way, some singular human conscious had used simple Yes(I should feel guilty) or No(I do not feel guilty) answers to answer every moral question that he could remember that had ever occurred in his life. In this way he could have become completely pure. He would have truly asked himself all the questions that could be asked of him. He would have emotionally evolved back to when he was a child.
What if he then assigned an ‘It doesn’t matter as life is only made to make mistakes’ label on every decision that he had analysed.
This would not make him God or the devil, but just very still and very exhausted. Anybody can do this but just for the purpose of this experiment lets say I have done this. Which I have.
There are no fears in me and if I died today I could deal with that because who can know me better than myself? Neither God or the Devil. I am consciously judging myself on ‘their’ level.
To make this work, despite my many faults, take ME as the ONLY universal constant. In this sense I have killed God and the Devil external to myself.The only place that they could exist is if I chose to believe they are internal.
This is obviously more a matter for a shrink more than a mathematician, but that would only be the case depending on what you believed the base operating system of the universe to be. Math / Physics / morals or some other concept.
As long I agreed to do NOTHING, to never move or think a thought, humanity would have something to peg all understanding on. Each person could send a moral choice and I would simply send back only one philosophy. ‘ LIFE IS ONLY FOR MAKING MISTAKES’.
People, for the purpose of this experiment could disbelief their belief system knowing they could go back to it at any time. It would give them an opportunity to unburden themselves to someone pure. A new Pandora’s box. Once everyone had finished I would simply format my drive and always leave adequate space for each individual to send any more thoughts that they thought were impure. People would then eventually end up with clear minds and have to be judged only on their physical efforts. Either good or bad. It would get rid of a lot of maybes which would speed lives along..
If we then assume that there are a finite(or at some point in the future, given a lot of hard work, there will be a finite amount) amount of topics that can be conceived of then we can realise that there will come to a time when we, as a people, will NOT have to work again.
Once we reach that point we will only have the option of doing the things we love or doing the things we hate as society will be completely catered for in every possible scenario. People will find their true path in life which will make them infinitely more happy, forever.
In this system there is no point in accounting for time in any context.
If we consider this to be The Grand Unified Theory then we can set the parameters as we please.
This will be our common goals for humanity. As before everyone would have their say. This could be a computer database that was completely updated in any given moment when a unique individual thought of a new idea / direction that may or may not have been thought before.
All that would be required is that every person on the planet have a mobile phone or access to the web and a self organising weighting algorithm biased on an initial set of parameters that someone has set to push the operation in a random direction.
As I’m speaking first I say we concentrate on GRAINE.
Genetics – Robotics – Artificial Intelligence – Nanotechnology and Zero Point Energy.
I have chosen these as I think the subjects will cross breed information(word of mouth first) at the present day optimum rate to get us to our finishing point, complete and finished mastery of all possible information.
Surely mastery of information in this way will lead us to the bottom of a fractal??? What if one end of the universes fractal was me??? What could we start to build with that concept???
As parameters, we can assume that we live only in 3 dimensions. We can place this box around The Milky Way galaxy as this gives us plenty of scope for all kinds of discoveries.
In this new system we can make time obsolete as it only making us contemplate our things that cannot be solved because up to now, no one has been willing to stand around for long enough. It has been holding us back.
All watches should be banned so that we find a natural rhythm with each other, those in our immediate area and then further afield.
An old clock watch in this system is should only be used when you think of an event that you need to go to. It is a compass, a modern day direction of thought.
A digital clock can be adapted to let you know where you are in relation to this new milky way boxed system.(x,y,z).
With these two types of clocks used in combination we can safely start taking small steps around the box by using the digital to see exactly where you are and then using the old watch to direct you as your thoughts come to you.
We can even build as many assign atomic clocks as are needed to individually track stars. Each and every star in the Milky Way galaxy.
I supposed a good idea would be to assume that I was inside the centre of the super-massive black hole at the centre of the galaxy. That would stop us from being so Earth centric.
We could even go as far as to say that we are each an individual star and that we project all our energies onto the super-massive black hole at the centre of the galaxy.
You can assume that I have stabilized the black hole into a non rotating perfect cube. 6 outputs /f aces in which we all see ‘the universe and earth, friends’ etc. This acts like a block hole mirror finish. Once you look it is very hard to look away from.
The 6 face cube should make the maths easier to run as you could construct the inner of the black hole with solid beams of condensed light(1 unit long) arranged into right angled triangles with set squares in for strength.
Some people would naturally say that if the universe is essentially unknowable as the more things we ‘discover’ the more things there are to combine with and therefore talk about. This is extremely fractal in both directions. There can be no true answers because there is no grounding point. Nothing for the people who are interested, to start building there own personal concepts, theories and designs on.
Is it possible that with just one man becoming conscious of a highly improbable possibility that all of universes fractals might collapse into one wave function that would answer all of humanities questions in a day? Could this be possible?
Answers to why we are here? What the point of life really is et al?
Is it possible that the insignificant possibility could become an escalating one that would at some point reach 100%???
Could it be at that point that the math would figure itself out so naturally that we would barely need to think about it. We would instantly understand Quantum theory and all.
Can anybody run the numbers on that probability?
Mmmmmm…
Spam from the other side of the (sanity) fence, but spam nevertheless!
Fascinating way to define the problem! (I’m a complete amateur.)
It’s especially interesting that as the constraints get tighter—first only integers, then only naturals—the power of the language increases!
I’ve wondered if we could design imaginary universes (laws of physics) that would lead to models of computation in which we can easily show either P=NP or P \ne NP (or ideally find the kinds of universes in which P=NP is trivial and the kinds of worlds in which P \ne NP is trivial). But I don’t know enough to know if that idea makes any real sense yet—it was inspired by a number theory project I did about number systems in which unique factorization was violated.
I think I might be a little confused on one issue. Would we say that an arbitrary instance of factoring can be programmed (formulated?) in IP, but that we have no efficient method of… executing(?) the program? Or is it “solving” the program? Or maybe just that the IP program may express the problem, but just have horrible running time? (Or maybe even just ambiguous, non-analyzable running time…) I’m not used to talking about languages so much, I really ought to take a course on complexity.
That is, we can write an IP program to factor RSA-2048, but we don’t know how (or if) we can write an efficient IP program to factor it?
If that last sentence I wrote above is true, would it make sense to use a genetic programming technique to attempt to evolve efficient IP programs for factoring? I wish I knew enough programming to try this… seems like IP is reasonably simple, and so I would imagine a GP operating within IP would be relatively easy to create (and of course the fitness function is very straight forward).
Nice approach. You should add this to the Wikipedia page on P=NP. It would help many people a lot.
I’m a little confused (as usual).
You seem to be saying that LP problems and IP problems share the same expressiveness (wrong word?). That is, an IP problem is an LP problem with the additional constraint that the solution must only be integers. Other than that, they are identical. If that is the case, then wouldn’t IP problems be a subset of LP problems, and not the other way around?
Paul.
Aaah, I can answer this myself 🙂 The ‘language’ of IP contains the extra semantics of being allowed special constraints that ultimately restrict the solution. there is no way to express ‘is an integer’ in an LP program. That fact that the IP solution set is smaller than the LP one is irrelevant. Yes?
I don’t see why if LP P, then IP NP. How does this work?
That last paragraph should read:
“I don’t see why if LP is isomorphic to P, then IP is isomorphic to NP. How does this work?”
How about message passing among nearby vertices of a graph. Can one define LP and IP in terms of that? Can one define P and NP in terms of that, and does that shed light into why P!=NP ?
Hey, this is a really cool summary. I will share this with my lab mates and others here @ Northwestern interested in the problem!
Slight clarification: in the edge coloring encoding, it reads “x_i+x_j+x_k=7, where _i, x_j, x_k are adjacent vertices.” Shouldn’t it be: “incident edges” instead?
A very interesting read at any rate. Too bad that the definition of reduction had to be glossed over, though.
Great introduction to the P=?NP issue, using pretty simple concepts.
Considering the ‘Can amateurs solve P=NP?’ post, we have no other options but to conclude this post is helping increasing that probability !!!
JVerstry
> for now let’s just say that there is no way to define multiplication.
First break down x and y into bits, e.g., x=b0+2*b1+4*b2+…
Then pick your favorite digital logic circuit that implements multiplication
(the one used by your laptop is probably too complicated :),
connect the bits of x and y to the primary inputs, introduce new
0-1 variables for inner wires, and encode each logic gate with
linear constraints, for example out=1-in for NOT.
For the OR gate, use in1<=out, in2=2*out.
For the AND gate, use in1>=out, in2>=out, in1+in2<=2*out.
Unless I am missing something, the output bits
can then be interpreted as the product of integers x and y.
Igor
Oops… the AND and OR constraints were maimed by WordPress.
There are three constraints in each case.
For AND, the output bit can’t exceed either input bit,
and can’t be 0 when both inputs are 1.
For OR, the output bit can’t be lower than either input bit,
and can’t be 1 when both inputs are 0.
Sorry for the confusion…
Igor
I think the idea is that you have to express x y = z with a fixed number of other variables without knowing any fixed bound on the size of x and y. So you cannot have a variable for each bit.
I am not a complexity theory researcher. But an engineer working on using SAT in applications. I would formulate the xy=z problem as an IP as follows:
(of course I couldnt understand the last post that I cant use bits of x, y, z as variables. In that case my constaruction fails)
exrpress x, y, z in bits. The bits of the product xy i.e. z_i of z are bilinear functions of bits x_i, y_i of x,y. Let these bilinear equations be written as
w_{i}(x,y)\oplus z_{i}=0
where \oplus is the XOR of mod 2 operation. I will then convert these equations into CNF (Conjunctive Normal Form) clauses and then write a system of integer inequalities of each clause. These are always possible. If I solve this IP I get exactly those triples (x,y,z) which obey the equation xy=z.
Am I write?
of course I couldnt understand the last post that I cant use bits of x, y, z as variables.
My interpretation of Prof. Lipton’s comment on multiplication was that he meant that you couldn’t express x y = z as a single IP problem that works for arbitrary sized integers. And also that he alluded to this being a known, if difficult theorem.
I’m not an expert, but I think it follows from the undecidabilities of Hilbert’s tenth problem, since expressing x y = z would allow you to express arbitrary polynomial equations.
I agree with the two previous posters that you can express in IP multiplication involving a known number of bits.
Thats still a problem for me. For Me the solution is going to be found in String Theory.
The Rule: A divided by Zero is equal to NOT A. This means that as we disengage from A we find ourselves in a new numberset unrelated to our own numberset (A) except at superposition.
No matter the value of A, its going to share with /A a superpositional relationship. So if I want a Solution, no matter what I am looking for I simply divide by zero and compare /A to A. The ammount of time this will take is always going to be the same (unless you are incapable of understanding the Answer…In which case no amount of Time is going to help.
When would you not be able to understand the answer? We use a given set of symbols to relate numeracy as a language we can understand. However if the Symbols we use were like the universe – limited from a larger set by some restriction of possibility (n), we would need to overcome that limit before we could comprehend the fact that we are using a number set of n+j and that all our solutions are wrong.
Wow great article – as a software engineer I know my Turing Machines and P versus NP, complexity theory, etc. but less familiar with Linear Programming. This suggests making P = NP may be as “simple” or as hard as coming up with a Gaussian Elimination scheme that works for systems of equations whose variables can only be integers? Have I understood this correctly? That is, you come up with a general constructive method to create linear equations whose solutions can only ever be integers (not fractions)? So that we can know “ahead of time” by looking at how the linear euqation is structured that its answers will only be integers, and we can do that before we even try to solve the problem? And this method of “knowing ahead of time” can be generalized for any given linear equation constructed thusly? Is this roughly accurate? So then “P = NP” for a given problem (say, Travelling Salesman) is a matter of creating a linear equation for it, such that I know the answers to the variables will all be integers, and, that done, I simply solve for those variables? Makes me think maybe the zeitgeist opinion that P does not equal NP may be wrong, that we just have not found a Gaussian Elimination type of thing that works for these types of equations. Kewl.
I think the Extended Church-Turing Thesis can be generalized by saying that no two computing models can be told apart by what they’re able to compute efficiently. It’s like the relativity principle saying that no two reference frames can be told apart by a physics experiment. If such a principle happened to hold, it would set a limit on what can actually be computed by a quantum computer in the real world. It would also mean that P=NP is undecidable since, as explained in this post, it’s equivalent to comparing the power of two computing models.