Some highlights from STOC

Scott Aaronson is one, perhaps the one, of the best quantum computation experts in the world. He is great at explaining concepts in his beautiful papers, in his on-line writing, in his terrific blog, and in person.
Today I want to talk about the papers from the first day of STOC, the papers from Sunday’s sessions.
I spoke to Scott on Saturday at the opening reception, where he tried to explain to me the reason storage in a region  of 3-space is bounded by the surface area of and not the volume of . This is the holographic principle, and should not be confused with Leslie Valiant’s work on holographic computation. Scott says the prime reason for this surprising limit is: if one tries to pack too many devices into a region , one would create a black hole.
of 3-space is bounded by the surface area of and not the volume of . This is the holographic principle, and should not be confused with Leslie Valiant’s work on holographic computation. Scott says the prime reason for this surprising limit is: if one tries to pack too many devices into a region , one would create a black hole.
I have strong biases, so here are some of the papers I like very much from the first day of talks. As a certificate that I really was at the Sunday session, at least some of it, I heard Ran Raz speak on “Tensor-Rank and Lower Bounds for Arithmetic Formulas.” This paper was scheduled to be given Tuesday, but there was a re-shuffle of the talks at the last minute.
Ran gave a wonderful and clear talk on a subject that could have been, in my opinion, difficult to follow. He defined the notion of tensor and tensor rank in a clear way, and then related them to the complexity of arithmetic formulas.
We all know what a matrix is: it is a  by array of numbers. So what is a tensor? A tensor
by array of numbers. So what is a tensor? A tensor  is simply a mapping
is simply a mapping
![\displaystyle A: [n]^r \rightarrow F,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++A%3A+%5Bn%5D%5Er+%5Crightarrow+F%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
where  is a set of values. Usually is a field, but it could be more general. Note, when
is a set of values. Usually is a field, but it could be more general. Note, when 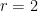 this is nothing more than the usual definition of an by matrix. So far, all is simple.
this is nothing more than the usual definition of an by matrix. So far, all is simple.
The key to all Ran’s work is the classic notion of the rank of a tensor, which generalizes the notion of the rank of a matrix. While tensor rank is “just” a generalization of matrix rank, our understanding of the behavior of tensor rank is much less than our corresponding understanding of matrix rank.
The definition of tensor rank is based on one of the definitions of matrix rank. Suppose  and
and  are non-zero by
are non-zero by  vectors, then
vectors, then
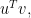
where  is the vector transpose, is the usual inner product of the vectors. It is a by matrix, which we usually identify as a scalar value. The expression
is the vector transpose, is the usual inner product of the vectors. It is a by matrix, which we usually identify as a scalar value. The expression
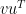
is the outer product of the vectors and is an by matrix—note the reverse order of the vectors. The non-zero vector  is a rank matrix by definition. Then, the rank of a matrix
is a rank matrix by definition. Then, the rank of a matrix  is the least
is the least  so that
so that

where each  is rank .
is rank .
The reason matrices are so nice is the above definition of rank agrees with many other definitions. You can define matrix rank based on Gaussian Elimination, on determinants, on dimensions of spaces, and so on. The problem with tensor rank is it is a generalization of the above definition of matrix rank, but it has few of the beautiful other properties of matrix rank. The tensor rank of is the least so that

where 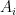 all have tensor rank . A tensor has rank if it can be written as the tensor product of “vectors.” See this for more details.
all have tensor rank . A tensor has rank if it can be written as the tensor product of “vectors.” See this for more details.
Finally, Ran shows that an explicit tensor of high rank implies an explicit arithmetic formula of high complexity. Of course, see his paper for the exact statements. Again the fact that tensor rank has none of the cool properties makes finding explicit high rank tensors hard. Note, the corresponding problem is trivial for matrix rank: the by identity matrix has rank .
Exponential Algorithms
These papers are my personal favorites. Since I am doubtful of many of the believed lower bounds it is natural for me to like papers that attack problems whose current best bounds are exponential. Even a small chipping away at the “obvious best” algorithms is something I enjoy seeing.
 Improving Exhaustive Search Implies Super-polynomial Lower Bounds Ryan Williams shows how even “small” improvements in exponential algorithms for a variety of problems would have great consequences. Here is an example result,
Improving Exhaustive Search Implies Super-polynomial Lower Bounds Ryan Williams shows how even “small” improvements in exponential algorithms for a variety of problems would have great consequences. Here is an example result,
Theorem: If Circuit-SAT can be done in time 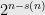 where
where  , then
, then

An easy result is if P=NP, then  . This follows by showing that if P equals NP, then by Dick Karp and my paper, EXP must have circuits of super-polynomial size. Ryan’s theorem can be viewed as a huge improvement over this simple insight. His assumption is a much weaker assumption than P=NP, and still implies that NEXP has big circuits.
. This follows by showing that if P equals NP, then by Dick Karp and my paper, EXP must have circuits of super-polynomial size. Ryan’s theorem can be viewed as a huge improvement over this simple insight. His assumption is a much weaker assumption than P=NP, and still implies that NEXP has big circuits.
On The Complexity Of Circuit Satisfiability Ramamohan Paturi and Pavel Pudlák study the exponential algorithms of many NP-complete problems. They look at algorithms of this type: they study randomized polynomial time algorithms for NP problems which have  success probability for interesting constants
success probability for interesting constants  . That is, they study randomized algorithms for NP which “offload” all the exponential complexity onto the success probability of the procedure. Such algorithms are known to exist for -SAT, where
. That is, they study randomized algorithms for NP which “offload” all the exponential complexity onto the success probability of the procedure. Such algorithms are known to exist for -SAT, where 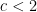 depends on . They show that if a similar type of algorithm existed for Circuit-SAT, then in fact Circuit-SAT can be solved in subexponential time along with other surprising results.
depends on . They show that if a similar type of algorithm existed for Circuit-SAT, then in fact Circuit-SAT can be solved in subexponential time along with other surprising results.
Quantum
A Full Characterization of Quantum Advice Scott Aaronson and Andy Drucker’s paper—presented by his student Andy—generalizes results on classic advice and the polynomial hierarchy. One key result is
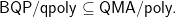
What makes this so interesting is the first advice bits are quantum, but the second advice bits are classic. They also have an interesting lemma that could be of use in other contexts. Take a look at their paper for the details.
BQP and The Polynomial Hierarchy Scott Aaronson studies perhaps one of the most important open questions in the complexity theory of quantum computing—where does BQP lie with respect to all the classic complexity classes. We still do not know if BQP is in the polynomial hierarchy. We do know that there are many “problems” that quantum provably does better than classic, but these “problems” are not decision problems. They either are promise type problems, or ask for values, or solve more complex types of questions. The real open question is: What is the power of BQP on pure decision problems? Scott relates this fundamental question to some neat open questions, which seem hard, but not impossible.
Dimension Reduction
A Sparse Johnson-Lindenstrauss Transform Anirban Dasgupta, Ravi Kumar, and Tamas Sarlos study dimension reduction. They prove a sparse version of the classic JL result. I believe this is one of those results that could have a huge number of applications. I am trying to use it right now on an old problem.
Open Problems
The main open questions are to try and solve some of the questions raised in these papers:
- Can we find explicit tensors of high rank?
- Can we find algorithms for Ryan’s theorems?
- Can we solve Scott’s open problems?
- Can we find applications for the sparse JL transform?
[fixed typos]
P.S. Sorry Andy for the errors.
Like this:
Like Loading...
Related



You say “Scott Aaronson’s paper – presented by his student Andy Drucker”. Isn’t it a joint paper?
Yes of course my error
🙂
Scott is an excellent person to ask about tensor rank, because under the name “tensor product states” these states are becoming ubiquitous across broad sectors of math, science, and engineering … see Charles van Loan’s (very readable) review “The ubiquitous Kronecker product” for the many names by which these states are known.
For several years now, Scott and his colleagues have been thinking (and publishing) very broadly about the interplay among the informatic, algebraic, geometric, and dynamical aspects of these objects, with each new article unveiling wonderful insights.
As for praising the trans-disciplinary merits of Scott’s “beautiful papers and terrific blog” … well heck … please let me join *that* chorus … by saying that we engineers agree 100%!.
“…where he tried to explain to me the reason storage in a region R of 3-space is bounded by the surface area of R and not the volume of R … Scott says the prime reason for this surprising limit is: if one tries to pack too many devices into a region R, one would create a black hole.”
This doesn’t make sense to me. Consider a region R of radius r in our universe, which is essentially flat Euclidean space with a roughly constant matter density. If we store 1 bit per atom, say, or 1 bit per 10^{23} atoms (constants don’t matter), then since the number of atoms goes like r^3 (by constant density), the information storage capability goes like r^3. For suitably large r, r^3 >> r^2, regardless of the constant prefactors. There is no need to try to pack more and more devices into the region R to get far more storage than the surface area.
Does this mean, by Scott’s logic, that the universe will necessarily collapse into a black hole? This seems unlikely. Given the limits of our knowledge of general relativity, I don’t think we can say for sure whether the entire universe will eventually collapse or whether it will continue expanding forever. Perhaps special relativity is more important here, since one might say that the information has to come from somewhere and has to be able to be read out (not expand outside your causal cone). I don’t see it, though. Black holes just don’t seem to be relevant if we store information at the average matter density.
Lazy man’s way of describing a black hole: whenever Newtonian calculations imply a body’s escape velocity exceeds c, you have a black hole (this turns out not to go too badly wrong in relativity, at least for spherical bodies).
So, given a density, if you assume that a body’s surface area scales sublinearly with its volume / mass, then it has a maximum volume subject to not becoming a black hole, where the maximum in question depends on density and the scaling function.
Not sure if the relativity part still holds for very non-spherical bodies? In any case, this sounds very much like a result whose practical use should not be too seriously questioned (we are hopefully not going to be producing any big black holes in the near future).
Anyway, the point is: if you want a non-stupid-shaped body, then the surface area will scale at 2/3 power of its volume, and you will have to make the density scale with 2/3 power of the volume as well to avoid a black hole. So your number of devices won’t grow with volume, but surface area.
In our universe, the universe’s classical state-space geometry (and maybe its quantum state-space geometry too?) is a dynamical element, and consequently the average mass density is dynamical too; at present the universe’s volume is expanding (but will it keep doing so?) and consequently the mass density is at presently steadily decreasing (but will it keep doing so?); the point is that global informatic arguments can be mighty subtle.
Approaching these same physical ideas from a (simpler) local point-of-view leads to Bekenstein’s bound, about which there is a good Wikipedia article.
Regarding applications of the sparse JL transform: sparse projections indeed found abundant applications in the realm of sketching algorithms such as:
M. Charikar, K. Chen, and M. Farach-Colton. “Finding frequent items in data streams.” Theoretical Computer
Science, 312(1):3–15, 2004.
M. Thorup and Y. Zhang. “Tabulation based 4-universal hashing with applications to second moment estimation”. SODA 2004, pp. 615–624.
On the practical side, we recently used these in a protocol for measuring packet corruption on Internet links. In this protocol, every transmitted or received packet corresponds to a unit vector in the (virtual) high-dimensional space-of-all-packets, and needs to be projected down to the low-dimensional space. Here, the sparseness of the projection allows for very low per-packet computational overhead, while the good approximation achieved implies we can project to a very low dimension and thus attain a tiny communication overhead when the sender and receiver “compare their notes” in order to detect faults.
Sharon Goldberg, David Xiao, Eran Tromer, Boaz Barak, Jennifer Rexford, “Path-quality monitoring in the presence of adversaries”, SIGMETRICS 2008, pp. 193-204.
Eran,
Thanks this all looks very interesting. I was not aware of all this work, I will have to discuss in the future.
Thanks
So Bekenstein’s “bound” only holds locally? It sounds like it has been oversold.
Anon comments: “So Bekenstein’s “bound” only holds locally? It sounds like it has been oversold.”
Bekenstein’s bound isn’t so much a polished mathematical theorem, as it is a practical calculation that points toward new ideas in mathematics. This is a much-appreciated service that physicists/chemists/engineers have very often provided to mathematicians. E.g., “Mechanics developed by the treatment of many specific problems” (Mac Lane), or “The reinjection of more-or-less directly empirical ideas, I am convinced, is a necessary condition to preserve the freshness and vitality of mathematics” (von Neumann).
Perhaps the point is that strong theorems ensure that mathematics is deep; empirical ideas ensure that mathematics is broad; the wonderful consequence is that modern mathematics is deep and broad.
This happy confluence of (depth)⊗ (breadth) is a particularly enjoyable aspect of quantum systems engineering, and IMHO it is becoming ubiquitously prominent in all of math/science/engineering.
HI webmaster, can I use many content from this article if I retun a link back to your page site? I will be very grateful.