Can We Solve Chess One Day?
Computers play great chess—can they play perfect chess?

Ken Thompson is one of the co-inventors of UNIX, perhaps one of the greatest programmers who ever lived, and won the 1983 Turing Award for his important work.
Today I plan on having a guest author, Ken Regan, discuss Thompson’s work on chess playing programs. It is Ken on Ken, or rather Ken on 
I once visited Bell Labs and spent some time talking to Ken T. on his chess program. I asked why he was doing so well—his program was winning a lot. He said his program had, probably, fewer bugs than the competition. In those early days chess programs were often buggy, and a program with a bug is likely to be a program with a chess weakness. The reason, Ken T. explained the programs were so hard to get right was simple: All chess programs looked at a huge set of positions and then generated one move. As long as the move was legal the programmer had no idea the program had made an error—unless the move led to an unexpected loss.
The rest of this is the work of Ken R., who by the way is an international master with a rating of over 2400. With, of course, lots of help from Subruk.
Chess Programs and the Big Match
Unlike us, Thompson has done pioneering research in computer chess programming. He and Joe Condon created the chess computer “Belle,” which won the 1980 World Computer Chess Championship and numerous other tournaments. In 1983 Belle became the first machine to achieve a recognized Master rating. It took only 14 more years for an IBM computer, “Deep Blue,” to topple the world champion, Garry Kasparov.
Today you can buy a $50 program for your laptop computer that likely can beat Kasparov, at least according to published ratings. Weird to me, this meant that people following the just-concluded World Championship Match online could often instantly know more about the state of play than the human champions. Often but not always, as shown by today’s climactic game in which Viswanathan Anand of India won with Black to defeat challenger Veselin Topalov 
Yet Thompson’s other great chess creation removes even that chance of error, and ties chess to several problems in computer science we’ve been thinking about.
The Book of Chess
Thompson greatly extended algorithms and data structures for carrying out perfect analysis of chess endgame positions with at most five pieces on the board—three besides the kings. You could be better than him and better than Belle overall, but if you got down to 5 pieces, you might as well be “playing chess against God” as he called it. It was a chess version of Paul Erdős’ proofs from the “Book,” in giving you not only the answer but the shortest route to the win or draw. His database overturned centuries of belief that certain endgames were drawn. You can win them—if you have the patience to find over 100 perfect moves
In the past decade people have completed a perfect analysis of positions with six pieces, and are now working on seven. This discovered a position where it takes 517 moves to force a winning capture, and then a few more moves to checkmate. That position hasn’t come up in any real game, but others do all the time. In fact, one could have arisen in the nerve-wracking 

Anand, as White to move, lost his last chance by using his Rook on c3 to take Black’s pawn. Most players would take with the other Rook to form a line along the 3rd rank. Leaving both Rooks on the rim gave Topalov an easy draw by perpetual check. Topalov could still have drawn, but it would take only a little inattention to allow White’s Rooks to block checks and reach a position like this:

Here White can give checkmate—in 99 moves. I don’t think a human would even find the first move, let alone all 99. It’s not a Rook check; it’s not pushing the pawn which White needs to promote to win; it’s a move neither of us understands. You can see it by going to the endgame site. The only move to win is Kf2-g2, shunting aside the King.
If you keep clicking the best moves for both sides, you reach this position when it’s mate-in-56:

Now “The Book of Chess” says to play 56.Rd3-d2+ Kc2-c1 55.Rd2-d1+ Kc1-c2 54.Rd1-d3!, reaching the same position but with Black to move! This idea called Zugzwang is known to chess players in many immediate situations, but we have no idea why “The Book” uses it here.
White has 4 other winning moves, but the first two allow Black quickly to force White back to this position, so they are not independent wins. The other two might be independent, but the increase the “mating distance” from 56 to 72 and 74, respectively. Now we’re starting to use terms from graph theory, with positions as nodes and moves as edges, but these are not your familiar garden-variety graphs. These graphs typify alternating computation, which is a fundamental part of complexity theory. And these graphs are big.
Building Big Files
How big? Under Eugene Nalimov’s modification of Thompson’s original file format, the database for up to 5 pieces takes 7.05 gigabytes, compressed over 75% from the originals. The complete compressed 6-piece set fills 1.2 terabytes. That’s on the order of large data set examples given by Pankaj Agarwal in a University at Buffalo CSE Distinguished Speaker lecture last month, for NASA, Akamai, the LSS Telescope, and others. The complete 7-piece set has been estimated to be around 70TB, and its computation may finish by 2015. Nalimov’s distance-to-mate (“DTM”) files are built iteratively working backwards from checkmate positions. The newer ones (and Thompson’s originals) use distance-to-conversion (“DTC”), which means including all winning positions with fewer pieces in the ground set. Following chess endgame practice, let’s call the winning side White. The first iteration marks all positions where White can give checkmate—and/or make a winning capture—in one move. The next iteration finds all positions where Black can’t avoid the previously-marked positions (or in DTC, must make a losing capture). Note that this is only a subset of the usual graph neighborhood of the marked positions—it’s the subset of 
The Search Problem
You’d like to take a particular position 
The tablebases of course can help in analyzing forward from a given position, because when the usual alpha-beta search reaches a node with 6 or fewer pieces, it will return a perfect answer. But herein lies a paradox: the hard-disk fetches slow the search down so much that competitive chess programs often play worse. The world champion “Rybka 3” chess program works best with its tablebase-probe policy set to “Rarely” (the default) or “Never,” not “Normally” or “Frequently.”
The degree to which the chess search does not stay localized is reflected in poor cache performance by the tablebase files in practice. One remedy is putting selected endgames on a smaller but faster flash drive. Another is using so-called bitbases, which give only the win/draw information and use far less memory. Omitting the distance information, however, raises the problem of playing programs going around in cycles. Can we address the caching issue more directly, by changing the strategy of how they are encoded, without losing their full information?
Asymptotically, for chess on 
Shorter Tablebase Descriptions?
Here’s one natural encoding shortcut that turns out to be wrong, exemplifying pitfalls of carrying intuition from garden-variety graphs to alternating graphs. Most chess programs today can solve Mate-in-5 problems in microseconds, looking ahead 9-10 ply where 2 ply means a move for each player. Suppose we store only the checkmate positions, then those with a DTM of 5 moves = 10 ply, then those with DTM 20 ply, 30, 40, etc. The idea is that if a chess program probes a position with a DTM of 29, then the program can do 9 ply of ordinary search, enough to hit the DTM-20 stored positions. We might expect to save 90% of the storage, on top of the 75% compression already achieved.
This idea works for an ordinary leveled graph, but fails in an alternating graph. This is because Black can make inferior moves that hop over the 10-ply, 20-ply, 30-ply boundaries. This creates game paths in which the minimax search never sees a marked node, until its own depth limit aborts it without result.
What we would like to do is to find short descriptions for whole hosts of positions, say all-drawn or all-winning for White, that we can express in lookup rules. The idea is to tile the whole position space by these rules, in a way that needs only a lower order of exceptional positions to require individual table entries. This raises a concept discussed before, namely descriptions of circuits that take an index 
The Tablebase Graphs
Can we organize the endgame files to make it feasible, given an initial position
This reminds me of papers on distance and clustering in large social-network graphs. The tablebase graph is huge and natural to study. What general properties does it have? Which classic graph properties and theorems can be carried over? Note the following trick: One can have position 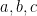
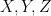






The Book as “Deep” Oracle?
Ever since IBM’s “Deep Blue” beat Kasparov, multi-processing chess programs have prefixed “Deep” to their names. But here I mean a different technical use of the word: computational depth. A string 
The Book of Chess has almost no information in classical terms—because it is described entirely by the rules of chess. These rules fit on half a page, and asking for the portion needed in the search from a given position
Although the database entries for the positions you see when playing from the Anand-Topalov position 
Open Problems
The ultimate goal is to solve chess—does white win, does black win, or is it a forced draw? Even as computers become vastly more powerful than humans we still have no idea who wins this great game, even from some well-analyzed famous positions. Can we even prove that Black does not have a forced win? This may sound silly, but actually Bobby Fischer opined that in a particular position reached after five symmetrical opening moves, he would rather be Black!
A realistic goal is to try and extend the perfect tables of play to eight, nine, ten and more pieces. The underlying algorithms are simple, but there seem to be challenging computer science questions. How to handle simple graph search on such huge graphs? How to apply methods that work for graph connectivity, but seem not to work on the game graphs? How to distribute large files, and optimize the caching tradeoffs?
Trackbacks
- Amir Ban on Deep Junior « Combinatorics and more
- Sorting Out Chess Endgames « Gödel’s Lost Letter and P=NP
- Andrej Karpathy» Chess… more elusive than I had imagined
- ¿Podremos resolver el ajedrez algún día?
- Thanks For Sharing « Gödel’s Lost Letter and P=NP
- A Computer Chess Analysis Interchange Format | Gödel's Lost Letter and P=NP
- El ajedrez y resolverlo con la fuerza bruta - Ajedrez
- The Shapes of Computations | Gödel's Lost Letter and P=NP
- Playing Chess With the Devil | Gödel's Lost Letter and P=NP
- Far From a Turkey Shoot | Gödel's Lost Letter and P=NP


My understanding of computer chess program design is superficial at best, so I will read your blog again. It was my opinion that the computer search for move was more of a memory search of past positions in all recorded games shoved into the memory chip. The actual priority of a move by a decision process that is not anchored to historical games does step into artifical intelligence realm.
I don’t see the dominance of a computer in chess as a challenge to us mere mortals. Computers running internet uses like this don’t bother me either. Chess is a human activity that has been subverted by cheaters using computer program analysis, but we do enjoy the interchange in play.
The cheating topic is what brought me into the statistical modeling in the first place—see my “Fidelity” site. There’s a lot more work I haven’t had time to collate and post there yet. Chess programs have indeed been trained on master games—and on special test-suites of positions with deep key moves. I believe Rybka in particular is strong enough that it is going beyond the former.
One can play through the Anand-Topalov positions and all other 6-piece endgames (except 5 pieces vs. 1) at Eiko Bleicher’s online server, hosted by http://www.k4it.de.
If you’re interested in a great deal of bizarre chess positions, games, ideas, and other miscellany, you might be interested in Tim Krabbe’s page here:
http://www.xs4all.nl/~timkr/chess/chess.html
It has quite a few “longest or shortest this-and-that” records, among a wealth of other entertainment.
One can play through 6-piece endgames online at Eiko Bleicher’s server hosted by Knowledge4IT in Germany. Only 5 pieces vs. a bare King is skipped. The server is sometimes down—and was while this article was being posted—but it is up now.
Suppose we store only the checkmate positions, then those with a DTM of 5 moves = 10 ply, then those with DTM 20 ply, 30, 40, etc. The idea is that if a chess program probes a position with a DTM of 29
A sound variant of that idea is storing for every position the DTM rounded down to the nearest multiple of 10. You’d only save a few bits per position, but there are a lot of positions!
But herein lies a paradox: the hard-disk fetches slow the search down so much that competitive chess programs often play worse.
Do these programs simply sit on their thumbs while waiting for disk fetches? If so perhaps they shouldn’t. No natural law requires that the game tree be traversed in depth-first order!
On further review, both Wikipedia’s Endgame_tablebase article and the Winboard FAQ have the minority (i.e. wrong) definition of DTC. DTC also includes “conversion” by either side promoting one or more Pawns.
The practical difference is that to generate a 7-piece tablebase by proper DTC, one needs to have not only all the 6-piece tablebases, but also the 7-piece tables obtained after all possible promotions. Happily there isn’t a vicious cycle: first do all bases with no pawns, then with one pawn, and so forth.
Briefly during the Kasparov-World Internet Match in 1999 and its aftermath, discussions led by Peter Karrer toyed with the idea of regarding any Pawn advance as a “conversion”, specifically when each side has a Queen and a Pawn. There are various other metrics that respect the “Fifty-Move Rule”, which was reinstated for over-the-board play in 1992 after Thompson’s databases had induced the World Chess Federation (FIDE) to make exceptions to it.
Thanks also to the commenter above for the Krabbe’ reference: I may include other references and footnotes in a followup comment later.
A question for our guest IM Regan. In mathematics, computer science and other fields, one often learns about shocking connections between concepts that initially seem very different. Have you found any cases of chess endgames with different material or different structure where there was a surprising or clear pattern connecting the kinds of tablebase wins you tend to find, or an interesting pattern to the best heuristics for superficially different 7-, 8- or 9-piece endgames? (I’m being intentionally vague since I don’t know what I’m looking for as an answer, but I mean patterns that are more specific and different than the sort of general “rook endgame” or “minor piece endgame” techniques that humans use.)
Have you found any particular interesting nuggets of wisdom in your study of computer endgame analysis that you were able to apply to your own play?
The person who has devoted himself to what you ask is Grandmaster John Nunn—his Wikipedia page calls it “data mining from chess endgame tablebases”. That has references to whole books by him. I haven’t noticed any surprising correspondences, or applied them in my own games, but your Q relating to practical play and techniques gives me an excuse to mention current work begun by my research partner Guy Haworth of Reading (UK), which I left out of the article.
Taking the position based on Anand-Topalov as a cue, of course we wouldn’t expect Anand to find 99 perfect moves to mate, especially with the final time control of 15 minutes for the rest of the game plus 30 seconds per move made. But Topalov wouldn’t find perfect defense either. Can we model empirically how human players of varying strengths would play in such positions, and assign a probability of one side eventually winning? Haworth began fitting a statistical model to examples of tablebase endgames that have occurred in real games, which I’ve generalized to all positions. [Right now I’m just emerging from a busy term with time to process data I’ve been taking round-the-clock, which I think will force parameter changes to Haworth’s and mine original models.] So we could potentially say after umpteen probabilistic runs of our fitted model, that Anand would have (say) a 70% chance of winning that position in practice. (But from the first diagram, which is theoretically drawn even after the better 74.Ra4xa3 move, maybe only 20%.)
Then the question along your lines becomes, are there rules by which one can improve one’s chances? This actually was the approach of a two-part article written by Grandmaster Ian Rogers for the US Chess Life Magazine, titled “The Lazy Person’s Guide to Endgames.” In the particular case of K+Q versus K+R, I don’t think the “rule” can be compressed as much as he says—there’s a “third-rank defense” mentioned in the Wikipedia article Pawnless_chess_endgame which has to be cracked first. This was the famous first example in the 1970s where a human chess grandmaster (Walter Browne) played with the queen against perfect tables—and failed to win within the statutory 50 moves! The article’s information on the common K+B+N vs. K and K+R+B vs. K+R endgames is very good, however.
I’ve also been engaged in trying to produce a perfect analysis of a key endgame from the 2007 world championship tournament in Mexico City, where IMHO Vladimir Kramnik’s failure to win that game started the slide to losing his title to Viswanathan Anand. I was called out to analyze it by Susan Polgar (Google her surname + mine + “dissect”) and have amassed 1MB of analysis. Checking and finishing this work has been on-hold for several reasons, among them two bugs in the Rybka 3 program whose correction was left to the impending release of Rybka 4 (I hope!). This is the most intensive case ever of the chess search problem, starting with K+B+4P vs. K+N+4P, and I’ve found several gorgeous wins (well, I believe they’re wins) and general principles along your lines. The most practical one is that with pawns e5,f4,g3,h5 vs. Black’s f5,g6,h5, light-square Bishop vs. Black Knight, the positions where Black’s Knight can reach h6 are (I believe) the only ones where he draws.
Typo: I meant pawns e5,f4,g3,h4 for White, not h5. Regarding your first note about “shocking connections” in CS/Math, my research has tried to act on the premise that the combinatorial issues underlying P vs. NP (or at least determinant vs. permanent) may already have been implicitly resolved by work in algebraic geometry, wherein also one finds potential hardness predicates of complexity that surmounts the “Natural Proofs” barrier. This has even involved the math-not-chess work of Emanuel Lasker, specifically the Lasker-Noether Theorem.
That’s amusing, can you see that behind the mathematical jargon you are actually trying to find a (finite…) data structure which fits the problem?
Once solved this will reduce to a plain data compression scheme.
Meanwhile it seems that everybody is mucking around with no “obvious” direction, only trying what comes to mind, how is human intuition different from random search (a.k.a. genetic algorithms/simulated annealing), really?
Well, that’s the 64,000-gigabyte question: can we improve on the data-compression schemes currently used? As for current directions, the most extensive work I know along lines in my post is this PhD thesis by Jesper Torp Kristensen, working at the University of Aarhus under Peter Bro Miltersen, a well-known complexity theorist. The thesis references earlier work by Ernest A. Heinz on rule-based table encodings.
Can you assume that most games will start in a certain way, and so rule out many initial moves? Presumably evey grandmaster game has been run through a system to see which moves were made, to see where these lie, to cut down on calculating the start positions up to x moves ahead? Obviously this would mean some starting game positions would be missed, but it’d be interesting to see if the computer could at least define optimal initial strategies for all known starting patterns GMs have up to this point used?
e.g. you wouldn’t see a GM game where they moved all their pawns out 1 before moving to other pieces?
In some cases yes—there are so-called “tabiyas” even past Move 20 that have effectively been the starting position for tens or hundreds of master games. On the other hand, there is still original ground to strike even in the first 5 moves, e.g. 1.e4 d5 2.exd5 Qxd5 3.Nc3 Qa4 4.d4 Nf6 5.Nf3 Ne4!? By the way, I can’t find my source for my Fischer reference at the end, but I recollect the moves as 1.Nf3 Nf6 2.g3 g6 3.Bg2 Bg7 4.O-O O-O 5.d3 d6. Fischer thought the natural 6.c4 or 6.e4 would each have weakening drawbacks, while 6.Bg5 runs into 6…h6! and slower moves also make commitments Black can try to exploit.
Fischer was so disquieted by encyclopedic opening “theory” that he introduced FischeRandom Chess, whereby both players get the same random pick from 960 starting positions of the back row with Bishops of opposite colors and King between the Rooks. I advocate letting the players deterministically choose independent configurations, with White introducing one piece onto the back row, then Black, then White—as first suggested by David Bronstein, but using Fischer’s generalized castling rule (linked on Hans Bodlaender’s “Chess Variants” website). Capablanca worried almost a century ago that chess openings were getting “played out”, but now I worry we may have the technology to actually play them out…
Having my computer “define” the above “tabiya” positions will be an important test of my statistical model, to see if the %s of human masters choosing respective moves agree with my model’s predictions. I haven’t definitively fitted the model yet—this term I’ve found what seems to be a universal human log-scaling law, which must be applied first to “correct” the raw data from chess programs.
This raises a concept discussed before, namely descriptions of circuits that take an index {i} as (auxiliary) input, and need to output (only) the {i}-th bit of the function value.
This is reminiscent of the Bailey–Borwein–Plouffe formula (which has a Wikipedia page) which in turn is a fine example of a topic that was recently discussed on the Fortnow/GASARCH blog, namely, is mathematics (sometimes) an experimental discipline?
Also, thank you, Ken(s), for a great column … the Anand/Topalov match was wonderful!
I jumped on Wikipedia and read the article, but it was a lot like walking through pudding: slow going and afterward I felt kinda dirty.
BBP is has something of the feel of a amazing card trick, as contrasted with a deep theorem (which perhaps says something about the nature of i-th bit theorems) … but heck … aren’t some “mathematical magic effects” so amazing, as to constitute pretty good theorems?
See http://rjlipton.wordpress.com/2009/03/15/cooks-class-contains-pi/ for my two cents on their cool result.
Thank you for the wonderful article.
“There have been several papers in the past few years on the problem-solving power of deep strings, in general or specifically those that are witnesses for SAT.”
Can you give some references?
The papers I have in mind include Luis Antunes, Lance Fortnow, Alexandre Pinto, and Andre Souto, “Low-Depth Witnesses are Easy to Find”, Antunes-Fortnow, “Sophistication Revisited”, Eric Allender, Harry Buhrman, Michal Koucký, Dieter van Melkebeek, and Detlef Ronneburger, “Power from Random Strings”, and most recently by Allender, Koucký, Ronneburger, and Sambuddha Roy, “The Pervasive Reach of Resource-Bounded Kolmogorov Complexity in Computational Complexity Theory”. They are all Googlable; I linked the latter two in the earlier post referred to on this blog. (Two links causes moderation, so that’s my one.:-)
Other authors to Google for work on chess endgames include Eugene Nalimov, Marc Bourzutschky, Yakov Konoval (all Microsoft), Ernest Heinz (MIT), Guy Haworth (Reading, UK), Aaron Tay, Kirill Kryukov, Stefan Meyer-Kahlen, Lewis Stiller.
While I think it might be possible Anand did calculate to the king pawn endgame, I still doubt that he actually did. There were shorter, more forcing lines after Kh7 in place of Kg7.
However, being curious about what a chess engine might say about the position, I just downloaded Shredder 4 and put in position in question. It identified the winning king and pawn endgame in less than 10 seconds, right up the the point that even a patzer like me could see in a a second that it was won for black. However, the really interesting thing to me is that it only evaluated this position as a black having a slight edge. If bloggers were fooled, they were fooled because they didn’t even take the time to actually look at the engine’s calculated position, but only looked at the erroneous valuation number. Even more curious, as I forced the engine to it’s own calculated outcome, it wanted to resign. There seems to be a bit of a software problem here.
Subsequent to the post, I read a comment on the ChessNinja “DailyDirt” blog to the effect Anand said “I almost had a heart attack when I saw 40…Kh7 41.Rh8+!”—you can find it by Google. I haven’t taken time to play the video this apparently refers to, for his exact words. However, from the comment’s followup “but, luckily, he had Kg7-Kh7” [after 41.Nf5+], I maintain my inference that he did see down to the K+P endgame at that move.
While the game was still going on, in my chat remarks on the PlayChess server (which is Europe’s main answer to the Internet Chess Club), I took a look at 40…Kh7. Of course engines see right away that Black is winning. However, the opinion I voiced during the game was that those lines would look scary to a human player—exactly what I said is that a position is reached where it is rather remarkable that White has no more checks. Whereas, the line to the K+P ending is quite forcing.
You are exactly right as to why bloggers were fooled. I was following the game using a version of the Toga II engine which its programmer, Thomas Gaksch, made specially for me to streamline the concept of depth by having minimal search extensions. Toga II initially gave “0.00” after 40…Kg7 for about a minute (single-core of a quad-core Intel Mac Pro running Windows), then wised up to “-1.66” after 41.Nf5+ Kh7 was played, then gave huge eval to Black as it got past depth 20. Other people reported that Rybka 3 finds the win with a huge eval quickly—one even opined (ridiculously IMHO) that this proved one of the erroneous bloggers did not use Rybka! I haven’t yet taken time to do a comparison of various engines, the way I have here of the famous Kramnik-Anand …Ne3!! move in 2008. I do try to do more creatively with engines while commenting on games in real-time, looking at the positions as you say, and exploring alternatives to the move the engine likes in order to ferret out the ideas in a position.
I’m intrigued by your final sentence. Can you reproduce the behavior? What are your hash-table settings, do you have tablebases attached, etc.? Shredder’s author gave me credit for confirming a bugfix he’d earlier made when I reproduced Shredder 9.0’s famous blunder of a Bishop in a game in 2005 against Pablo Lafuente. This was ascribed to a hash-table collision. Chess engines do open-address hashing with no probing because speed is king and errors rarely propagate to the root of the search tree. I can reproduce collisions by several engines in some tricky positions, most notably 8/1r2K3/8/3N4/8/2Q1B3/4q3/3k4 w – – 0 1 (WKe7, WQc3, WBe3, WNd5, bkd1, bqe2, brb7, White (in check) to move) and its other 15 permutations. I have a pie-in-the-sky idea that this behavior can be abstracted and leveraged into a concrete test for pseudorandomness of strings on the order of 50,000 bits. I don’t own Shredder 4.
Ken,
I don’t really have complete answers to your questions since I am a complete novice to chessprograms beyond the old Chessmaster version for PC. I have basically a barebones version of Shredder 4 that was a free, unregistered 30 day trial. I reran the position, and it still only evaluates the line up to Kd3 (after Nf5 Kh7) in the king pawn endgame as -0.84 (hash 99.9%) (is this upper hand to black or slight advantage?). This would suggest to me that tablebases are not attached to this version since the postion is a clear win for black. After forcing through x. Rg3 Rg3, hg3 the engine, calculates one move past Kd3 (hash 99.9%) and gives an evaluation of -0.85. The position following Re2+ is evaluated at -1.38 (hash 99.9). After Bg2, the evaluation is -2.73 (hash 99.9%). After Kg2, in the king and pawn endgame Topalov chose to avoid, the evaluation is -13.09 (hash 99.9%). After black plays Kd3, the evaluation is -18.02 (hash 97.2- I got tired of waiting). I hope this clarifies it a bit.
Oh, and thanks for the info on what Anand had to say about it. This confirms he did choose this line freely and not by mistake (in other words, he did see Nf5), though I still wonder if actually saw white playing Rg3 instead of the immediately losing Ne7. In any case, I still find it somewhat surprising that he thought Kh7 Rh8 was very bad for him. However, I don’t think like a grandmaster thinks.
I would like to mention a related post on computerized chess from my blog. The guest blogger was Amir Ban who created with Shay Bushinsky “deep junior” one of the best chess-playing programs. http://gilkalai.wordpress.com/2008/06/25/amir-ban-on-deep-junior/
Indeed the questions raised by the automated chess playing programs are fascinating.
Ken’s perspective on Ken Thompson and Endgame Tables is interesting, and he revives some current issues.
The ICGA Journal (v24.2, June 2001) is afaik the best review of Ken’s contribution to Computer Chess – covering his input to the ICCA (now ‘the ICGA’), to chess engines, opening books, machine-reading of chess texts and endgame tables (EGTs).
The number ‘8’ has a certain allure in the context of a game on an 8*8 board, so my challenge is to see 8-man EGTs completed in due course. I can’t see beyond that at the moment.
6-man EGTs to the DTM metric have been promulgated, 7-man EGTs to the DTC(onversion) metric produced, and 5-man EGTs will shortly be promulgated to the DTC, DTZ and DTZ50 metrics.
No EGTs have been produced in ‘Pawn slice’ form (each slice having fixed Pawns). This is an obvious parallelisation approach, but no Chess-EGT-generation code has been produced to reliably exploit ‘clouds’, clusters-machines or even SMPs.
A minor irritation is that depth is measure in winner’s moves rather than plies (to save 1 bit, or just an early economy that took root?).
Some progress has been made in turning data into information, knowledge, insight and wisdom. As KR says, John Nunn is without peer here, and his second trilogy on the Endgame is in the course of publication now. Amazon advertises two of the three books, as well as the earlier ‘Secrets of …’ trilogy.
As for models of Fallible Play, my earlier work confined to the game where EGTs existed was generalised in 2007 in ‘Gentlemen, Stop Your Engines’ – a title not to the taste of the ICGA_J editor but totally on the money for me.
http://centaur.reading.ac.uk/view/creators/90000763.html , UoR’s institutional repository, is a convenient source but hasn’t worked back to my earlier material on this yet.
As Ken says, we have models of Fallible Play for the whole of Chess, but we haven’t finalised a way to systematically improve these models. We have a ‘spectroscope’ characteising quality of play, but we do not yet have a systematic way of improving our spectroscope.
gh
This is cool. There is an analogous situation in some Go endgames, where there turns out to be a rule discovered by computer research and learnable by humans, that enable the player to find wins in positions that the best Go grandmasters had previously thought were draws. See “Chilling Gets the Last Point” by Elwyn Berlekamp and David Wolfe.
“At Move 40, Anand calculated 11 moves ahead…. Many computer programs seeing only yea-far for minutes thought Anand’s move was a blunder allowing a draw” Computer chess programs are not designed to win end games. Chess is really 3 games in one — first there is the opening, then the middle game and then the end game. Most opening books will start the programs to an even start (if not they would evolve, this is cumulative chess knowledge) Then the middle game is where the high stakes are, a good end game is like a photo finish. Programmers designing their programs to win concentrate on the middle game for economic reasons. No great end game will fix an even small blonder in the middle game. In the referenced game it was over at move 31 or 32 at the most. No program (over 3000 elo) would have lost as Black the game was sealed. And even if they would not recommend move 40 for Black they would still win with their solutions. So the imperfection is in the valuation for end game, a very minor problem for a program — a runner running for a photo finish where her opponent if far behind will still win.
The TB field is developing more than you think. A guy named Volodya last November said he built the DTM version of the famous 517-move win in about 12 hours, but didn’t say how. Bourzutschky said it looked authentic. This seems almost possible if he has a huge memory (512/1024GB? maybe 128/256GB with more thought or compression in RAM?) and a 16 or even 48 cpu machine. The main deal is that no one save these 7 pieces endings, as they are too clunky. If you work offsite on a huge machine, getting the data back to your own drive is not obvious always.
The new RobboBases look to build the 6-piece endgames using only 16GB of RAM in about a month on an 8-cpu machine (the code came out last week, so it’s still running for me). This is way more efficient than a disk-based build, where even streaming I/O is way too slow to keep the cpus busy. They only take half as much as space as Nalimov because they use DTC and only indicate win-draw-DTC. de Koning already used this superior compression a decade ago in ChessMaster but that was DTM. With a motivated person, I guess the 7 piece bases could be on an array of external drives by the end of next year, though the ones with pawns will need care to make due to promotions. There is another open-source project called Gaviota, but it is only at 5 piece bases, and it more for GUIs than chess engines I think.
But your piece avoids a technical point. Rather than save DTx, you could try to save DTx/(dividend) for EACH position (not just multiples of dividend as you suggest, a comment said the same), and this will compress a lot better due to greater data redundancy. Your article seems to suggest you can take dividend as 5 or 10 maybe, but I really doubt it. The search would have to be able to the next “layer”, for instance passing from a mate-in-20 to a mate-in-15 position. NORMALLY this takes microseconds to search 10 ply, but that is WITH GUIDANCE of heuristics, pruning, history counters, and all that is out the window here. To solve KBN vs K is not hard by methods, but something even like KRNN vs R is a pain. Try to see if computers can win a mate-in-20 roll-out against a tablebase, given maybe a second per move. My bet is no.
There are also “win-loss-draw” bases for playing in real time. These use run-length-encoding. The checkers guys used them first, then Shredder, and now the RobboBases, though no one really has a good 6 piece version working yet. The 5 piece are reduced to about 450MB, or even 150MB in the shalf-search Shredder option. Maybe the 6 piece will fit into 64GB?
Wow, thank you for this very informative comment, which I only noticed now (after personal events, vacation, and the Deolalikar “P != NP” story).
good post
Hi, I will post about this interesting topic in my blog, http://thekingsgame.blogspot.com/2011/07/cracking-chess.html , and I will post about more of this
so…….nice!!!!!!!!!! we can learn so easy u did not know endgame my sir was scolding me now he felles proud of me. THANKS A LOT!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
http://www.youtube.com/watch?v=mwYQRteeHbE
the longest mate ever composed – mate in 550
kindly regards from Germany
Lutz Neweklowsky
write here or to :
lutz.neweklowsky@gmx.de
I am proposing an advanced database capable of being used to solve chess. https://www.kickstarter.com/projects/1239228060/solving-chess-yes-solving-chess-step-1-of-3
Information scientist named Shannon deciphered in 1949 that chess would take 10^90 years to solve on a 1 MHz computer. The Moore’s Law, which not all individuals adhere to, states that computer computing power as well as computer’s storage capacity will double every year from 1949’s to ethernity. In estimation, if Moore’s Law holds thru, there must exist a computer from 300 years (that is 293 years to be exact) that will do as many calculations in one year as Shannon’s 1 MHz computer would do in 10^90 years.
As let to believe by leftist and Fake Media, there is no limitations to Moore’s Law. When Intel introduced 4004 processor in 1971 it was made with 10 micrometer technology. Today’s i9’s are developed w/ 14 nm technology, that is 600x the difference. In photolithography we are now in ultraviolet wavelength of <10nm. In radiation spectrum there are waves that have much shorter wavelength as ultraviolet. For example gamma rays have a wave length of 1 picometer, which is 14000x shorter than modern technology. Similarly where as hydrogen atom is 0,1 nm wide, the quarks are again 200x smaller than that (that is 0,43 x 10^-15 mm wide). There is plenty of room to go with or without quantum computing…
Moore’s Law concerns integrated circuit density – and doubling every 2 years. However, this was also observed to apply to storage and computing performance – Intel noted this doubling every 18 months.
From Wikipedia: “Moore’s law is an observation or projection and not a physical or natural law. Although the rate held steady from 1975 until around 2012, the rate was faster during the first decade. In general, it is not logically sound to extrapolate from the historical growth rate into the indefinite future. For example, the 2010 update to the International Technology Roadmap for Semiconductors, predicted that growth would slow around 2013,[18] and in 2015 Gordon Moore foresaw that the rate of progress would reach saturation: “I see Moore’s law dying here in the next decade or so.”[19]
Intel stated in 2015 that the pace of advancement has slowed, starting at the 22 nm feature width around 2012, and continuing at 14 nm.[20] Brian Krzanich, CEO of Intel, announced that “our cadence today is closer to two and a half years than two”. This is scheduled to hold through the 10 nm width in late 2017.[21] He cited Moore’s 1975 revision as a precedent for the current deceleration, which results from technical challenges and is “a natural part of the history of Moore’s law”.