Simulation of Nondeterministic Machines
How efficiently can a deterministic Turing machine simulate a nondeterministic one?

Dana Scott and Michael Rabin shared the Turing award in 1976 for their seminal paper on finite automata, where they introduced the critical concept of nondeterminism. Without the notion of nondeterminism, there would be no P=NP, there would be no polynomial time hierarchy, there would be no 
I have talked about Michael, one of the greatest theoreticians in the world, before. See my earlier post for more details on his great work.
Dana Scott has also done terrific work, in addition to his Turing Awarding winning work with Michael. Dana is probably best known for his deep work on various aspects of set theory and logic. Dana did early work on set theory and helped with the understanding of Paul Cohen’s notion of forcing by introducing Boolean Valued Models of set theory–along with Bob Solovay. Dana has also done seminal work throughout model theory and set theory; for example, there is the notion of a “Scott Sentence” in logic.
One of Scott’s great results was a semantic basis of programming languages, the so called denotational semantic model. This is a wonderful result, that reminds me of a time years ago
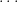
When I was at Berkeley, as faculty, in 1979, Dana was visiting Xerox Parc near Stanford for a few months. One day I planned to visit him and just my luck that morning my car broke down. I remember calling him to apologize that I would not be able to visit that day, since I had no way to get there.
Ann Yasuhara, who was also visiting Parc and is a good friend of mine, called me and said that I really needed to come: she said essentially “failure to appear was not an option.” I really wanted to ask Dana a question about non-standard models of arithmetic, since Rich DeMillo and I were working on an approach to showing that P=NP was independent from Peano Arithmetic. So I discovered that Berkeley had “rental-like” cars that a faculty member could sign out for the day. So I got one and off I went to see Scott.
The meeting with Dana was unusual. After saying hello, Dana immediately asked me to explain the basis of his theory of denotational semantics. It was clear I better have a good answer. Luckily for me I had just read a section from the “Handbook of Mathematical Logic” on his work, and could answer Dana. If it were today, I could not have said anything about the theory, but then I did fine. Dana smiled and asked me what was on my mind. I asked him my specific question on model theory–the reason I was visiting. Dana said nice problem, but he had no idea how to solve it. The rest of the afternoon was fun, we discussed many topics. I never did figure out what would have happened if I was unable to answer his question.
Today, my question, is what is the best way to simulate a non-deterministic Turing machine that runs in time 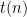

where 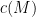

A Conjecture
I tend to believe that P could equal NP, or at least I do not believe that it is “obvious” that P=NP is impossible. My goal is to get you to think about proving the far more modest conjecture:
Conjecture: For any
,

I definitely believe that this could be true. Note, it would not have any dire consequences, it would not change the relationship between major complexity classes, but it would show that nondeterminism is “weaker” that we think. However, what we can prove today is vastly weaker than this, but I would like to show you a possible approach. Perhaps together we can prove the conjecture: it may be within our grasp.
The Standard Simulation
The following is a classic theorem:
Theorem: Suppose that
is a multi-tape nondeterministic Turing machine that runs in time
. Then, there is a deterministic machine that simulates
for a constant
.

The proof of this theorem is well known, but I thought I would sketch it for comparison with a better version that I will present in a moment. This simulation is based on the simple observation that in natural way a nondeterministic machine 

The problem with this method is that the constant
A Better Simulation
Theorem: Suppose that

The critical point of this theorem is not the exact constant 
I think that the constant is not even close to the best that we can get with the technology that I will outline. But the key insight is this : unlike all the usual simulations, this technology does not depend on the number of states of
The Simulation Details
I will now sketch how the simulation works. Let 
![\displaystyle [ s, x_{1},x_{2}] \quad \rightarrow \quad [s', y_{1},y_{2},m_{1},m_{2}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B+s%2C+x_%7B1%7D%2Cx_%7B2%7D%5D+%5Cquad+%5Crightarrow+%5Cquad+%5Bs%27%2C+y_%7B1%7D%2Cy_%7B2%7D%2Cm_%7B1%7D%2Cm_%7B2%7D%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
where 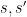






The meaning of a rule is: if the finite state control is in state 



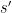





Note, that since the machine 

Our plan is to exploit the structure of the Turing tapes, and thereby reduce the cost of the simulation. For this it is useful to have two types of partial traces of the machine’s computation. Let 

A strong trace 

![\displaystyle [ x_{1},x_{2}] \quad \rightarrow \quad [ y_{1},y_{2},m_{1},m_{2}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B+x_%7B1%7D%2Cx_%7B2%7D%5D+%5Cquad+%5Crightarrow+%5Cquad+%5B+y_%7B1%7D%2Cy_%7B2%7D%2Cm_%7B1%7D%2Cm_%7B2%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002)
where
A weak trace
![\displaystyle [ y_{1},y_{2},m_{1},m_{2}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B+y_%7B1%7D%2Cy_%7B2%7D%2Cm_%7B1%7D%2Cm_%7B2%7D%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
where
Note, both strong and weak traces always start from the beginning of the computation. Also the next lemma uses the following simple property of Turing tapes: the symbol written at location 
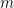

A key lemma is the following:
Lemma: A weak trace uniquely determines exactly one strong trace; moreover, given a weak trace in polynomial time the strong trace can be constructed.
Proof: The only information missing in a weak trace is symbols that were scanned at the beginning of the time step 
Case 1: This is the first time, the location is being visited. In this case the symbol is easily determined by its location. It is either a blank or an input symbol.
Case 2: The location had been visited previously. Then, the symbol seen at the beginning of step

The simulation works like this. The deterministic machine will try all possible weak traces. For each weak trace it will first compute the strong trace. Then, it must check whether or not the strong trace is an accepting one. It does this as follows.
Set 
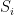
The only issue is how to compute 
Suppose that 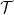
![\displaystyle [ x_{1},x_{2}] \quad \rightarrow \quad [ y_{1},y_{2},m_{1},m_{2}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B+x_%7B1%7D%2Cx_%7B2%7D%5D+%5Cquad+%5Crightarrow+%5Cquad+%5B+y_%7B1%7D%2Cy_%7B2%7D%2Cm_%7B1%7D%2Cm_%7B2%7D%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
The key question is if the machine is in state 
![\displaystyle [ s, x_{1},x_{2}] \quad \rightarrow \quad [s', y_{1},y_{2},m_{1},m_{2}].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B+s%2C+x_%7B1%7D%2Cx_%7B2%7D%5D+%5Cquad+%5Crightarrow+%5Cquad+%5Bs%27%2C+y_%7B1%7D%2Cy_%7B2%7D%2Cm_%7B1%7D%2Cm_%7B2%7D%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
That’s all there is to the simulation. The time bound is dominated by the number of weak traces which is easily seen to be 




Thus, we can actually prove more generally:
Theorem: Suppose that
-tape nondeterministic Turing machine with an alphabet of
symbols that runs in time

Open Problems
Prove the conjecture. Or failing that improve the simulation that I sketched. I think that it should be possible to prove a much better constant than the one I currently get. I think the constant can be improved easily to 



Wait, was k>1 used anywhere? Does this mean you can get c=6 for a 1-tape nondeterministic Turing machine?
Yes was used in the last step, when I count the number of traces. See the general theorem at the end of the section.
Does that really depend on k>1 though? Wouldn’t it work just as well (giving c=6) for a one-tape two-symbol machine?
Yes. Any number of tapes is fine.
The rules that you are looking for can be considered as a set of “innate logic rues” proposed initially by Chomsky and can simulated by a deterministic program.
There are five fundamental rules in this set. They are:
1. Membership rule
2. Diagonal rule
3. Class-object relation-learning rule
4. Deductive searching rule
5. Reductive searching rule
The first two rules are two axioms by Gödel. They provide the “data structure” for storing knowledge of the iterative set relations. The concept of iterative set theory was probably the foundation for Gödel to determine P=NP. The class-object relation-learning rule is almost the same as your rule in the form: [s, x1, x2,] → [s’, y1, y2, m1, m2], except the states (s and s’) are not needed. The deductive and reductive search rules take care of the states automatically by recognizing the Yes/No relations and generate the next state of the configuration. So the state machine becomes a state-free machine. The Yes/No configurations enable reducibility by the deductive and reductive search rules. The deductive search rule is to retrieve the classes of the object and the reductive rule is to retrieve the members of the class. That is, deductive and reductive search rules provide bidirectional reducibility between the two languages of the two tapes.
What is the best known separation between deterministic and non-deterministic time? The time hierarchy theorem implies that NTIME(t(n) log^2 n) strictly contains DTIME(t(n)), but do we know whether NTIME(t(n)) strictly contains DTIME(t(n))?
We know that DTIME(n) is proper in NTIME(n). This is a deep theorem that I will discuss in the future. By the way the hierarchy theorem for NTIME(t(n)) is very strong, almost any more time yields more languages. See this for a nice survey. I will also discuss all of this in the future.
We believe P is not equal to NP, but can hardly show anything at all–curious.
I don’t get it. How does this simulation that you describe not depend on the number of states of the finite state control, if your simulation compute the sets {S_i}? If I’m not mistaken, the cardinality of this set depends on the number of states of the non-deterministic Turing machine.
It does depend on the number of states S, but not in the exponent. Think of it this way: look at the logarithm of the running time of the simulations. The usual is St where t is the time of the computation. Now it is t + O(S). That is the point.
Sorry if was unclear…rjlipton
Thanks a lot for your explanation! This clears things up.
So I might still not get it… why does the following not work then? From how I understand it, it is an improvement.
Let M be the NTM running in time t(n) with tape alphabet of size a (including the blank). Also, let M have 1 tape.
A configuration is a description of the contents of the tape, followed by the position of the tape head (a binary number) followed by a state (a binary number)
The length of the tape can be assumed to be t(n), therefore a complete configuration for M has a length of at most t(n) + log t(n) + log S, with S the number of states.
The number of distinct configurations is therefore a^{t(n)} + t(n) + S.
A DTM can simulate M on input of size n as follows: Generate set C_0 which consists only of the initial configuration of M. Now generate set C_1, consisting of all the configurations that can be reached from the configuration in C_0. Continue in this way and generate C_2, …, C_{t(n)}. Next, accept only if an accepting configuration is encountered during the process.
A very crude runtime analysis:
The cardinality of each of these sets does not exceed a^{t(n)} + t(n) + S. Each configuration is of length t(n) + log t(n) + S. So I would say the runtime of this will be something like a^{t(n)} + O(t(n)) + O(S).
Am I making a mistake somewhere?
I think this is a great idea. First, the number of tapes is so you would get closer to
so you would get closer to  configurations. Second, there is the issue of how to go from what you call
configurations. Second, there is the issue of how to go from what you call  to the next
to the next  . You need to be careful here else the number of configurations due to duplicates will grow.
. You need to be careful here else the number of configurations due to duplicates will grow.
Otherwise, I like this idea.
…rjlipton
I apologize if this is posted twice. I posted it once and it did not appear to show up.
I believe I can show that there is an oracle relative to which the conjecture is false. Here is a write-up of the proof:
http://dl.getdropbox.com/u/131739/lipton-conjecture.pdf
Dear Prof. Lipton,
I guess in some sense NP-Machine hypothesis which has its roots in Resource Bounded Measure Theory says opposite to your Conjecture.
-Suresh
Iterative concept of set was another great work that Scott has done. Iterative concept of set is important. Based on it Gödel was able to foresee that “the number of steps as opposed to trial and error can be reduced from N to log N (or (log N)2).” As we know, it was Gödel who provided the first clear description of ICS in 1947.
Recently, a group of researchers including neurophysiologists, mathematicians, computer scientists and engineers at Peking University have discovered a biologically inspired knowledge structure (KS) for computation. This KS is consistent with the iterative conception of set, except KS is a continuum of mirrored iterative sets. KS enables both the deterministic and nondeterministic Turing machine to store and retrieve class-membership relations iteratively.
Three innate logic operations are embedded in KS. They are: 1) capacity of learning and storing information semantically as class-membership relations; 2) deduction capacity of retrieving class from membership; and 3) reduction capacity of retrieving membership from class. That is, the computation becomes knowledge learning and recognition in a countable domain within a countable range. Therefore, the knowledge recognition is a transition relation algorithm instead of a transition function. The time bound:
NTIME(t(n)) = DTIME(t(n))/n
As you can see, this algorithm is a pure set operation. I would be happy to describe the algorithm in greater detail.
A paper introducing this work entitled: “The fifth generation computer and its cognitive logic” has been published in Frontier Science (v. 1, 2007; in Chinese). The interesting thing is that the original objective of this research was not to investigate P/NP, but rather to understand the mechanism of the human brain. Yes-or-No questions were one of the experiments to test the KR model. Other tests were natural language processing, minimum cardinality keys, 3-SAT, and a chip simulation.
I am interested in your thoughts.
Hello.
What if, in a general theory of everything kind of way, some singular human conscious had used simple Yes(I should feel guilty) or No(I do not feel guilty) answers to answer every moral question that he could remember that had ever occurred in his life. In this way he could have become completely pure. He would have truly asked himself all the questions that could be asked of him. He would have emotionally evolved back to when he was a child.
What if he then assigned an ‘It doesn’t matter as life is only made to make mistakes’ label on every decision that he had analysed.
This would not make him God or the devil, but just very still and very exhausted. Anybody can do this but just for the purpose of this experiment lets say I have done this. Which I have.
There are no fears in me and if I died today I could deal with that because who can know me better than myself? Neither God or the Devil. I am consciously judging myself on ‘their’ level.
To make this work, despite my many faults, take ME as the ONLY universal constant. In this sense I have killed God and the Devil external to myself.The only place that they could exist is if I chose to believe they are internal.
This is obviously more a matter for a shrink more than a mathematician, but that would only be the case depending on what you believed the base operating system of the universe to be. Math / Physics / morals or some other concept.
As long I agreed to do NOTHING, to never move or think a thought, humanity would have something to peg all understanding on. Each person could send a moral choice and I would simply send back only one philosophy. ‘ LIFE IS ONLY FOR MAKING MISTAKES’.
People, for the purpose of this experiment could disbelief their belief system knowing they could go back to it at any time. It would give them an opportunity to unburden themselves to someone pure. A new Pandora’s box. Once everyone had finished I would simply format my drive and always leave adequate space for each individual to send any more thoughts that they thought were impure. People would then eventually end up with clear minds and have to be judged only on their physical efforts. Either good or bad. It would get rid of a lot of maybes which would speed lives along..
If we then assume that there are a finite(or at some point in the future, given a lot of hard work, there will be a finite amount) amount of topics that can be conceived of then we can realise that there will come to a time when we, as a people, will NOT have to work again.
Once we reach that point we will only have the option of doing the things we love or doing the things we hate as society will be completely catered for in every possible scenario. People will find their true path in life which will make them infinitely more happy, forever.
In this system there is no point in accounting for time in any context.
If we consider this to be The Grand Unified Theory then we can set the parameters as we please.
This will be our common goals for humanity. As before everyone would have their say. This could be a computer database that was completely updated in any given moment when a unique individual thought of a new idea / direction that may or may not have been thought before.
All that would be required is that every person on the planet have a mobile phone or access to the web and a self organising weighting algorithm biased on an initial set of parameters that someone has set to push the operation in a random direction.
As I’m speaking first I say we concentrate on GRAINE.
Genetics – Robotics – Artificial Intelligence – Nanotechnology and Zero Point Energy.
I have chosen these as I think the subjects will cross breed information(word of mouth first) at the present day optimum rate to get us to our finishing point, complete and finished mastery of all possible information.
Surely mastery of information in this way will lead us to the bottom of a fractal??? What if one end of the universes fractal was me??? What could we start to build with that concept???
As parameters, we can assume that we live only in 3 dimensions. We can place this box around The Milky Way galaxy as this gives us plenty of scope for all kinds of discoveries.
In this new system we can make time obsolete as it only making us contemplate our things that cannot be solved because up to now, no one has been willing to stand around for long enough. It has been holding us back.
All watches should be banned so that we find a natural rhythm with each other, those in our immediate area and then further afield.
An old clock watch in this system is should only be used when you think of an event that you need to go to. It is a compass, a modern day direction of thought.
A digital clock can be adapted to let you know where you are in relation to this new milky way boxed system.(x,y,z).
With these two types of clocks used in combination we can safely start taking small steps around the box by using the digital to see exactly where you are and then using the old watch to direct you as your thoughts come to you.
We can even build as many assign atomic clocks as are needed to individually track stars. Each and every star in the Milky Way galaxy.
I supposed a good idea would be to assume that I was inside the centre of the super-massive black hole at the centre of the galaxy. That would stop us from being so Earth centric.
We could even go as far as to say that we are each an individual star and that we project all our energies onto the super-massive black hole at the centre of the galaxy.
You can assume that I have stabilized the black hole into a non rotating perfect cube. 6 outputs /f aces in which we all see ‘the universe and earth, friends’ etc. This acts like a block hole mirror finish. Once you look it is very hard to look away from.
The 6 face cube should make the maths easier to run as you could construct the inner of the black hole with solid beams of condensed light(1 unit long) arranged into right angled triangles with set squares in for strength.
Some people would naturally say that if the universe is essentially unknowable as the more things we ‘discover’ the more things there are to combine with and therefore talk about. This is extremely fractal in both directions. There can be no true answers because there is no grounding point. Nothing for the people who are interested, to start building there own personal concepts, theories and designs on.
Is it possible that with just one man becoming conscious of a highly improbable possibility that all of universes fractals might collapse into one wave function that would answer all of humanities questions in a day? Could this be possible?
Answers to why we are here? What the point of life really is et al?
Is it possible that the insignificant possibility could become an escalating one that would at some point reach 100%???
Could it be at that point that the math would figure itself out so naturally that we would barely need to think about it. We would instantly understand Quantum theory and all.
Can anybody run the numbers on that probability?
You can easily replace the 3 in your theorem by (1+ε) for any ε>0. This is because for any NTM M using q states and a symbols that runs in time t(n), there is an NTM M’ using 3s³q states and a² symbols that runs in time t(n)/2 + O(1) and does essentially the same. By simulating M’ instead of M, you improve 3 to √3. Repeating the argument, you get arbitrarily close to 1.
The basic idea of constructing M’ is to reduce head movements by increasing the alphabet size and keeping a portion of the tape within the finite state control, thus effectively being able to do multiple steps of M in one step of M’. It effectively works as follows:
The alphabet of M’ simply consists of pairs of symbols of M. The finite state of M’ consists of a state of M, a buffer for three adjacent tape cells of M (we will use like a CPU L1 cache) and a marker that tells which of these three cells M’s head is at. The finite state control of M’ now operates as follows:
* simulate up to three steps of M’, as long as the head of M does not move out of the buffer.
* if the head moves out of the buffer, write a pair of symbols to the tape and move the head to read-in another pair of symbols from the tape in the next step.
The point is whenever we move the head of M’, the simulated head of M will be centered in the three-cell buffer after reading-in the new symbol pair. Thus, whenever we move out of the buffer in the first simulated step of M (during a step of M’), we did not move the head (of M’) after the previous step of M’, and thus simulated three steps of M during the previous step of M’. The +O(1) steps come from proper initialization of M’.
Carsten: Thank you for the comment. Your idea works. In fact, we recognized the fact that we could do something similar in spirit. We ended up using a look-up table (encoded in an extra Turing tape) instead of blowing up the states in our eventual paper. We felt that the look-up table was a cleaner idea to use than increasing the number of states based on the running time required.
Please see this post for a link to our paper on this topic.
Additions:
1. note that the cells in the buffer are not mirrored on the tape of M’, rather think of the tape of M’ as an extension of the cell buffer.
2. It should be 3a³q states, not 3s³q states, of course.
And another addition: in order to support k-tape NTM with k>1, use a buffer of 4 cells for each tape. Then, whenever one of the simulated heads of M exits its buffer it is easy to ensure that after a single write/move/read-cycle (on all tapes where it is not already the case), all simulated heads are at least one cell away from their respective buffer’s boundary, so the same argument still works. Example:
http://en.wikipedia.org/wiki/User:Carsten_Milkau/20100924_NTM_Simulation