Beating Bellman for The Knapsack Problem
A general method for solving many problems in exponential time but small space

Daniel Lokshtanov is a research fellow in algorithms whose Ph.D. was on parameterized algorithms and complexity. When I looked at his home page I saw his email address is written in the form:
name [at] somewhere [dot] rest of the address
Of course the point is to “fool” robotic agents, and make it harder for them to collect email addresses for spamming. I have always wondered if this method really works, but at first glance it looked like he had gone one step better. His homepage was even trickier: it says his email is his office location and his phone number is his email. I thought: what a clever trick. But, Subruk pointed out, if I just maximized my browser window all would line up—he was right. Oh well.
Today I will talk about a paper in the upcoming STOC conference on, among other things, one of my favorite problems: the Knapsack problem. The paper, authored by Daniel and Jesper Nederlof, uses a “new” method, and the method yields, in the their hands, some quite striking results.
As with many new methods, the method is not completely new. I sometimes wonder why it is so hard to figure out who invented something. I think figuring out the inventor of a method rather than the inventor of a theorem is even harder. A theorem is a precise statement and acts like a point; a method is a general idea and acts more like a cloud. I can think of many examples of methods whose correct history would be hard, if not impossible, to unravel.
Some of the issues blocking the definitive statement of who invented a method are:
- Sometimes methods are independently discovered in essentially the same form. Until researchers become aware of each others work, it is often hard to decide who did what when. Even a result published in a well known conference or journal can be innocently missed. The amount of material published these days makes searching harder than ever.
- Sometimes methods are discovered in slightly different forms. Even if researchers are aware of each others work, they still may not realize their respective methods are really the same.
- Sometimes methods are discovered in different parts of science. In this case it is quite easy for researchers to have no idea the method is already known. A perfect example of this is probably the various “discoveries” of the quadratic algorithm for the edit distance problem.
The method used by Daniel and Jesper was used previously by Yiannis Koutis—at least both used a very similar idea. So did Yiannis invent the method? I do not know, nor will I try to do a definitive historical study, but will try to point out the beautiful work that Yiannis also did.
Before we worry about who invented the method, let me explain what the method is.
The Method
Suppose you wish to calculate some value 
- Define a polynomial
so the coefficient of a given monomial of
is equal to
- Construct an arithmetic circuit that computes the value of
at any point efficiently.
- Use a fast algorithm to determine the coefficient of the given monomial.
The name, CEM, stands for Coefficient Extraction Method—please suggest a better name, but for today I will use this name.
There are several remarks I will make about CEM. The first two steps, defining the polynomial and the arithmetic circuit, are quite creative. Each application requires that you figure out how to make your value
The CEM method has more flexibility than the version I have given. The ring the polynomial is defined over can be selected in a clever manner too. For example, in some applications the ring is the integers, in some the complex numbers, in others it is a more general commutative ring. The latter happens in the work of Yiannis. This is an additional degree of freedom, and can be exploited to make CEM work to solve your problem.
Another source of greater flexibility is the monomial. In many application the monomial is exactly known. In other applications the monomial is only partially known: for example, the key value may be the coefficient on any monomial of the form

where all the exponents 
Constant Term Method
As I have already stated, it is often the case with a “new” method, there is an older method quite similar in spirit to it. The constant term method (CTM) is used in combinatorics to enumerate many interesting objects and is very close to CEM. The CTM method uses a Laurent polynomial 

is a perfectly fine Laurent polynomial. Note, the constant term of 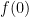

A famous example, of this is the Dyson Conjecture: the constant term of

is equal to

The conjecture, now a theorem, was made by Freeman Dyson in 1962—it arose in a problem in particle physics.
There is one fundamental difference between CEM and CTM, besides the simple difference: CEM allows any coefficient and CTM always means the constant term. In combinatorics almost always one wants an expression for the term; in complexity theory one is usually happy with an algorithm for computing the term. We do want efficient algorithms, but do not need or expect the term will have a simple closed form expression, we might even allow small errors. In combinatorics the closed form solution often gives additional insights: for instance, using a closed form may allow a simple argument about the parity of the coefficient.
Applications of CEM
I would like to give two basic applications of CEM. As usual please see Daniel and Jesper’s paper from STOC and Yiannis’ paper from ICALP for details and exact statements.

Consider the subset sum problem: Given a set 


![{[n]}](https://s0.wp.com/latex.php?latex=%7B%5Bn%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

where 

The key is that the coefficient on 

where 

together and yield
It is easy to see that this polynomial has an efficient arithmetic circuit, and thus CEM can be applied. Pretty neat.
The second application uses a generalization (GCEM) of CEM: the detection of any multi-linear term in a polynomial whose coefficient is odd. Consider the 

A Lemma
I will present one sample lemma—see the papers for details on how to solve CEM and GCEM.
Given a polynomial 


and 


While I will not state the lemma Yiannis uses in any detail, there is one aspect of his lemma I really like. As I stated before the methods can use different rings—they need not be restricted to integers or reals or even complex numbers. In Yiannis’ work a trick he uses is to work over a ring that has nilpotent elements: recall
Open Problems
The main open problem is can we use CEM to solve some other open problems? I am trying to use the method to solve some old problems, but have not had any success, yet. The method seems quite powerful, and I hope you can use it to get new theorems. Good hunting.


I would really like to the papers, but unfortunately I couldn’t find the STOC paper anywhere online. Any hints on this? Is there a publicly available preprint?
I believe they have yet to post the final paper. I will ask them to do so.
Nice! I really like this.
One thing I don’t understand is WHY this ends up saving space over other methods. Probably I need to read the paper, but is there some intuitive “moral” reason why computing this coefficient should require less space than say dynamic programming?
Or is it just something that falls out of the analysis.
Yes. The algorithms to get the coefficients use a Fourier method. This requires a large summation to be computed, but the sum does not require much space.
Aaah, thanks that makes sense! Should have guessed something to do with Fourier (what else would it be…).
I’ll definitely try to take a look at the paper once it becomes available.
We do see the “CEM” method in combinatorics and number theory all the time: it shows up often when you have generating functions.
for example, the fibonacci-style recurrences (which gives an exact formula), the riemann-zeta function (to get the prime number theorem) and euler’s partition identity (to get the asymptotics of the partition function).
The amount of material published these days makes searching harder than ever.
But today we have the Internet. And google.
Sorry, I know this isn’t the point of the post, but I have to say I wish people wouldn’t munge their email addresses that way. First, it makes it harder for me to contact you, because I have to go to significantly more trouble to type in your address compared to just clicking a mailto: link. Second, it’s incredibly easy for a spammer to just hardcode some patterns into a crawler to match all the standard munging attempts. And it’s not that hard to have it learn new patterns—the cost of a false positive isn’t very high, after all. Finally, I somehow doubt that many spammers are even doing that anymore. The ROI seems awfully low compared to just buying a list of email addresses.
As a personal anecdote, I’ve had my email address on my dept web page with a mailto: link for a few years, and I have mailto: links with my email address in quite a few other places as well. Yet I hardly get any spam these days.
The biggest spam I get is to the blog. Some robot likes my blog and I get the same spam every day.
I heard Ryan Williams give a talk at Dagstuhl on a follow-up work with Koutis in ICALP 09– very neat stuff.
Obfuscating email in an academic home page is useless. It can be easily extracted from the URL of the page itself, (for example if your home page is http://www.cs.princeton.edu/~rjl, then your email id is either rjl@cs.princeton.edu or rlj@princeton.edu).
In Dan Lokshtanov’s case, homepage is http://www.ii.uib.no/~daniello, hence the email id is daniello@ii.uib.no which is what he had put in obfuscated form.
There is no use of having a re-captcha or an image either. Academic email-ids can be got from the homepage urls directly without even fetching and parsing the page.
I wrote about this last year: http://gbalag.blogspot.com/2009/10/email-obfuscation-is-broken.html.
Thanks for this info…
About an online copy;
We are currently working on making the paper considerably better written than the submitted version. The idea was to put that up when it is done -before STOC final version deadline on march 30th. However we might put up the submitted version with a disclaimer anout reading at your own discresion… will post a link here if we do.
About other algebraic exponential time algorithms;
I recall that in last years ICALP there was a paperof Marek Cygan and Marcin Pilipczuk that used fast polynomial multiplication to do fast subset convolution, instead of using Moebius inversion as in Björklund, Hushfeldt, Kaski and Koivisto (STOC07). Also, for TSP there seems to have been an I/E & generating function attack already back in 77
by Kohn, Gottlieb and Kohn: A generating function approach to the
traveling salesman problem. In: ACM 1977: Proceedings of the 1977 annual
conference, pp. 294–300. ACM, New York (1977)
They observe that the coefficient of the smallest order term of a polynomial
can be found by evaluating the polynomial at a sufficiently small point.
They dont argue about what precision is needed and do some experiments.
I’ve been trying to see whether some poly(n,log w) (where w is max edge weight and n is #vertices) significant bits can be sufficient but it doesnt look like it at a first glance. Anyway, this seems to be the earliest reference i could find for “probing a polynomial for a coefficient”.
I am very pleased that people are reading my 1977 paper. I thought the paper was ignored.
The work is somewhat outdated in line with my present unpublished work.