The Iceberg Effect in Theory Research
The iceberg effect in research: how theorems can be lost

Fred is my favorite name, when I need a “random” name. You might have also noticed that the picture is not even a picture of a person—it’s an iceberg. I will explain why in a moment.
Usually I talk about real people, but today I thought I would use phony names to protect the innocent—or at least protect my friends.
I plan to talk about an issue that comes up in research:
Is the fact X a new result? Or is it a known result?
At FOCS, a great researcher, who I will call “Fred,” asked me if a certain theorem, he had just proved, was new. He did this in the hall right outside one of the conference rooms, which did not allow us much time or any blackboard for drawing pictures. His result concerns a clever algorithm that yields a neat approximation algorithm to a well studied problem. He asked me and others if it was “new.” My immediate response was that I knew a related theorem, but that Fred’s theorem seemed new to me.
Moreover, Fred’s theorem seemed to generalize the known theorem, which made me excited so I began to write an entire post on his result. In the post I talked about his theorem, its proof, and how it differed from the old known result. In order to do the latter I had to Google until I found the old paper. This was not a completely trivial task, since the paper was so old. I try to be careful in how I cite papers and wanted to see the original. That is where I hit a snag: his “new” theorem was about 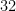
The Iceberg Effect
The confusion about whether or not Fred’s theorem was new could be traced to what I will call the iceberg effect. Often an author may write up a paper that becomes famous for some theorem T. But also in the paper there are other theorems, which are not nearly as exciting as the main theorem T. Over time everyone knows T, we teach T to our students, we use T in our papers, and T becomes part of the fabric of theory.
The problem is that T is like the visible part of an iceberg. We see the tip, T, that is above the water, but the part below, the other theorems, are soon forgotten. They may be quite clever or hard to prove, but people just know about T. This is where the iceberg effect hits. You prove a “new” theorem, which is not new—it’s part of the invisible theorems that are below the water line.
This is exactly what happened to Fred. He lost a theorem, and I lost a post. Oh well.
Other Effects
There are many other effects that make it hard to know for sure that something is new. I think that this problem is less of an issue in “hot” areas, since the results are fairly recent.
For results that are older the iceberg effect and other effects can be a major problem. There are so many on-line papers, workshops, conferences, journals, and other sources of information that it is easy to overlook something. This is not unique to theory, but it is an issue that we need to work on.
The Theorem In Question
Dick Karp proved a theorem about TSP for random points in the unit square. His theorem is based on a famous result of Jillian Beardwood, John Halton and John Hammersley who prove that the length of the optimal TSP tour for uniform independent random points in the unit square is 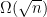
Karp proved his famous result in this paper:
Theorem: Let
random points be in the unit square, and let the length of their optimal tour be
. Then, there is a polynomial-time algorithm that given the points finds a tour of length
so that

Since the optimal tour is
This is the T result. The “new” theorem was:
Theorem: Let
What Karp proved in his original paper is much stronger than his theorem on random points, which is the T result that we all remember. He actually proved the new result in one of his below-the-waterline theorems. He proved exactly the above theorem, but it was stated in slightly different language:

For a more recent treatment of Karp’s result check out this.
The Proof
I will include a sketch of Karp’s theorem, with a weaker bound. Actually, this is how Fred sketched his “new” result, when he spoke to me in the hall. Check out Karp’s paper or the notes for the better bound. The key ideas are all here, however.
Suppose that 
The algorithm has three steps.
Step 1: Divide the square into small square cells of side 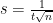




Step 2: Next divide the square into large square cells of side 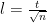

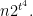
If 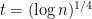
Step 3: Finally, connect all the large cells together by a simple path: the path snakes across each row of large cells. The total length of this path is linear in the number of rows of the large cells, 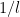
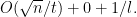
Since 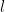
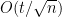
Open Problems
I may be alone, but I often run into this question of what is known. The iceberg effect is one barrier that I have hit. But there are other issues. Can we do a better job of making sure that we do not re-invent what is known?
Or was it really known if top researchers did not recall Karp’s “other” result? Perhaps the outcome here is good—I had forgotten that Karp’s ideas worked just fine for any collection of points. So perhaps the whole affair has worked out just fine.


Can we do a better job of making sure that we do not re-invent what is known?
You could if you had a way to “Google thru” the semantics of previous results, provided of course that they were archived somewhere on the web AND that there were some encoding conventions for formalized mathematics.
Unfortunately this doesn’t seem to be a topic of much interest among “garden variety” mathematicians.
A recent attempt at such an endeavour at the n-Category Café has degenerated into hair splitting and holy wars about “proper” foundations and existence v/s definedness (re Feferman).
Mathematicians don’t seem to understand that natural language comes before mathematics and that figuring out how mathematics “emerge” from informal discourse could bring some insights into actual practice.
Oh, except may be Charles Wells, partially.
I can’t help but think of your previous post ( http://rjlipton.wordpress.com/2009/09/04/counting-cycles-of-a-permutation-in-parallel/ ) that brought up Rota’s advice to “publish the same results twice.” I think some of the issues with the iceberg effect you’re talking about, and the furor over Rota’s advice stem from a common misunderstanding. The phrase “result X is known” suggests two properties that everyone should agree aren’t true:
infinite shelf-life: the result X is unknown, since the beginning of time until someone publishes a paper, at which point it becomes known till the end of time.
collective memory: if someone knows the result X, then everyone knows X.
Perhaps we would have a very different outlook on research and publications if we agreed that “X is known” is a non-sensical phrase and instead resorted to saying things like, “X is known by most theorists”, “X used to be known by every school-child, but is now of consequence only to specialists and historians.” What would novelty mean without the phrase “X is known”?
I think your point is right. If the Karp result had been published more than once than you are probably right—that we all would have known it.
We had a situation similar to that: we made an interesting observation on a well studied problem. A handful of leaders said: “we all knew that!” while everyone else, including people who work in the area said “we never noticed that fact, neat!”. The experts could not point to a written source.
Was it known? Can it be published? As you say, the answer depends on the meaning of the word “known”.
The paper containing the observation eventually got published using carefully chosen wording about its novelty: “possibly observed earlier by others, yet never before stated in print”.
This is a very interesting story. I think we need to be very careful what we mean by “known”.
I was sort of hoping that the punchline to all of this would be that Fred was Dick Karp. I seem to recall a story (probably apocryphal, or maybe I’m convincing myself that it’s even a circulating story, since I can’t remember any names!) about some elder statesman of mathematics who needed a particular lemma, and spent weeks trying to prove it, only to discover when he checked the literature that he himself had proved it decades earlier…
Anyway, this is one of the things that the math/TCS community as a community good for — if a “below-the-waterline” result turns out to be useful, someone else will likely have used it before! Sometimes, of course, it gets elevated above the waterline (see Szemeredi’s regularity lemma), but even when it doesn’t, I think that good results tend to float upwards, and bad ones tend to sink.
That’s funny. I have heard that others have forgotten their own results, but never Dick.
This post is very interesting. I think the terminology “The Iceberg Effect” has been used before for the impact of the four color theorem on mathematics by William T. Tutte by proclaiming: “The four-colour theorem is the tip of the iceberg, the thin end of the wedge, and the first cuckoo of Spring” [1],[2]. I think the context here “The iceberg effect in research: how theorems can be lost” is a bit different than Tutte’s saying but pointing the same conclusion.
[1] B. Mohar, “V12. The Four-Color Theorem”, in The Princeton Companion to Mathematics, ed. T. Gowers, Princeton Univ. Press, 2008, page 698.
[2] A.M. Hobbs and J.G. Oxley, “William T. Tutte (1917-2002)”, Notices of the AMS,51(3), March 2004, 320-330.
Interesting post, as always.
Funny thing regarding this “known/unknown” result: I knew about the theorem for arbitrary points but not, as such, for random points. It is actually covered in our graduate course on network algorithms, delivering a stream of people knowing it. (Or at least a stream of people having, at some point, heard about it, which is not quite the same.)
I have heard from a researcher whom we will just call Fred that the famous “Cook’s theorem” was not even present in Steve Cook’s submission to STOC, and that he added it as a “freebie” in the Proceedings version. Anyone know if this is true? If so, wonder what that under-the-iceberg theorem was, the one that STOC accepted.
Actually, the point made in this blog entry is far more serious, as it is often the case that the same theorems are proven in different fields of computer science and/or mathematics independently.
Nobody can expect, for example, a PhD student in formal logics to know all fundamental results in somehow related branches, like, let’s say, graph theory. At the same time, nobody can expect this from her/his advisor, as knowing about all these subjects is simply too much to expect.
Despite these facts, papers get rejected at conferences if they prove something which is a (not too difficult) corollary of previously known results in other branches of maths/CS if a reviewer happens to know it. This makes the whole reviewing process a matter of luck for quite a couple of papers.
This basically leaves us with two possibilities: We can either accept that publishing and thus, one’s success in academia is heavily influenced by pure luck (even more than it already is without this issue). On the other hand, we could allow re-publication of results in a way that is more accessible to the individual communities and just have the reviewers asking the authors to add a note in the paper.
On an aside note, one could introduce a system that paper authors need to ask some well-known players in their field for an “OK” before being allowed to submit a paper to a conference or journal and if they all say “yes”, ignore this problem as the original result was then highly likely to be too unknown for the community and deserves re-publishing. However, who of them has enough time to do so? And guaranteeing fairness in this process is a matter on its own.
I like your point very much. If many do not know a result is it really known?
Contrary to RT, I don’t consider this much of a problem. It’s not nearly as hard to figure out what’s known as some people imagine or pretend; the issue is that some researchers don’t want to learn a disappointing answer, so they put very little effort into finding out. The only problem is that some of them get away with their lazy approach. There are various principles that should guide people:
(1) Try to figure out what’s known before investing lots of effort (so you aren’t emotionally committed). If it’s worth spending months of effort solving a problem, then surely it’s worth spending multiple hours trying to figure out in advance whether someone already knows the answer. If you don’t care enough to do that, then maybe it’s not such an important question.
(2) After you solve the problem, you should try again to look it up, since sometimes knowing the answer really clarifies which community might already have figured it out. An ethical researcher should try hard not to let their desire for it to be new bias their search.
(3) It’s never sufficient just to ask your friends or close colleagues whether they know it. A proper search will often involve writing to experts in other fields (as well as looking at material not available on the web).
(4) This is especially important in interdisciplinary areas. If you work on algorithmic game theory, you should never say “But who would have thought economists might have published on this?”
If many do not know a result is it really known?
Who are the “many”? If there’s a large community of people who have worked for a long time investigating a problem, and they haven’t figured something out yet, then there’s a big benefit to bringing it to their attention, although it is ethically important to frame it right (and not to claim excessive novelty for it).
A more common scenario is that the many who didn’t know it have not spent much effort working on it. Instead, they are a tangentially related community whose interests are gradually expanding in a direction that overlaps with some other group. In this case, you shouldn’t expect a lot of academic credit for the observation that this line of work isn’t new, but that’s no excuse for sticking your head in the sand.
AAAI allows for submission of known results which are relevant to AI but unknown in that context. However the paper should explicitly state its sources and concentrate on describing how and where it is applicable within AI. The threshold for this type of papers is rather high.
Dick:
I did know this result of Karp and it was an inspiration for my work on Euclidean TSP, which as you know gets a multiplicative approximation instead of additive. My favorite result in Karps paper is what I called the “Patching Lemma” in my paper. Again, it was just hidden as a simple lemma in there. I once asked Dick Karp if he was the first to discover the patching lemma and he couldnt recall if he was. I think there was already a large body of folk theorems about TSP by the mid 1970s.
Sanjeev
Many institutions limit access to their online information. Making this information available will be an asset to all.
It is impossible to know everything that is known about, or even relevant for, what you are working on. Perhaps vdash
http://www.vdash.org/
will evolve into a substantial assistant for this.
This reminds me a bit of a problem related to the infinite library thought experiment.
In an infinite library containing all the possible books of a certain N dimensional character set, arranged naively with respect to the contents of the books, a search path for finding any given book will contain as much information as the book itself – There would be no practical difference between finding the book and authoring it yourself. So, all the information in the world is actually as useless as no information at all!
Of course, we are nowhere near an infinite library. But I wonder if, due to our finite efficiency of search, we will saturate eventually in terms of information content that’s “out there” somewhere. Obviously the simplest stuff to prove will become inefficient to find first, progressing to more complicated bodies.